Researchers From ByteDance Introduce MetaFormer: A Unified Meta Framework for Fine-Grained Recognition That Achieves 92.3% and 92.7% on CUB-200-2011 and NABirds

Fine-grained visual classification, in contrast to generic object classification, tries to correctly classify things from the same basic category (birds, vehicles, etc.) into subcategories. Because of the modest inter-class variances and high intra-class variations, Fine-Grained Visual Classification (FGVC) has long been regarded as a difficult assignment.
The most common FGVC techniques, such as the part-based model and the attention-based model, are primarily focused on how to get the network to focus on the most discriminative regions. The inductive bias of localization is introduced to neural networks with elaborate structure, inspired by human observation behavior.
Furthermore, when some species are virtually indistinguishable, human specialists frequently rely on information other than vision to help them classify them. In the age of information explosion, fine-grained recognition data is multisource heterogeneous. As a result, the neural network completing fine-grained classification tasks solely with visual information is illogical.
Fine-grained classification, which is more difficult to discern visually, relies on orthogonal signals more than coarse-grained classification in practice. Previous research has used extra information to aid fine-grained categorization, such as Spatio-temporal priors and text descriptions. The design of these works for supplementary information, on the other hand, is distinctive and not universal. This motivates us to create a consistent yet effective strategy for flexibly utilizing various meta-information.
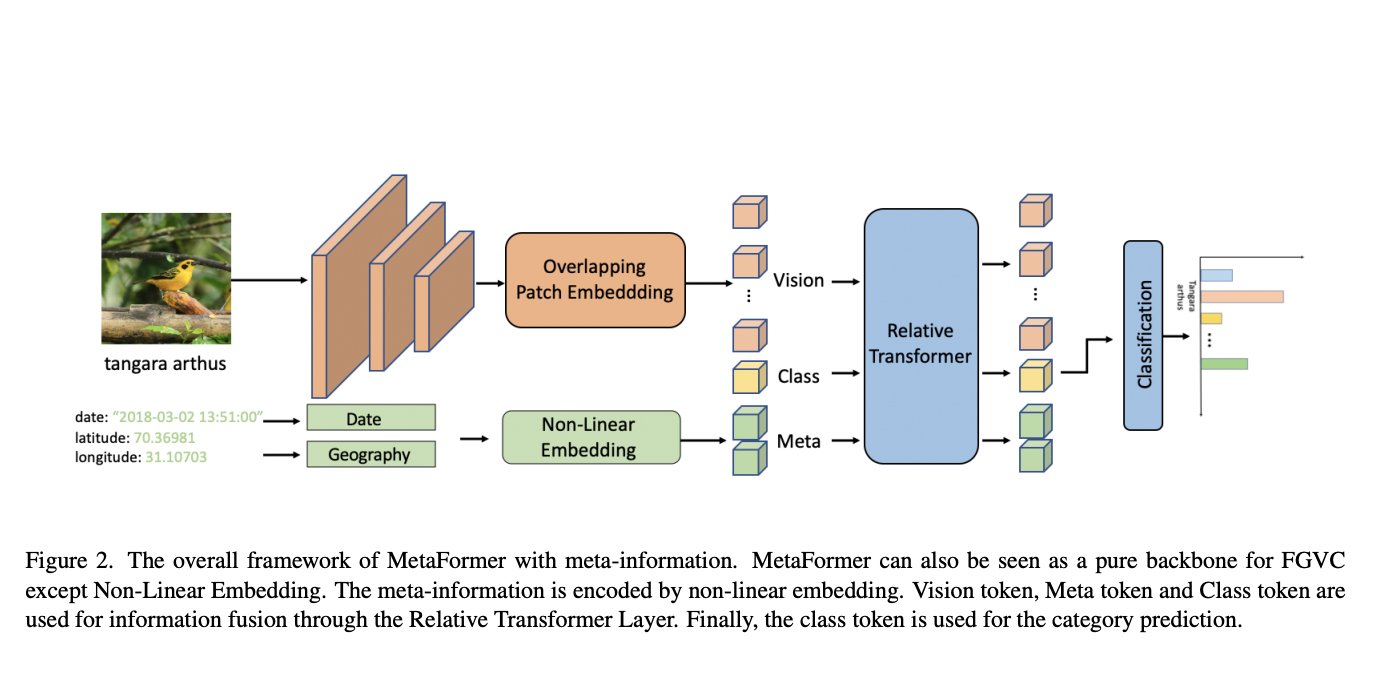
Vision Transformer (ViT) demonstrates that a pure transformer applied directly to image patch sequences can perform exceptionally well on image categorization tasks. Intuitively, it seems possible to use both the vision token and the meta token as the transformer’s input for FGVC. However, it is yet unclear whether the model’s performance is harmed when the several modalities interfere with one another.
