Researchers from China Introduce DualToken-ViT: A Fusion of CNNs and Vision Transformers for Enhanced Image Processing Efficiency and Accuracy
In recent years, vision transformers (ViTs) have become a potent architecture for various vision applications, including object identification and picture classification. This is because, whereas the size of the convolutional kernel constrains convolutional neural networks (CNNs) and can only extract local information, self-attention can remove global information from the picture, delivering adequate and meaningful visual characteristics. There still needs to be an indication of performance saturation as the size of the dataset and the model for ViTs rise, which is a benefit over CNNs for both big models and huge datasets. Due to several inductive biases ViTs lack, CNNs are preferable over ViTs in lightweight models.
Self-attention’s quadratic complexity contributes to the potentially high computational cost of ViTs. Consequently, it isn’t easy to build lightweight, effective ViTs. Propose a pyramid structure that separates the model into multiple stages, with the number of tokens reducing and the number of channels growing per stage to construct more effective and lightweight ViTs. Emphasis on streamlining and refining self-attention structure to mitigate its quadratic complexity, but at the expense of attention’s usefulness. A typical strategy is to downsample the key and value of self-attention, which reduces the amount of tokens engaged in the process.
By conducting self-attention on the grouped tokens independently, certain locally grouped self-attention-based works lower the complexity of the overall attention component. Still, such techniques may harm the sharing of global knowledge. Some efforts additionally provide a few extra teachable parameters to enhance the backbone’s global information, including adding the branch of global tokens used at all stages. Local attention techniques like locally grouped self-attention-based and convolution-based structures can be enhanced using this method. However, all existing international token approaches only consider global information and disregard positional information, which is crucial for vision tasks.

Figure 1: A visualization of the attention map for the key token (the most crucial component of the picture for the image classification challenge) and position-aware global tokens. The first picture in each row serves as the model’s input, while the second image depicts the correlation between each token in the position-aware global tokens, which each comprise seven tokens, where the red-boxed section is the first image’s key token.
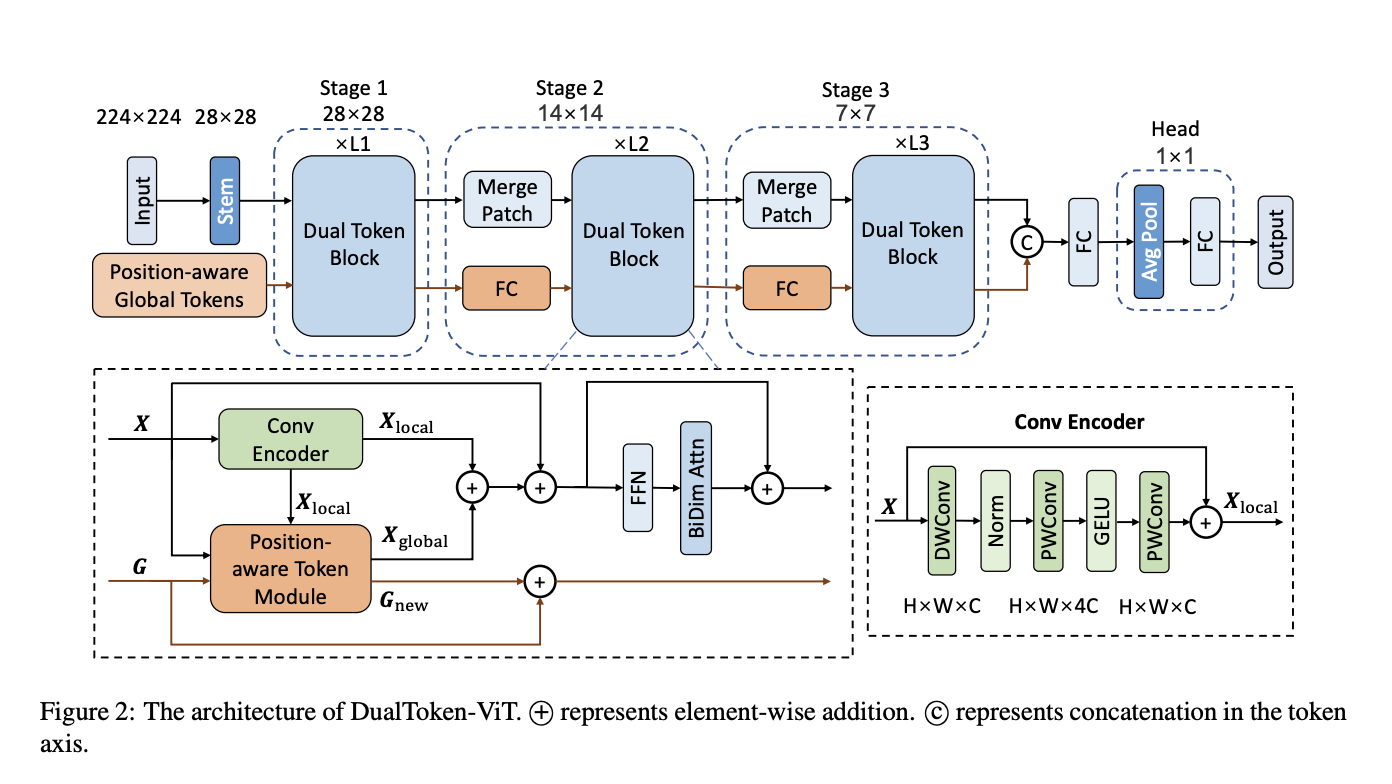
In this study, researchers from East China Normal University and Alibaba Group put forth the DualToken-ViT, a compact and effective vision transformer model. Their suggested paradigm replaces self-attention with a more effective attentional framework. Convolution and self-attention are used together to extract local and global information. The outputs of the two processes are then fused to create an effective attention structure. Although window self-attention may also remove local information, they find that their lightweight model’s convolution is more effective. They step-wise downsample the feature map that creates key and value to retain more information throughout the downsampling process. This can lower the computational cost of self-attention in global information broadcasting.
Additionally, they employ position-aware global tokens at every level to improve global data quality. Their position-aware global tokens can also maintain and pass on picture location information, providing their model an edge in vision tasks, in contrast to the standard global tokens. The efficacy of their position-aware global tokens is seen in Figure 1, where the key token in the image produces a greater correlation with the equivalent tokens in the position-aware global tokens.
In a nutshell, their contributions are as follows:
• They develop a compact and effective vision transformer model called DualToken-ViT, which fuses local and global tokens containing local and global information, respectively, to achieve an efficient attention structure by combining the benefits of convolution and self-attention.
• They also suggest position-aware global tokens, which would expand the global information by including the image’s location data.
• Their DualToken-ViT exhibits the greatest performance on image classification, object identification, and semantic segmentation among vision models of the same FLOPs magnitude.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.