Researchers Build On Splade Technique For Enhancing Sparse Neural IR Models
This Article Is Based On The Research Paper 'From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective'. All Credit For This Research Goes To The Researchers 👏👏👏 Please Don't Forget To Join Our ML Subreddit
With so much data being created every second, we must have the tools to retrieve it. Google has a staggering 50 billion web pages indexed. When we conduct a google search, we never consider how difficult the task is. In the past few decades, information retrieval systems were built on BM25, a ranking function where BM stands for Best Match. To retrieve information efficiently, these systems used lexical matching and inverted indices. BM25 is often biassed toward a higher frequency of query terms.
With the introduction of Pre-Trained Language Models such as BERT, information retrieval saw a fundamental paradigm change toward contextualized semantic matching, where neural retrievers can combat the long-standing vocabulary mismatch problem. In BERT, the language model has been trained by predicting 15% of the tokens in the chosen input. These tokens are pre-processed in the following manner: 80% are replaced with a “[MASK]” token, 10% with a random word, and 10% with the original word. Despite their excellent in-domain performance, generalizing BERT models have shown their efficacy is lower than BM25.
Sparse representations have advantages over dense alternatives, including efficient use of the inverted index, explicit lexical matching, and interpretability. This sparked a rising interest in returning to lexical space through sparse representations and inverted indexing techniques that rely on a term-importance component and a term-expansion mechanism. These models have demonstrated high generalization ability. It is unclear how these models might benefit from the same advantages as dense designs due to their sparsity.

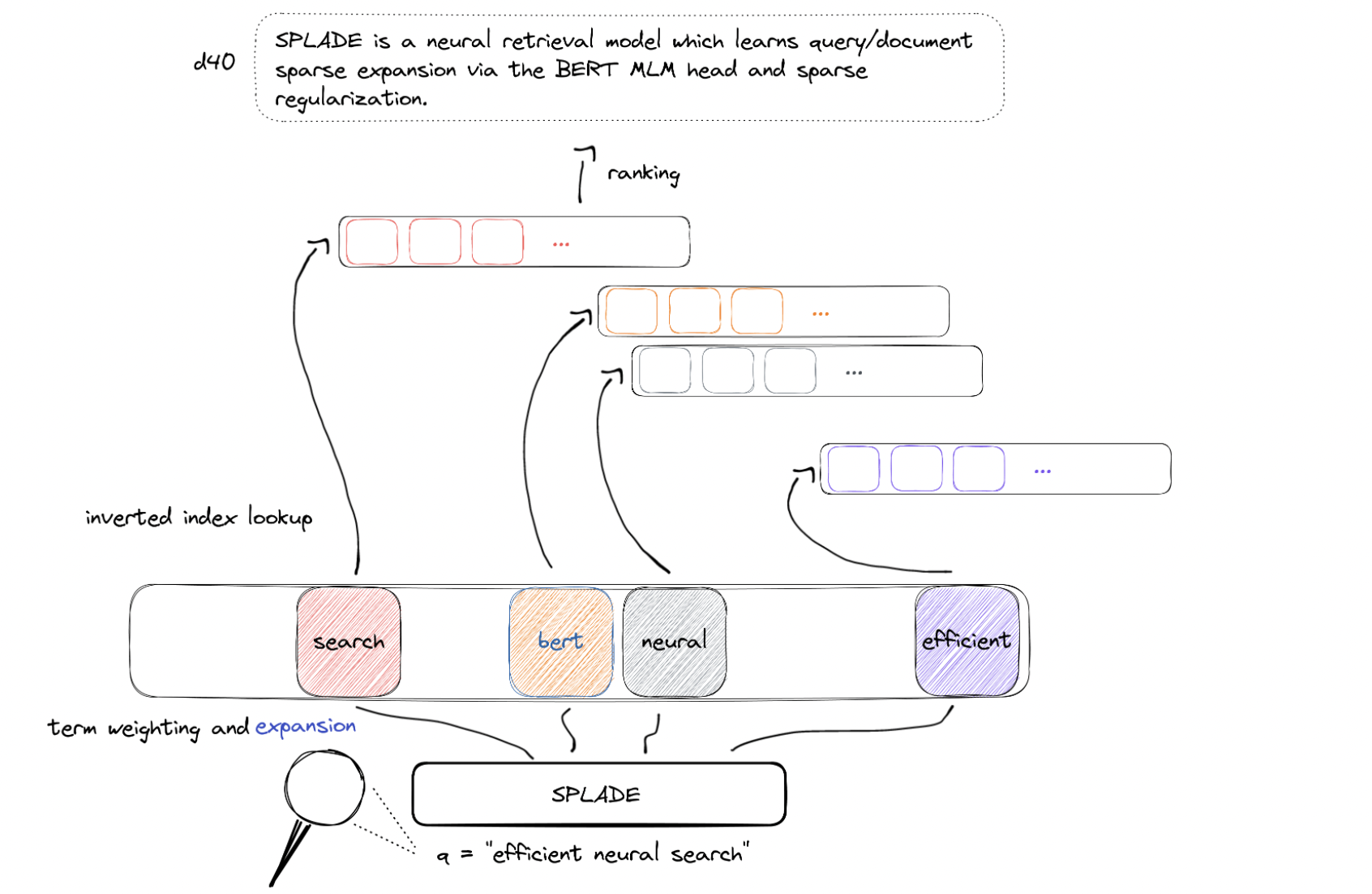
They also appear to be better at generalizing on data that is not in their domain. One such expansion-based sparse retrieval model that predicts term significance is SPLADE. SPLADE can be enhanced by employing training enhancement strategies such as distillation and hard negative mining tactics. Distillation has been demonstrated to increase the efficacy of many neural ranking algorithms significantly. To rank search results in response to a query, neural ranking models for information retrieval (IR) employ shallow or deep neural networks. More recently suggested neural models, on the other hand, develop representations of language from raw text and can bridge the gap between query and document vocabulary.
As data grows, these new information retrieval techniques are becoming increasingly important. In contrast to classic learning to rank models and non-neural techniques of IR, these new ML algorithms are data-hungry, requiring large-scale training data before implementation. The SPLADE model training, indexing, and retrieval code is freely accessible on GitHub.
Paper: https://arxiv.org/pdf/2205.04733v1.pdf
Github: https://github.com/naver/splade
References:
Credit: Source link
Comments are closed.