To address this issue, ByteDance researchers introduce MetaFormer, which combines vision with meta-information using a transformer. With the help of meta-information, MetaFormer may effectively increase the accuracy of FGVC. MetaFormer can alternatively be thought of as a hybrid structural backbone, with the convolution downsampling the image and introducing the convolution’s inductive bias and the transformer fusing visual and meta-information. MetaFormer also provides a robust baseline for FGVC without the bells and whistles in this way.
Recent improvements in image classification show that large-scale pre-training can successfully increase both coarse-grained and fine-grained classification accuracy. However, most current FGVC algorithms need ImageNet-1k for pre-training, which limits further research into fine-grained recognition.
Researchers can further investigate the influence of the pre-trained model thanks to MetaFormer’s simplicity, which can provide references to researchers interested in the pre-trained model. The accuracy of fine-grained recognition can be considerably improved using large-scale pretrained models. Surprisingly, MetaFormer can achieve SotA performance on various datasets utilizing the largescale pre-trained model without incorporating any priors for fine-grained tasks.

Convolution is utilized for encoding vision information in MetaFormer, whereas the transformer layer is used to combine vision and meta information. The team builds a five-stage network using canonical ConvNet. The input size lowers at the start of each stage to allow for the arrangement of varying scales. A simple three-layer convolutional stem is used in the initial stage. In addition, the next two phases are squeeze-excitation MBConv blocks. In the final two stages, the team uses Transformer blocks with relative position bias.
ImageNet image classification is used by researchers, and it provides pre-trained models for fine-grained classification. On iNaturalist 2017, iNaturalist 2018, iNaturalist 2021, and CUB-200-2011, they test the framework’s usefulness for adding meta-information. They also put the proposed framework through its paces on a number of well-known fine-grained benchmarks, including Stanford Cars, Aircraft, and NABirds.
MetaFormer can obtain 92.3 percent and 92.7 percent on CUB-200-2011 and NABirds, respectively, without any inductive bias of fine-grained visual categorization tasks, exceeding SotA techniques. In a fair comparison, MetaFormer can likewise accomplish SotA performance (78.2 percent and 81.9 percent) using only vision information on iNaturalist 2017 and iNaturalist 2018.
Conclusion
ByteDance researchers propose a unified meta-framework for fine-grained visual classification in this paper. MetaFormer uses the transformer to combine visual and meta-information without adding any new structure. In the meanwhile, MetaFormer provides a basic but effective FGVC baseline. They also looked at the effects of various pre-training models on fine-grained tasks in a systematic way. On the iNaturalist series, CUB-200-2011, and NABirds datasets, MetaFormer achieves SotA performance. Meanwhile, the researchers predict that meta-data will become increasingly crucial for fine-grained recognition tasks in the future. MetaFormer can also be used to make use of other supplementary data.
Paper: https://arxiv.org/pdf/2203.02751v1.pdf
Github: https://github.com/dqshuai/metaformer
Suggested
Credit: Source link
Comments are closed.