Researchers From China Introduce A Re-Attention Method Called The Token Refinement Transformer (TRT) That Captures Object Level Semantics For The Task of WSOL
Object localization, a fundamental computer vision task, is crucial to many computer vision-based applications. While supervised approaches use manual location labels to learn to localize the objects directly, the accuracy of localization is affected by incomplete or improperly assigned location labels, and the cost of manual labeling should also be relatively high. In the Computer Vision community, weakly-supervised object localization (WSOL), which uses image-level labels, is a well-established and challenging task. Deep neural networks’ effectiveness in object detection has brought WSOL increasing attention.
Several approaches have been proposed in the deep learning era for the WSOL task. Some methods use the class activation map (CAM) technique for localization. Though CAM-based approaches are end-to-end and practical, they tend to detect the most discriminative parts of the object. More recently, with the emergence of vision transforms and their promising performance, some works have been interested in using it for the WSOL task. However, background noise is unavoidably introduced because vision transformers create tokens by slitting an image into many ordered patches and computing global relations between tokens.
To address this problem, researchers from china suggest a re-attention technique based on the token refinement transformer (TRT).
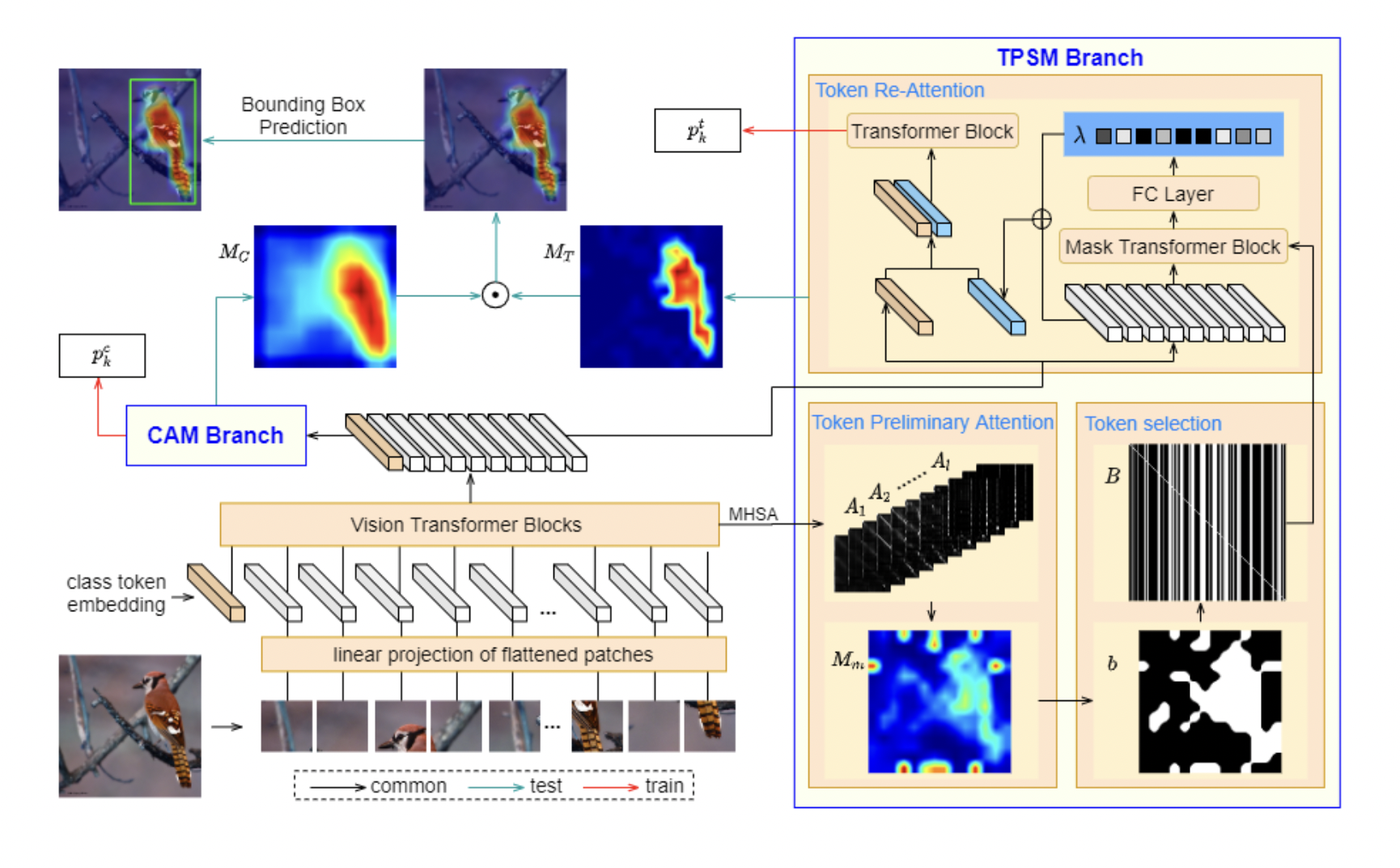
The network introduced in this paper consists of a vision transformer module, the Deit-Base pre-trained on ImageNet-1K, followed by two branches. The first branch is the Token Priority Scoring Module (TPSM), which targets to remove the irreverent background response to highlight the objective regions. TPSM aspires to re-attention patch tokens with a novel adaptive thresholding strategy. More in detail, this branch is composed of three components. A preliminary attention map is generated at the first stage based on the long-range dependencies of class tokens and patch tokens over transformer blocks. In the second stage, an adaptive thresholding strategy is applied to screen out patch tokens with high responses in the preliminary attention map. In the final step, a re-attention operation is applied to the selected tokens to detect more relevant global relationships. On the other hand, the second branch of the proposed network aims to calculate the standard class activation map. The operation of the network is as follows. First, the input image is divided into several non-overlapping parts and passed through the transformer. The output of the transformer is then supplied to both branches. After that, the widely utilized cross-entropy loss is used during training to evaluate the similarity between the output and ground truth in both branches. The AutoAugment technique is also used in the training step to ensure data augmentation.
The evaluation of the proposed approach is carried out on two public datasets, ILSVRC and CUB-200-2011. In addition, three metrics were utilized: Gt-Known Loc.Acc, op-1/Top-5 Loc.Acc and MaxBoxAccV2. A comparison with CAM-based and transformer-based approaches from the state-of-the-art demonstrates that TRT outperforms previous works by a large margin over the two datasets. An ablation study proved that the re-attention module improves the accuracy of the overall network.
In this article, we have seen an overview of a new weakly supervised object localization method, TRT, which leverages the advantages of transformers, class activation maps, and re-attention. TRT successfully eliminates the effects of background noise caused by the transformer and focuses on the target object. Numerous tests on two benchmarks show that the suggested method performs better than the existing approaches.
This Article is written as a research summary article by Marktechpost Research Staff based on the research paper 'RE-ATTENTION TRANSFORMER FOR WEAKLY SUPERVISED OBJECT LOCALIZATION'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.