Researchers Develop A Unified Framework For Evaluating Natural Language Generation (NLG)

Natural language generation (NLG) is a broad term that encompasses a variety of tasks that generate fluent text from input data and other contextual information. In actuality, the goals of these jobs are frequently very different. Some well-known instances of NLG include compressing a source article into a brief paragraph conveying the most significant information, converting content presented in one language into another, and creating unique responses to drive the discourse.
Natural language processing has advanced at a breakneck pace in terms of enhancing and developing new models for various jobs. However, assessing NLG remains difficult: human judgment is considered the gold standard, but it is typically costly and time-consuming to get. Automatic evaluation, on the other hand, is scalable, but it’s also time-consuming and challenging. This problem originates because each work has varied quality requirements, making it difficult to establish what to assess and how to measure it.
Previously, a variety of evaluation measures based on specific intuitions for various tasks and aspects were devised. However, a more general theoretical basis is required to reason about what to assess and how to evaluate a particular activity. It makes it easier to share evaluation ideas and approaches across a variety of NLG challenges, which can lead to better metric design recommendations for new domains.
Researchers from Carnegie Mellon University, Petuum Inc., MBZUAI and UC San Diego recently took a step in this direction by developing a single framework for NLG evaluation that makes it easier to create metrics for various language generation tasks and characteristics.
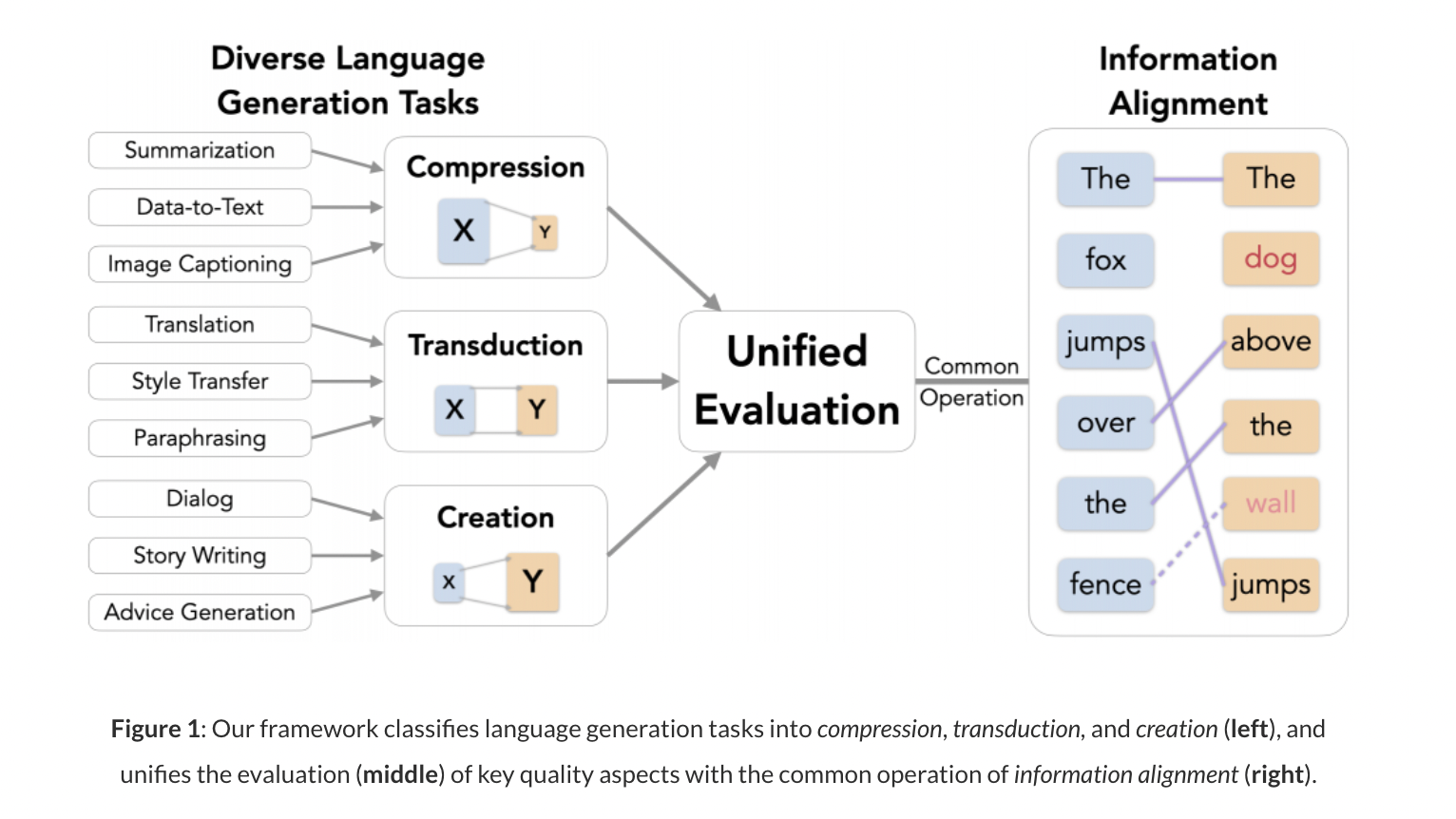
The framework divides NLG tasks into categories based on how information changes from input to output. Each category necessitates its own set of priorities and desirable output characteristics. The information alignment, or overlap, between generation components is crucial in determining the generated text’s quality. In terms of a unified idea of information alignment, a family of evaluation metrics for various NLG tasks is developed.
These measurements are simple to understand and analyze, and they don’t always require gold human references. Alignment estimation is defined as a prediction challenge to operationalize these measures, and many strategies to accomplish it are proposed. The framework’s benefits include improvements in a single alignment estimate model that can benefit a wide range of metrics established within the framework right away. Experiments indicate that the framework’s metrics outperform or compete with state-of-the-art metrics in a variety of tasks, including text summarization, style transfer, and knowledge-grounded dialogue.
On the input, an NLG task might be thought of as compression, Transduction, or creation. Each category implies different operations, requirements, and assessment intuitions. Compression refers to Expressing salient information in concise text; Transduction refers to Transforming text while preserving content precisely and, Creation refers to Producing new content based on input and context.
The unified framework provides systematic direction for new aspects and metric task design and opens up interesting new possibilities for composable NLG evaluation. We may break the process into modular components that can be improved, scaled, and diagnosed independently, using the more rigorous software engineering techniques. Compared to existing state-of-the-art metrics, the uniformly developed metrics help create superior or equivalent human correlations and provide answers to various difficulties.
Paper: https://arxiv.org/pdf/2109.06379.pdf
Code: https://github.com/tanyuqian/ctc-gen-eval
CMU Blog: https://blog.ml.cmu.edu/2021/10/29/compression-transduction-and-creation-a-unified-framework-for-evaluating-natural-language-generation/
Suggested
Credit: Source link
Comments are closed.