Researchers at USC Propose Self-Attentive Pooling Method for Efficient Deep Learning
In recent years, CNN architectures have made remarkable progress in various challenging vision tasks, including semantic segmentation and object classification. Large activation maps in the initial CNN layers are taking up a lot of on-chip memory due to the continuously rising resolution of pictures acquired by current camera sensors. The pooling operation entails sliding a two-dimensional filter over each channel of the feature map and summing the features located within the region covered by the filter. Pooling layers decrease the size of the feature maps. As a result, it reduces the quantity of network computation and the number of learning parameters. Prior pooling research, however, only extracted the local context of the activation maps, which reduced their efficacy.
Several pooling operations have been proposed in the literature. The most classic functions, such as average pooling and max pooling, are naive methods that cannot extract the relevant information, especially when a rapid reduction in the size of the maps is required. More recently, other pooling operations have sprung up that try to reduce the size of maps more smartly. In this context, a Californian research team proposed a new non-local self-attentive pooling technique that can replace more traditional pooling techniques like strided convolution or max/average pooling.
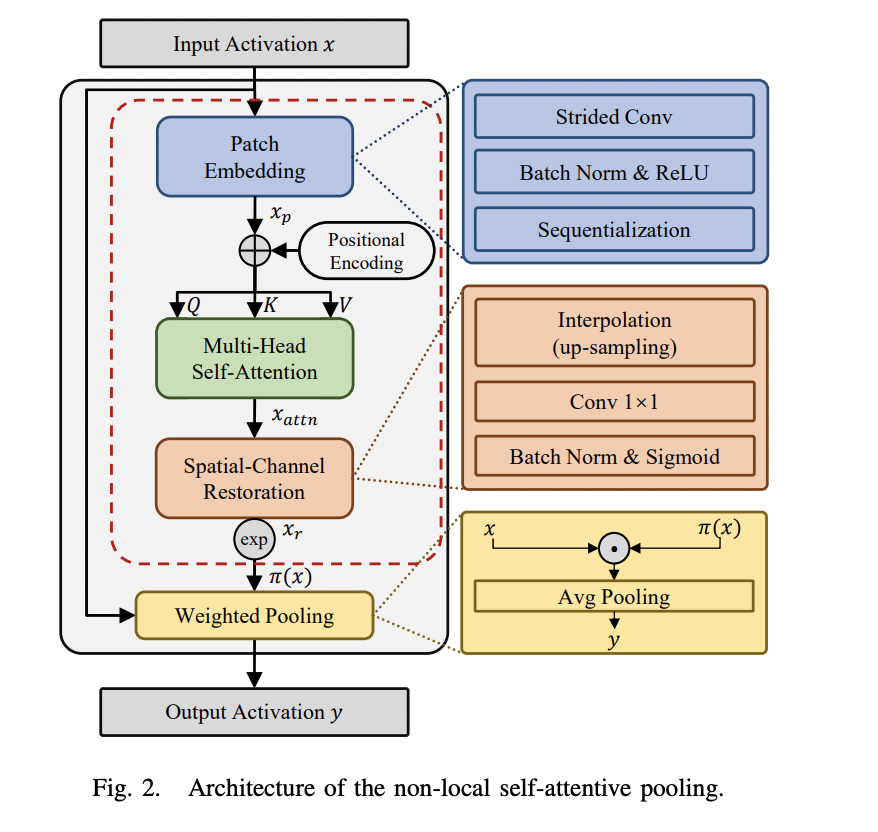
The suggested self-attentive pooling is built on a multi-head self-attention mechanism that records non-local information as self-attention maps to carry out feature down-sampling. The authors also suggested combining channel pruning and optimization of the proposed pooling strategy further to minimize the memory footprint of the whole CNN models. Four major elements comprise the new method’s overall structure: patch embedding, multi-head self-attention, spatial-channel restoration, and weighted pooling.
1 – The activation map is split into different patches, then the patch embedding is used to squeeze the spatial-channel information. A strided convolution layer is used along the channel and spatial dimensions of the input to tight and encode local features for different patches.

2 – The multi-head self-attention is used to model the long-range dependencies between the patch tokens.
3 – Based on the self-attentive token sequence, the spatial-channel restoration decodes spatial and channel information and expands the token to the original spatial resolution via bilinear interpolation.
4 – The weighted pooling is implemented to create the down-sampled output feature map from the output of the spatial-channel restoration block.
To evaluate the performance of the method proposed in this article, the authors conducted an experimental study using two networks as backbones, which are MobileNetv2 and ResNet18. A qualitative study showed that, compared to other state-of-the-art methods, the proposed approach focuses more on the details of an image and the long-range dependencies between different local regions. In addition, the evaluation proved that Compared to the existing pooling approaches with famous memory-efficient CNN backbones, the proposed method is more efficient on several object recognition and detection benchmarks.
In this article, we presented a new self-attention pooling proposed by a Californian research team that aggregates non-local features from activation maps, allowing the extraction of more complex relationships between different features compared to existing local pooling layers. Compared to existing techniques, self-attention pooling achieves higher inference accuracy with iso-memory footprints. It may also be used in memory-limited systems, such as microcontrollers, without significantly compromising accuracy.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Self-Attentive Pooling for Efficient Deep Learning'. All Credit For This Research Goes To Researchers on This Project. Check out the paper. Please Don't Forget To Join Our ML Subreddit
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.