Researchers from Alibaba Propose INSTAG: An Open-Set Fine-Grained Tagger that Leverages the Instruction Following Ability of Modern Chatbots like ChatGPT
Have you ever considered how large language models like ChatGPT would obtain the instruction-following ability? Various foundation language models obtain it through supervised fine-tuning ( SFT ). The critical factor for the success of SFT is the diversity and complexity of the datasets. Their qualitative analysis and definitions need to be more clear.
Researchers at Alibaba DAMO Academy propose an open-set fine-grained tagger called “InsTag” to tag samples within the SFT dataset based on semantics and intentions to define instruction diversity and complexity regarding tasks. They claim that model ability grows with more complex and diverse data.
Researchers also propose a data selector based on InsTag to select 6K diverse and complex samples from open-source datasets and fine-tune models on InsTag-selected data. They claim that a large range of training data covering various semantics and specialties is crucial for well-aligned LLMs with human expectations that can precisely recognize human intentions and properly formalize responses in natural languages.
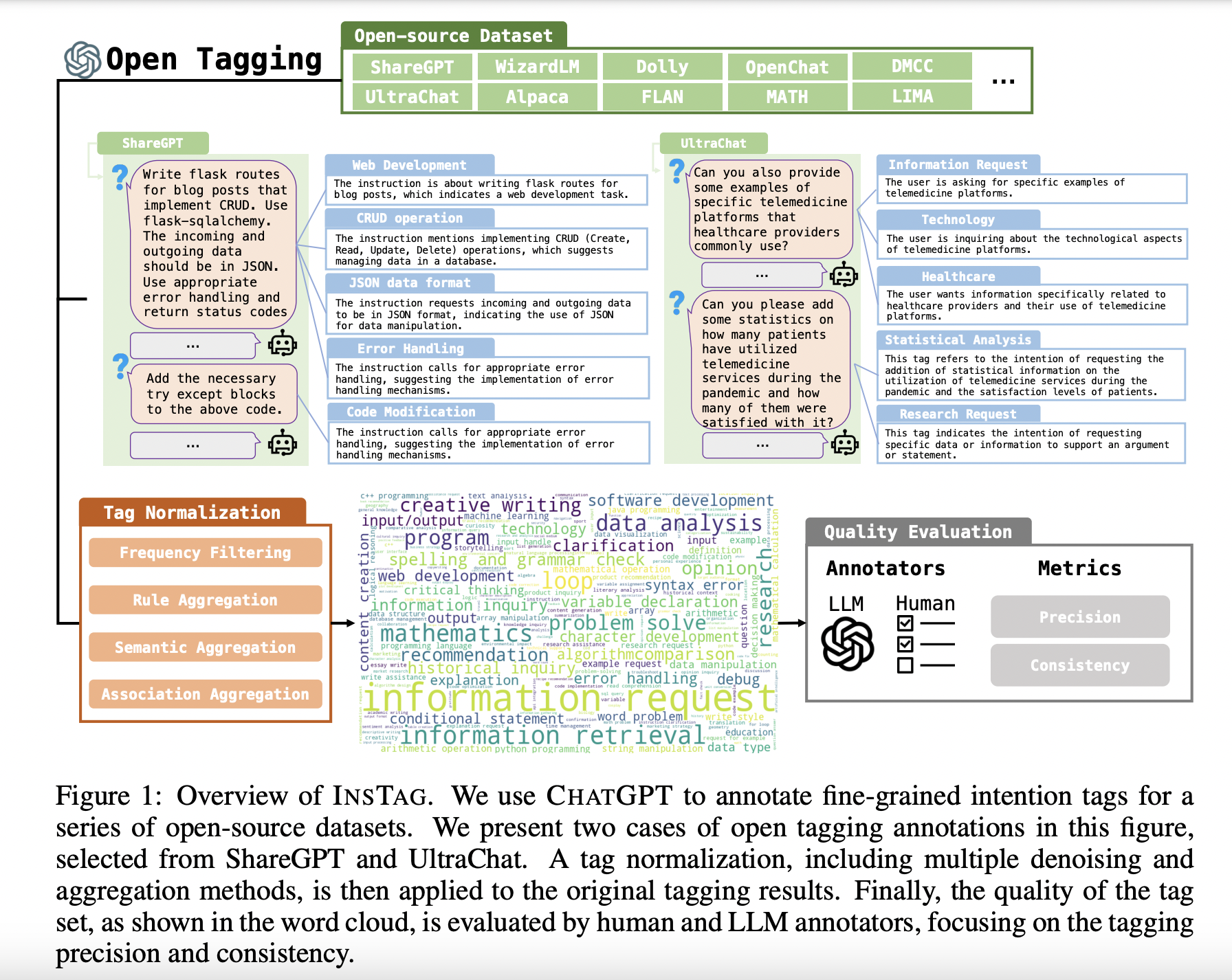
InsTag is an automatic Instruction Tagging method empowered by the high-performing chatbot ChatGPT. It is a framework that automatically prompts ChatGPT to assign tags to queries. ChatGPT uses a systematic tag normalization technique to explain each assigned tag. When InsTag is applied to existing open-source datasets, it builds open-set, fine-trained tags, which are further detailed and analyzed to obtain distributions based on complexity and diversity. LLMs finetuned with the data selected by the InsTag selector perform better on the MIT-Benchmark.
When trying to generate intention tags using ChatGPT, researchers identified three types of noises. Due to the instability of ChatGPT in adhering to output format instructions, Lexical Noise was produced. The tags that are over-specific create uncontrolled granularity, leading to noise. Some tags often appeared together due to the bias of ChatGPT and lead to spurious correlations.
To resolve these, they normalize open-set tagging results using various aspects like format, semantics, and associations. They first filter out long-tail tags that appear less than a particular set parameter ( called hyperparameter, which is related to the scale of the dataset). All the tags were transformed into lower characters to avoid the influence of capital letters. Finally, they apply stemming to each tag. Stemming is a technique used to extract the base form of words by removing affixes from them.
Researchers chose the 13B version of LLaMA for fine-tuning and other similar LLMs for comparison. Their results show that their models outperform all the open-source aligned LLMs upon achieving a 6.44 average score on the MIT-Bench.
In summary, researchers say that their proposed InsTag provides a novel aspect for a deeper understanding of query distribution in the alignment of LLMs. It has a robust potential to be extended to more applications beyond the data selection, such as comprehensive evaluations and tag-based self-instruct.
Check out the Paper, GitHub, and Try it here. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.