Researchers from China Introduce Make-Your-Video: A Video Transformation Method by Employing Textual and Structural Guidance
Videos are a commonly used digital medium prized for their capacity to present vivid and engaging visual experiences. With the ubiquitous use of smartphones and digital cameras, recording live events on camera has become simple. However, the process gets significantly more difficult and expensive when producing a video to represent the idea visually. This often calls for professional experience in computer graphics, modeling, and animation creation. Fortunately, new developments in text-to-video have made it possible to streamline this procedure by using only text prompts.

Figure 1 shows how the model can produce temporally coherent films that adhere to the guidance intents when given text descriptions and motion structure as inputs. They demonstrate the video production outcomes in several applications, including (top) real-world scene setup to video, (middle) dynamic 3D scene modelling to video, and (bottom) video re-rendering, by constructing structure guidance from various sources.
They contend that while language is a well-known and flexible description tool, it may need to be more successful at giving precise control. Instead, it excels at communicating abstract global context. This encourages us to investigate the creation of customized videos using text to describe the setting and motion in a specific direction. As frame-wise depth maps are 3D-aware 2D data well suited to the video creation task, they are specifically chosen to describe the motion structure. The structure direction in their method might be relatively basic so that non-expert can readily prepare it.
This architecture gives the generative model the freedom to generate realistic content without relying on meticulously produced input. For instance, creating a photorealistic outside environment can be guided by a scenario setup employing goods found in an office (Figure 1(top)). The physical objects may be substituted with specific geometrical parts or any readily available 3D asset using 3D modeling software (Figure 1(middle)). Using the calculated depth from already-existing recordings is another option (Figure 1(bottom)). To customize their movies as intended, users have both flexibility and control thanks to the mix of textual and structural instruction.
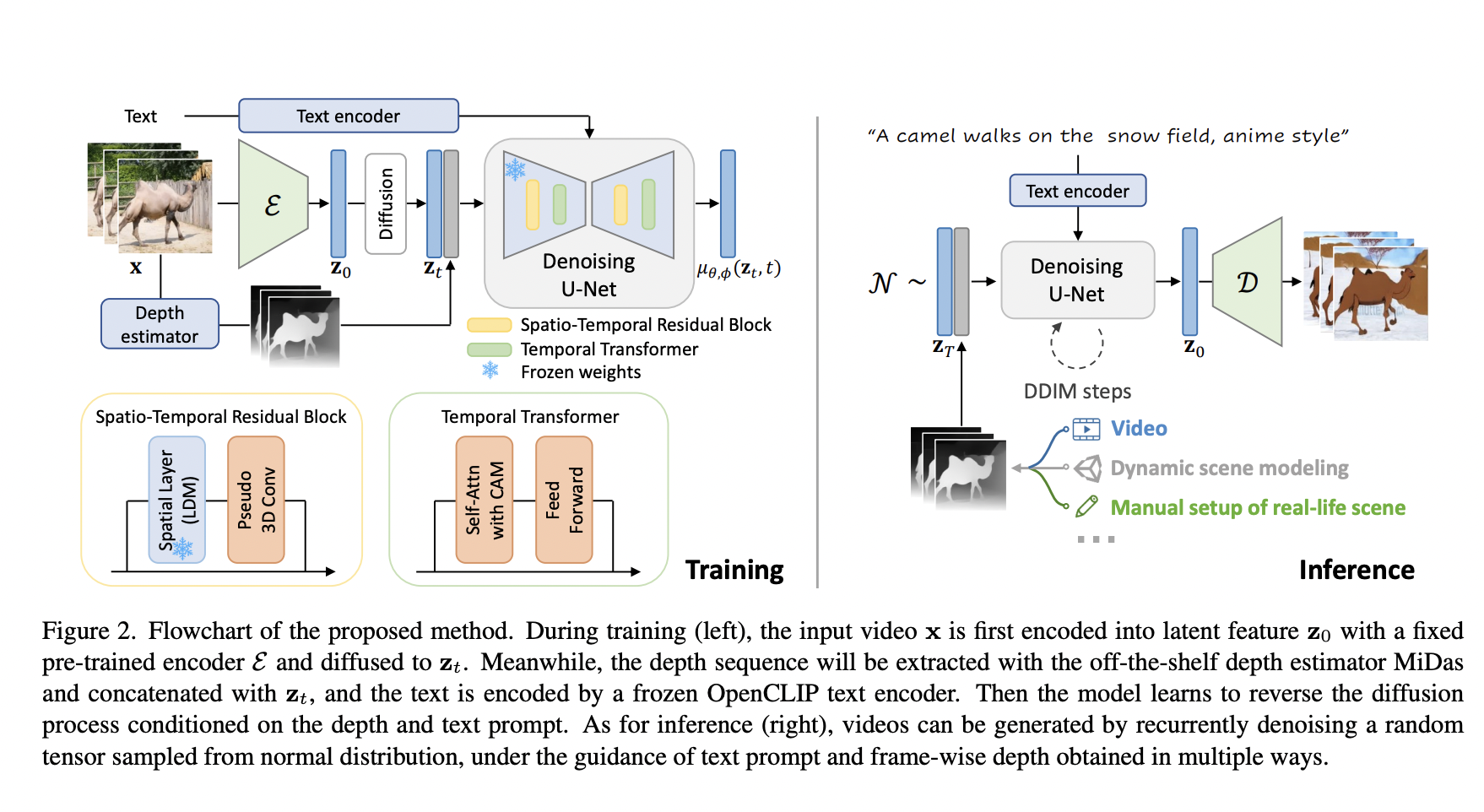
To do this, researchers from CUHK, Tencent AI Lab and HKUST use a Latent Diffusion Model (LDM), which adopts a diffusion model in a tight lower-dimensional latent space to reduce processing costs. They suggest separating the training of spatial modules (for image synthesis) and temporal modules (for temporal coherence) for an open-world video production model. This design is based on two main factors: (i) training the model components separately reduces computational resource requirements, which is especially important for resource-intensive tasks; and (ii) as image datasets encompass a much wider variety of concepts than the existing video datasets, pre-training the model for image synthesis aids in inheriting the diverse visual concepts and transfer them to video generation.
Achieving temporal coherence is a significant task. They keep them as the frozen spatial blocks and introduce the temporal blocks designed to learn inter-frame coherence throughout the video dataset using a pre-trained picture LDM. Notably, they incorporate spatial and temporal convolutions, increasing the pre-trained modules’ flexibility and enhancing temporal stability. Additionally, they use a straightforward but powerful causal attention mask method to enable lengthier (i.e., four times the training period) video synthesis, considerably reducing the risk of quality deterioration.
Qualitative and quantitative evaluations show that the suggested technique outperforms the baselines, especially in terms of temporal coherence and faithfulness to user instructions. The efficiency of the proposed designs, which are essential to the operation of the approach, is supported by ablation experiments. Additionally, they demonstrated several fascinating applications made possible by their methodology, and the outcomes illustrate the potential for real-world applications.
The following is a summary of their contributions: • They offer textual and structural assistance to present an effective method for producing customized videos. Their approach produces the best results in both quantitative and qualitative terms for regulated text-to-video production. • They provide a method for using pre-trained image LDMs to generate videos that inherit rich visual notions and have good temporal coherence. • They include a temporal masking approach to extend the duration of video synthesis while minimizing quality loss.
Check Out The Paper, Project and Github. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.