Researchers From China Propose A New Machine Learning Framework Called BootMAE (Bootstrapped Masked Autoencoders) For Vision BERT Pretraining
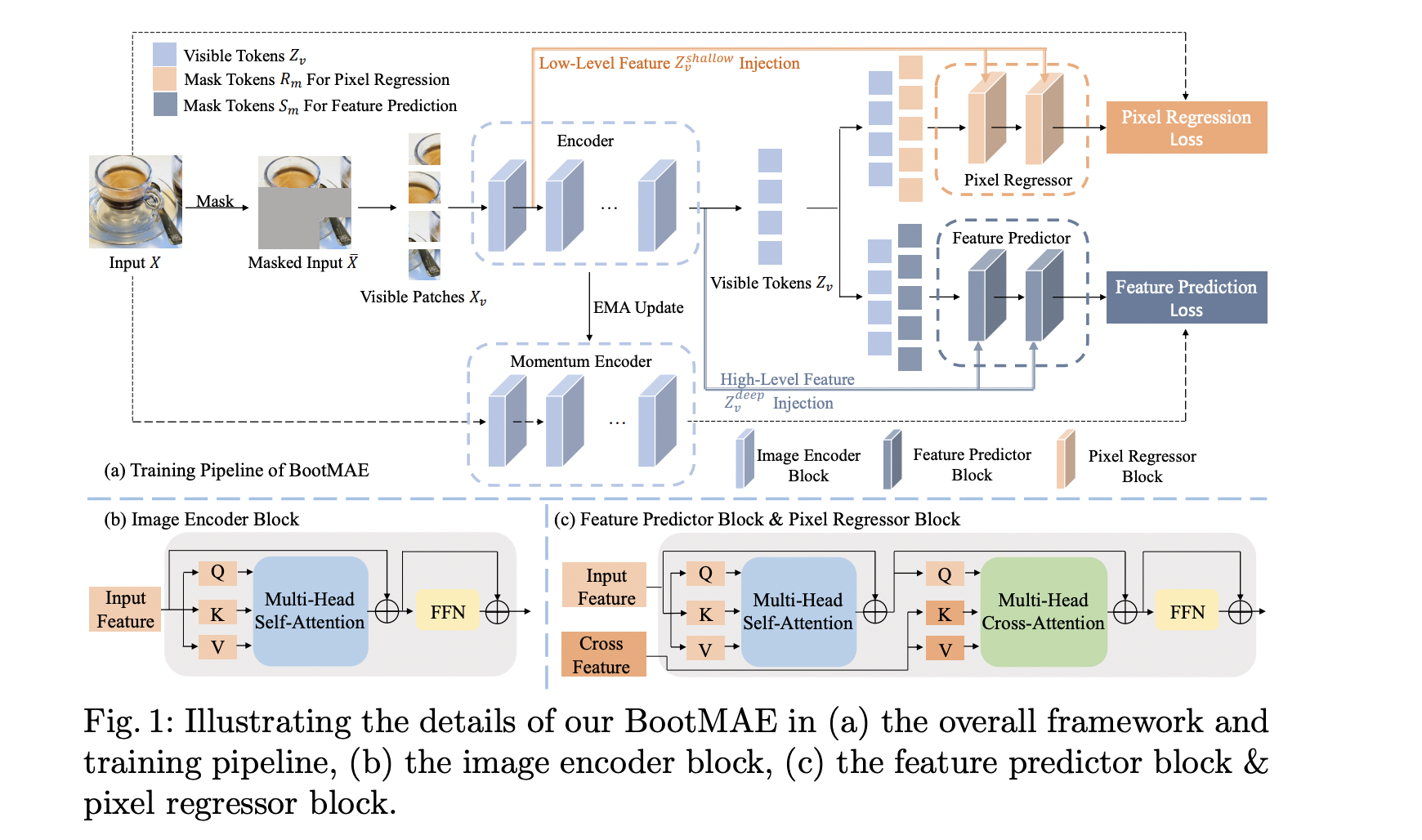
In the computer vision field, self-supervised representation learning has been a challenging problem for a long time. Self-supervised representation learning aims to learn transferrable representation from unlabeled data. The recent Masked AutoEncoder (MAE) approach presents an asymmetric encoder-decoder framework where the encoder focuses on visible patches, and the encoder’s output is passed into a lightweight decoder along with masked tokens. This work proposes bootstrapped masked autoencoders (BootMAE) for vision BERT pretraining. This approach has two core designs: momentum encoder and target-aware decoder. There are four primary modules of this research. 1) To record structure knowledge, an encoder is designed. 2) a regressor that utilizes the encoder’s structure knowledge and low-level context information to do pixel-level regression. 3) a predictor for latent representation prediction that uses the encoder’s structure knowledge and high-level context details. 4) Both regressor and predictor decoders have feature injection modules that help in adding their respective targets’ details. Figure 1. showcases the architecture of BootMAE along with the encoder network, the pixel regressor decoder network, the feature predictor decoder network, and feature injection modules.
