Researchers from Allen Institute for AI Introduce VISPROG: A Neuro-Symbolic Approach to Solving Complex and Compositional Visual Tasks Given Natural Language Instructions
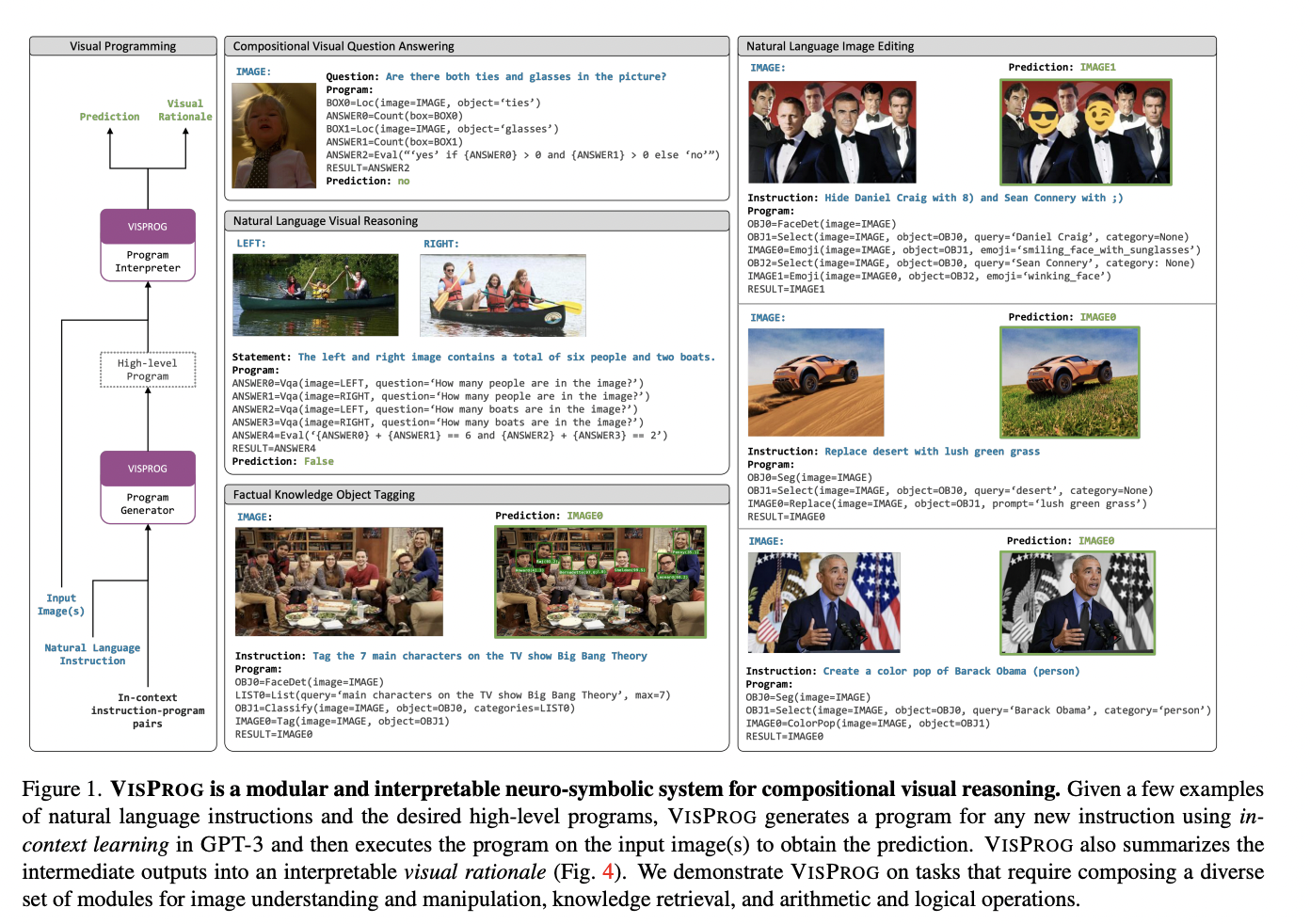
The search for general-purpose AI systems has facilitated the development of capable end-to-end trainable models, many of which aim to provide a simple natural language interface for a user to engage with the model. Massive-scale unsupervised pretraining followed by supervised multitask training has been the most common method for developing these systems. They eventually want these systems to execute to scale to the indefinitely long tail of difficult jobs. However, this strategy needs a carefully selected dataset for each task. By breaking down difficult activities stated in natural language into simpler phases that can be handled by specialized end-to-end trained models or other programs, they study the usage of big language models to handle the long tail of complex tasks in this work.
Tell a computer vision program to “Tag the seven main characters from the TV show Big Bang Theory in this image.” The system must first comprehend the purpose of the instruction before carrying out the following steps: detecting faces, retrieving the list of Big Bang Theory’s main characters from a knowledge base, classifying faces using the list of characters, and tagging the image with the names and faces of the characters that were recognized. While several vision and language systems can carry out each task, natural language task execution is outside the purview of end-to-end trained systems.

Researchers from Allen Institute for AI propose VISPROG, a program that takes as input visual information (a single picture or a collection of images) and a natural language command, creates a series of instructions, or a visual program, as they can be called, and then executes these instructions to produce the required result. Each line of a visual program calls one of the many modules the system now supports. Modules can be pre-built language models, OpenCV image processing subroutines, or arithmetic and logical operators. They can also be pre-built computer vision models. The inputs created by running earlier lines of code are consumed by modules, producing intermediate outputs that can be used later.
In the example mentioned earlier, a face detector, GPT-3 as a knowledge retrieval system, and CLIP as an open-vocabulary image classifier are all used by the visual program created by VISPROG to provide the necessary output (see Fig. 1). The generation and execution of programs for vision applications are both enhanced by VISPROG. Neural Module Networks (NMN) combine specialized, differentiable neural modules to create a question-specific, end-to-end trainable network for the visual question answering (VQA) problem. These methods either train a layout generator using REINFORCE’s weak answer supervision or brittle, pre-built semantic parsers to generate the layout of modules deterministically.
In contrast, VISPROG allows users to build complicated programs without prior training using a potent language model (GPT-3) and limited in-context examples. Invoking trained state-of-the-art models, non-neural Python subroutines, and greater levels of abstraction than NMNs, VISPROG programs are likewise more abstract than NMNs. Due to these benefits, VISPROG is a quick, effective, and versatile neuro-symbolic system. Additionally, VISPROG is very interpreted. First, VISPROG creates simple-to-understand programs whose logical accuracy may be checked by the user. Second, by breaking the prediction down into manageable parts, VISPROG enables the user to examine the results of intermediate phases to spot flaws and, if necessary, make corrections to the logic.
A completed program with intermediate step outputs (such as text, bounding boxes, segmentation masks, produced pictures, etc.) connected to show the flow of information serves as a visual justification for the prediction. They employ VISPROG for four distinct activities to show off its versatility. These tasks involve common skills (such as picture parsing) but also require specialized thinking and visual manipulation skills. These tasks include:
- Answering compositional visual questions.
- Zero-shot NLVR on picture pairings.
- Factual knowledge object labeling from NL instructions.
- Language-guided image manipulation.
They stress that none of the modules or the language model have been altered in any manner. It takes a few in-context examples with natural language commands and the appropriate programs to adapt VISPROG to any task. VISPROG is simple to use and has substantial gains over a base VQA model on the compositional VQA test of 2.7 points, good zero-shot accuracy on NLVR of 62.4%, and pleasing qualitative and quantitative results on knowledge tagging and picture editing tasks.
Check Out The Paper, Github, and Project Page. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.