Researchers from China Introduce ImageBind-LLM: A Multi-Modality Instruction Tuning Method of Large Language Models (LLMs) via ImageBind
Researchers have recently seen significant improvements in large language models’ (LLMs) instruction tuning. ChatGPT and GPT-4 are general-purpose talking systems that obey human commands in language and visuals. However, they are still unreplicable because of the closed-source constraint. Alpaca, LLaMAAdapter, and related efforts offer to modify the publicly accessible LLaMA into language instruction models using self-generated data in response to this. LLaVA, LLaMA-Adapter, and others integrate visual understanding capabilities into LLMs for image-conditioned generation to accomplish picture instruction tailoring.
Despite the success of current instruction tuning techniques, more is needed to create an LLM for broad multimodality instructions, such as text, picture, audio, 3D point clouds, and video. The authors of this study from Shanghai Artificial Intelligence Laboratory, CUHK MMLab and vivo AI Lab introduce the ImageBind-LLM multimodality instruction-following model, which effectively fine-tunes LLaMA under the direction of the joint embedding space in the pre-trained ImageBind. As shown in Figure 1, their ImageBind-LLM (b) can respond to input instructions of numerous modalities in addition to pictures, distinct from earlier visual instruction models (a), demonstrating promising extensibility and generalization capacity.
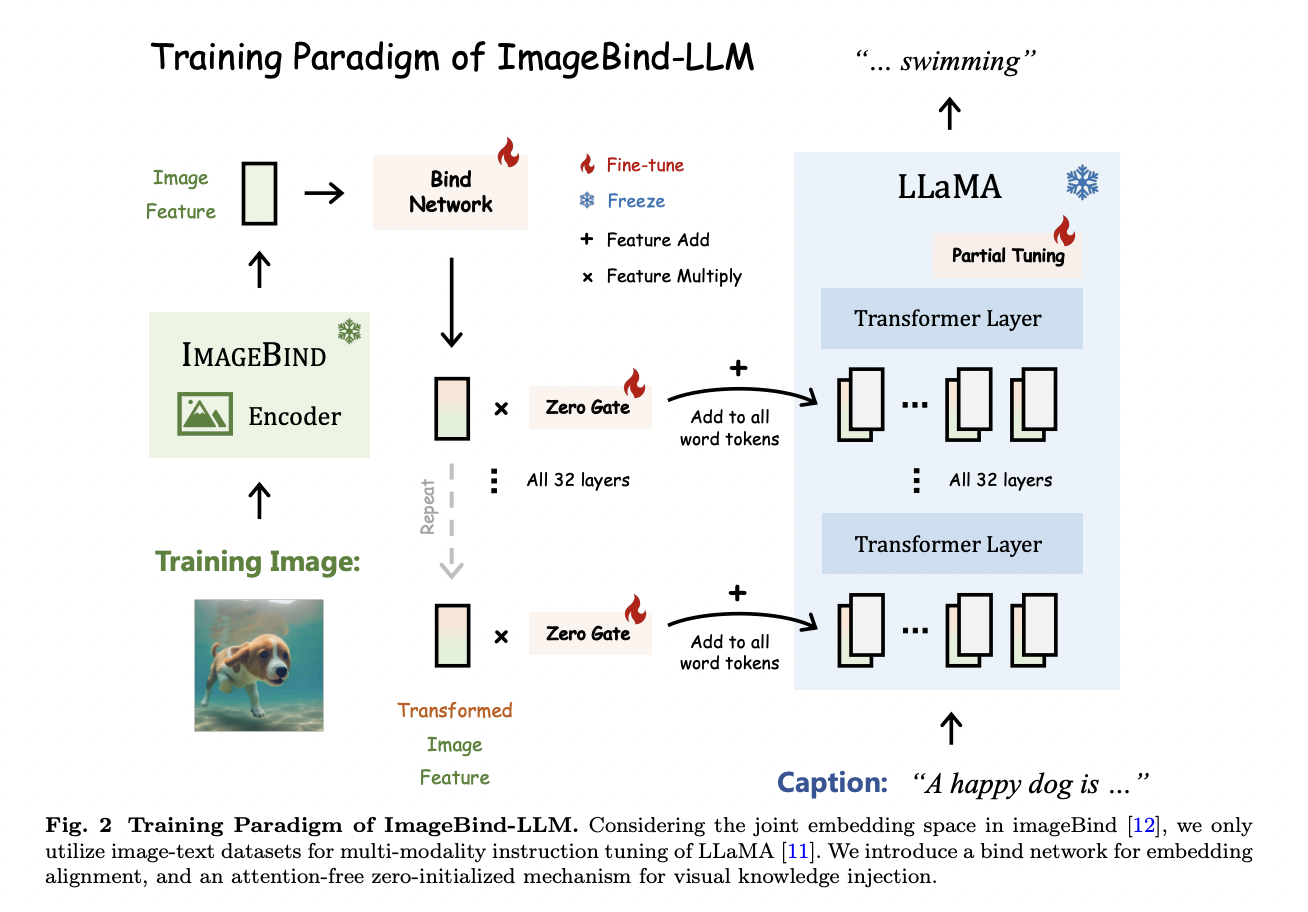
They specifically propose solely using the vision-language data for tweaking multimodality instruction due to ImageBind’s image-aligned multimodality embedding space. For a picture-caption pair, they first extract the global image feature using ImageBind’s frozen image encoder before embedding transformation using a learnable bind network. The converted picture feature is subsequently applied to all transformer layer word tokens in LLaMA, creating the visual context for generating the appropriate textual caption. In contrast to the zero-initialized attention in the LLaMA-Adapter series, their visual injection mechanism is simple and weighted by a trainable zero-initialized gating factor.
In this effective way, as the training progresses, the instruction cues of ImageBind’s multimodality embeddings may be gradually introduced into LLaMA without interfering with the original language understanding. Using ImageBind for modality-specific encodings, such as text, picture, audio, and video, their ImageBind-LLM acquires the competence to obey instructions of diverse modalities after the basic vision-language training. They use the pre-trained 3D encoder in Point-Bind to encode the input 3D point clouds for instructions in 3D domains. They also provide a training-free visual cache approach for embedding augmentation during inference to address the modality gap between image training and text, audio, 3D, or video-conditioned production.

The cache model comprises millions of picture features in the training datasets retrieved by ImageBind, which enhances text/audio/3D/video embeddings by obtaining comparable visual characteristics (Tip-Adapter). As a result, verbal replies to multimodal instructions are of greater quality. They test ImageBind-LLM’s multimodality instruction-following capabilities in various circumstances and consistently find it to perform better.
Overall, their ImageBind-LLM demonstrates the four qualities listed below.
• Instructions with many modes. ImageBind-LLM is optimized to respond to general multimodality inputs, such as image, text, audio, 3D point clouds, and video, and their embedding-space arithmetic represented by ImageBind and Point-Bind. This is different from earlier language and image instruction models.
• Efficiency Tuning. During training, they freeze ImageBind’s image encoder and adjust partial weights in LLaMA using parameter-efficient approaches like LoRA and bias-norm tuning. They also train the zero-initialized gating factors and the extra bind network.
• Zero-initialized Injection without Attention. They employ a learnable gating method for progressive knowledge injection, which is more straightforward and efficient, and incorporate the multimodality requirements with all word tokens of LLaMA directly instead of introducing additional instruction signals through attention layers.
• Retrieval from a cross-modal cache. They offer a visual cache model from image features extracted by ImageBind, which performs cross-modality retrieval for embedding augmentation to address the modality disparity between training (single picture) and inference (many modalities).
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.