In this research, based on the MAE approach, the encoder only manages the visible patches and produces the latent representation for efficient training. The proposed feature injection module delivers context information directly into each decoder layer. It provides the shallow layer of the encoder’s features to the regressor decoder and the deep layer’s features to the predictor decoder. The employed pixel-level regression module not only assists in keeping the model from collapsing but also directs the model to grasp reasoning regarding low-level textures.
This research utilizes two vision transformer blocks and a fully connected layer to create a lightweight architecture for the regressor that can forecast missing pixels. This research uses the predictor to predict the masked patches’ feature representation. Additionally, it uses the output of the regressor’s normalized pixels as the ground truth reconstruction target for MAE.
Standard ViT base, ViT-B, and ViT-L are used for the encoder in this work. The input consists of 14 x 14 patches from the 224 x 224, and each patch consists of a 16×16 size. With a batch size of 4096, the ViT-B and ViT-L models are trained for 800 epochs. Adam optimizer and a cosine schedule have a 2.4e-3 learning rate for 40 epochs. For ImageNet, 100 and 50 epochs are utilized for ViT-B and ViT-L, respectively.
One primary section of the proposed architecture is the bootstrapped feature prediction. The bootstrapped feature is used to help the model learn from dynamically more affluent semantic information by predicting the image’s iteratively generated latent representation. The results showcase that the bootstrapped feature prediction outperforms the vanilla MAE approach. This approach also adds a feature integration module. It gives the regressor and the predictor various features corresponding to different context information levels. The method investigates random masking and random block-wise masking, two commonly used masking techniques in masked image modeling.
The regressor and predictor contain two transformer layers. This approach varies the network depth and conducts experiments. The outcomes demonstrate that depths 2 and 8 achieve the best performance in terms of fine-tuning. On the ImageNet-1K dataset, the suggested algorithms result in top-1 validation accuracy compared to other cutting-edge classification techniques. Transfer learning experiments are assessed on Semantic Segmentation and Object Detection and Segmentation to further validate the learned visual representation of the proposed BootMAE. The suggested model performs better on both tasks than all the other baselines and supports the suggested framework’s usefulness.
Hence, Masked image modeling for vision BERT pretraining in the NLP domain has become incredibly popular. This research proposes that BOOTMAE has two prime modules. It bootstraps MAE’s latent feature representation that achieves improved results as the prediction target develops with training, delivering richer data gradually. It detaches the encoder’s target-specific context, making it focus on the image structure. The suggested method helps the encoder to concentrate on semantic modeling.
This Article is written as a research summary article by Marktechpost Research Staff based on the research paper 'Bootstrapped Masked Autoencoders for Vision BERT Pretraining'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Priyanka Israni is currently pursuing PhD at Gujarat Technological University, Ahmedabad, India. Her interest area lies in medical image processing, machine learning, deep learning, data analysis and computer vision. She has 8 years of teaching experience to engineering graduates and postgraduates.
![]()
Asif Razzaq is an AI Journalist and Cofounder of Marktechpost, LLC. He is a visionary, entrepreneur and engineer who aspires to use the power of Artificial Intelligence for good.
Asif’s latest venture is the development of an Artificial Intelligence Media Platform (Marktechpost) that will revolutionize how people can find relevant news related to Artificial Intelligence, Data Science and Machine Learning.
Asif was featured by Onalytica in it’s ‘Who’s Who in AI? (Influential Voices & Brands)’ as one of the ‘Influential Journalists in AI’ (https://onalytica.com/wp-content/uploads/2021/09/Whos-Who-In-AI.pdf). His interview was also featured by Onalytica (https://onalytica.com/blog/posts/interview-with-asif-razzaq/).
Credit: Source link
Comments are closed.