Researchers from Caltech and ETH Zurich Introduce Groundbreaking Diffusion Models: Harnessing Text Captions for State-of-the-Art Visual Tasks and Cross-Domain Adaptations
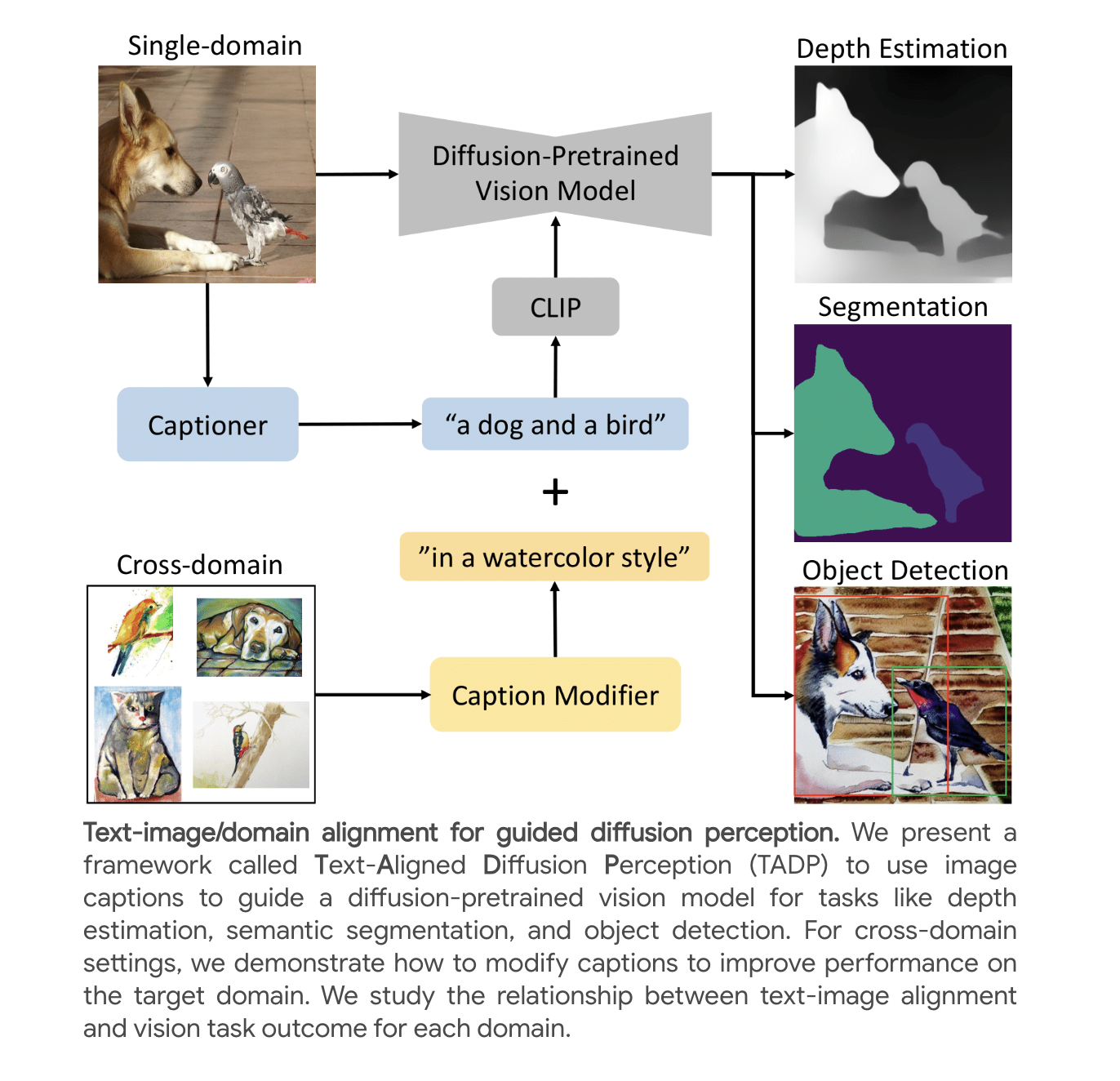
Diffusion models have revolutionized text-to-image synthesis, unlocking new possibilities in classical machine-learning tasks. Yet, effectively harnessing their perceptual knowledge, especially in vision tasks, remains challenging. Researchers from CalTech, ETH Zurich, and the Swiss Data Science Center explore using automatically generated captions to enhance text-image alignment and cross-attention maps, resulting in substantial improvements in perceptual performance. Their approach sets new benchmarks in diffusion-based semantic segmentation and depth estimation, even extending its benefits to cross-domain applications, demonstrating remarkable results in object detection and segmentation tasks.
Researchers explore the use of diffusion models in text-to-image synthesis and their application to vision tasks. Their research investigates text-image alignment and the use of automatically generated captions to enhance perceptual performance. It delves into the benefits of a generic prompt, text-domain alignment, latent scaling, and caption length. It also proposes an improved class-specific text representation approach using CLIP. Their study sets new benchmarks in diffusion-based semantic segmentation, depth estimation, and object detection across various datasets.
Diffusion models have excelled in image generation and hold promise for discriminative vision tasks like semantic segmentation and depth estimation. Unlike contrastive models, they have a causal relationship with text, raising questions about text-image alignment’s impact. Their study explores this relationship and suggests that unaligned text prompts can hinder performance. It introduces automatically generated captions to enhance text-image alignment, improving perceptual performance. Generic prompts and text-target domain alignment are investigated in cross-domain vision tasks, achieving state-of-the-art results in various perception tasks.
Their method, initially generative, employs diffusion models for text-to-image synthesis and visual tasks. The Stable Diffusion model comprises four networks: an encoder, conditional denoising autoencoder, language encoder, and decoder. Training involves a forward and a learned reverse process, leveraging a dataset of images and captions. A cross-attention mechanism enhances perceptual performance. Experiments across datasets yield state-of-the-art results in diffusion-based perception tasks.
Their approach presents an approach that surpasses the state-of-the-art (SOTA) in diffusion-based semantic segmentation on the ADE20K dataset and achieves SOTA results in depth estimation on the NYUv2 dataset. It demonstrates cross-domain adaptability by achieving SOTA results in object detection on the Watercolor 2K dataset and SOTA results in segmentation on the Dark Zurich-val and Nighttime Driving datasets. Caption modification techniques enhance performance across various datasets, and using CLIP for class-specific text representation improves cross-attention maps. Their study underscores the significance of text-image and domain-specific text alignment in enhancing vision task performance.
In conclusion, their research introduces a method that enhances text-image alignment in diffusion-based perception models, improving performance across various vision tasks. The approach achieves results in tasks such as semantic segmentation and depth estimation utilizing automatically generated captions. Their method extends its benefits to cross-domain scenarios, demonstrating adaptability. Their study underscores the importance of aligning text prompts with images and highlights the potential for further improvements through model personalization techniques. It offers valuable insights into optimizing text-image interactions for enhanced visual perception in diffusion models.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.