Researchers From Cambridge And Amazon Propose ‘TRANS-ENCODER’: An Unsupervised Approach of Training Bi- And Cross-Encoders For Sentence-Pair Tasks
This Article Is Based On The Research Article 'TRANS-ENCODER: UNSUPERVISED SENTENCE-PAIR MODELLING THROUGH SELF- AND MUTUAL-DISTILLATIONS'. All Credit For This Research Goes To The Researchers Of This Paper 👏👏👏 Please Don't Forget To Join Our ML Subreddit
Several natural language processing and information retrieval tasks, such as textual entailment, paraphrase identification, etc., rely on pairwise sentence comparison. The most frequently accepted approach to sentence comparison is cross-encoding, which involves mapping sentences against each other on a pair-by-pair basis. However, significant amounts of annotated data are necessary to train these cross-encoders, which is a significant drawback due to their time-consuming nature.
This stumbling block paved the path for research into how to train entirely unsupervised models for sentence-pair tasks without using data annotation. Trans-encoder is a completely unsupervised sentence-pair model developed by Amazon Research experts. The corresponding research paper was also presented at this year’s International Conference on Learning Representations (ICLR), demonstrating how the model could attain 5% greater sentence similarity than previous state-of-the-art models.
Cross encoders are developed on top of Transformer-based language models wherein concatenated sentences are sent in a single pass to the sentence pair model. Because the attention heads can directly represent which aspects of one sequence correlate with which elements of the other, these Transformers help determine an accurate relevance score. However, as a new encoding is produced for each pair of input sentences, this technique is computationally expensive and of limited utility in NLP applications like information retrieval and clustering, which require large-scale pairwise sentence comparisons.


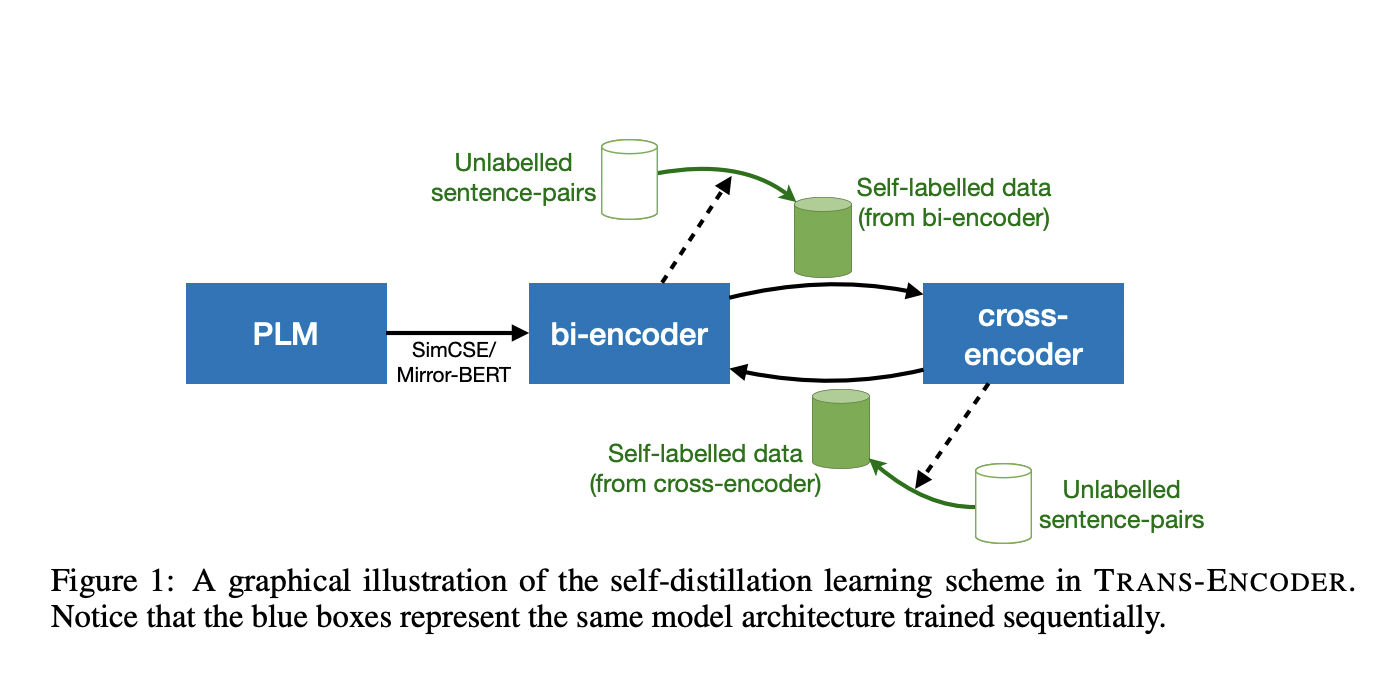
A bi-encoder, unlike a cross-encoder, encodes each phrase separately and maps it to a shared embedding space. Bi-encoding is substantially more efficient than cross-encoding since the encoded sentences can be cached and reused. On the other hand, Bi-encoders underperform cross-encoders in supervised learning since they do not explicitly model the interactions between phrases. Nowadays, there is a predicament in choosing between the models mentioned above for sentence-pair tasks. However, these can be resolved based on a trade-off between computational efficiency and performance.
The trans-encoder was developed to combine the benefits of both bi- and cross-encoders to create an accurate sentence-pair model in an unsupervised way. The researchers chose a cross-encoder as the primary model due to its robust inter-sentence modeling capabilities, which can assist in extracting more knowledge from PLMs than bi-encoders. On the other hand, the bi-encoder representations are then utilized to fine-tune the cross-encoder outputs. The trans-encoder training process can be summarised as a three-step process. An unsupervised bi-encoder generates training targets for a cross-encoder, whose outputs are subsequently transferred back into a bi-encoder. By bootstrapping from both the bi- and cross-encoders, this cycle is repeated to enhance the accuracy of the more computationally viable model.
The study also discusses several strategies that may be useful in increasing the model’s performance. Even sentence textual similarity (STS) benchmarks were used to assess the final trans-encoder model, and the team found considerable improvements over earlier unsupervised sentence-pair models across all datasets.
Paper: https://openreview.net/pdf?id=AmUhwTOHgm
Source: https://www.amazon.science/blog/improving-unsupervised-sentence-pair-comparison
Credit: Source link
Comments are closed.