Researchers from Apple Unveil DataComp: A Groundbreaking 12.8 Billion Image-Text Pair Dataset for Advanced Machine Learning Model Development and Benchmarking
Multimodal datasets, which combine various data types, such as images and text, have played a crucial role in advancing artificial intelligence. These datasets enable AI models to understand and generate content across different modalities, leading to significant progress in image recognition, language comprehension, and cross-modal tasks. As the need for comprehensive AI systems increases, exploring and harnessing the potential of multimodal datasets has become essential in pushing the boundaries of machine learning capabilities. Researchers from Apple and the University of Washington have introduced DATACOMP, a multimodal dataset testbed that contains 12.8 billion pairs of images and text data from Common Crawl.
Classical research focuses on enhancing model performance through dataset cleaning, outlier removal, and coreset selection. Recent efforts in subset selection operate on smaller curated datasets, not reflecting noisy image-text pairs and large-scale datasets in modern training paradigms. Existing benchmarks for data-centric investigations are limited compared to larger datasets like LAION-2B. Previous work highlights the benefits of dataset pruning, deduplication, and CAT filtering for image-text datasets. Challenges arise due to the proprietary nature of large-scale multimodal datasets, hindering comprehensive data-centric investigations.
Recent strides in multimodal learning, impacting zero-shot classification and image generation, rely on large datasets like CLIPs (400 million pairs) and Stable Diffusions (two billion from LAION-2B). Despite their significance, little is known about these proprietary datasets, often treated without detailed investigation. DATACOMP addresses this gap, serving as a testbed for multimodal dataset experiments. DATACOMP enables researchers to design and evaluate new filtering techniques, advancing understanding and improving dataset design for multimodal models.
DATACOMP is a dataset experiment testbed featuring 12.8 billion image-text pairs from Common Crawl. Researchers design and evaluate new filtering techniques or data sources by using standardized CLIP training code and testing on 38 downstream sets. ViT architecture, selected for its favorable CLIP scaling trends over ResNets, is employed in experiments. Medium-scale experiments involve substituting the ViT-B32 architecture with a ConvNeXt model. DATACOMP facilitates innovation and evaluation in multimodal dataset research, enhancing understanding and refining models for improved performance.
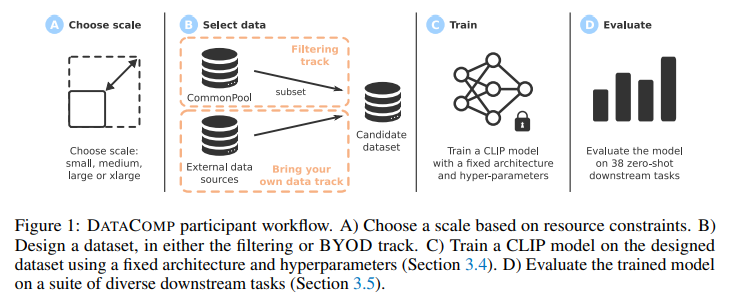
DATACOMP’s workflow yields superior training sets, with DATACOMP-1B achieving a 3.7 percentage point improvement over OpenAI’s CLIP ViT-L/14 in zero-shot accuracy on ImageNet (79.2%). Utilizing the same training procedure and computation showcases the efficacy of DATACOMP. The benchmark encompasses diverse compute scales, facilitating the study of scaling trends across four orders of magnitude and accommodating researchers with varying resources. The expansive image-text pair pool, COMMONPOOL, derived from Common Crawl, proves valuable for dataset experiments, enhancing accessibility and contributing to advancements in multimodal learning.
In conclusion, the research can be summarized in the following points:
- DATACOMP is a dataset experiment testbed.
- The platform features a pool of 12.8 billion image-text pairs from Common Crawl.
- Researchers can use this platform to design filtering techniques, curate data, and assess datasets.
- Standardized CLIP training with downstream testing is used to evaluate the datasets.
- This benchmark facilitates studying scaling trends across varying resources and compute scales.
- DATACOMP-1B, the best baseline, surpasses OpenAI’s CLIP ViT-L/14 by 3.7 percentage points in zero-shot accuracy on ImageNet.
- DATACOMP and its code are released for widespread research and experimentation.
Check out the Paper, Code, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.