Researchers From China Propose A New Pre-trained Language Model Called ‘PERT’ For Natural Language Understanding (NLU)
PLMs (pre-trained language models) have excelled at a variety of natural language processing (NLP) tasks. Auto-encoding and auto-regressive PLMs are the most common classifications based on their training processes. The Bidirectional Encoder Representations from Transformers (BERT), which models the input text through deep transformer layers and creates deep contextualized representations, is a representative work of auto-encoding PLM. The Generative Pre-training (GPT) model is a good example of auto-regressive PLM.
The masked language model is the most common pre-training job for auto-encoding PLM (MLM). The goal of the MLM pre-training job is to recover a few input tokens in the vocabulary space by replacing them with masking tokens (i.e., [MASK]). MLM has a simple formulation, yet it can represent the contextual information around the masked token, which is akin to word2vec’s continuous bag-of-words (CBOW).
Based on the MLM pre-training task, a few modifications have been proposed to improve its performance, such as entire word masking, N-gram masking, and so on. ERNIE, RoBERTa, ALBERT, ELECTRA, MacBERT, and other PLMs are proposed as part of the MLM pre-training system.
However, a logical question arises: Can we employ a task other than MLM as a pre-training assignment? In recent work, researchers aim to investigate a pre-training task that is not generated from MLM in order to answer this question. The original motive behind the strategy is fascinating. Many sayings exist, such as “Permuting numerous Chinese characters has little effect on your reading.”
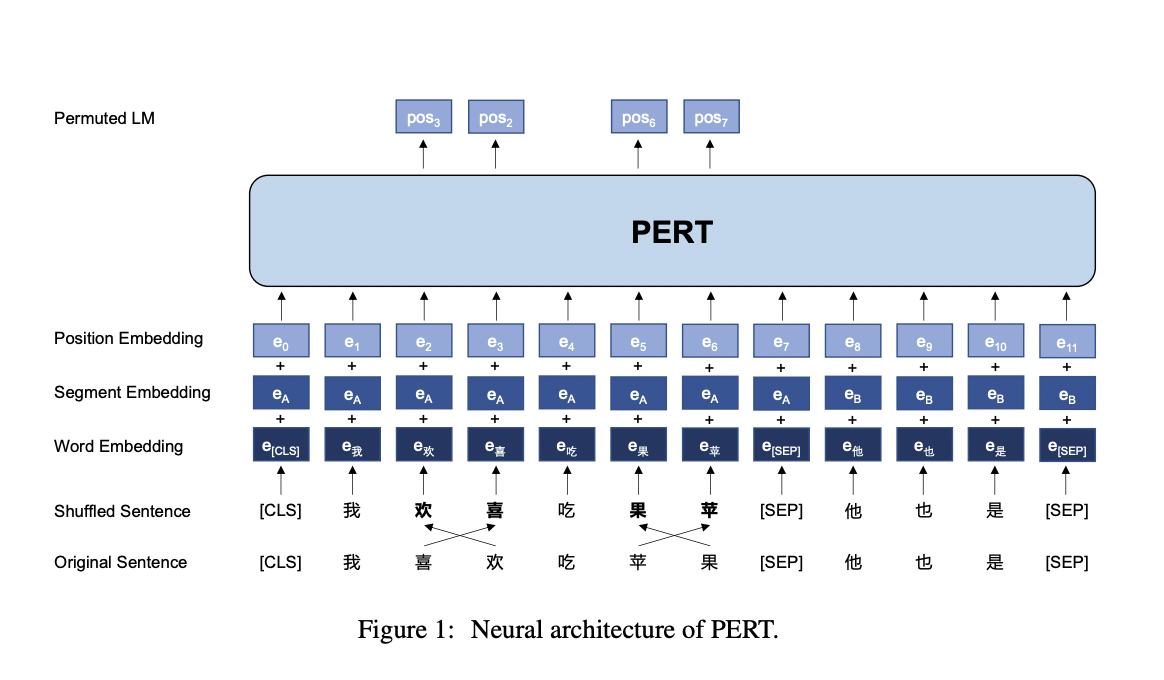
Although certain words in the statement are disorganized, the essential meaning of the sentence can still be understood. The team is intrigued by this phenomenon and wonders if they can model the contextual representation using permuted phrases. The team presents a new pre-training task termed permuted language model to investigate this subject (PerLM). The proposed PerLM attempts to recover word order from a disordered sentence with the goal of predicting the original word’s position.

PERT and BERT have the same neural architecture, but the input and training objectives are slightly different. The training goal of the proposed PERT is to estimate the position of the original token using a shuffled text as input. The following are the primary characteristics of PERT.
• Aside from replacing MLM with PerLM, PERT essentially follows BERT’s original architecture, including tokenization (using WordPiece), vocabulary (direct adoption), and so on.
• The artificial masking token is not used in PERT. [MASK].
• To improve performance, researchers apply both whole word masking and N-gram masking.
• The prediction space is dependent on the length of the input sequence, not the entire vocabulary (like MLM).
• PERT can directly replace BERT with adequate fine-tuning because its main body is the same as BERT’s.
To test their effectiveness, the team pre-trains both Chinese and English PERT. Extensive experiments, ranging from sentence-level to document-level, are undertaken on both Chinese and English NLP datasets, including machine reading comprehension, text categorization, and so on. The findings demonstrate that the proposed PERT can help with a few tasks. While this is going on, researchers are discovering their own flaws in others.
The following four domains (train/dev) are used to test the Word Order Recovery task: Wikipedia (990K/86K), Formal Doc. (1.4M/33K), Customs (682K/34K), and Legal (1.8M/13K). For the following studies, they report precision, recall, and F1 scores. In terms of all evaluation measures (P/R/F), PERT produces consistent and considerable gains over all baseline systems. This is in line with predictions, given that the fine-tuning work is quite similar to the PERT pre-training assignment. Even if the fine-tuning is done in a sequence tagging fashion (similar to NER), it can still benefit from PERT’s pre-training, which concentrates on placing words in the correct order.
Conclusion
Researchers suggest PERT, a new pre-trained language model that uses Permuted Language Model (PerLM) as the pre-training task, in this work. PerLM’s goal is to forecast the original token’s position in a shuffled input text, which differs from the MLM-like pre-training task. Researchers conducted comprehensive trials on both Chinese and English NLU tasks to assess PERT’s performance. The findings of the experiments suggest that PERT improves performance on MRC and NER tasks. PERT is subjected to additional quantitative evaluations in order to better understand the model and the requirements of each design. The researchers expect that the PERT trial will encourage others to create non-MLM-like pre-training tasks for text representation learning.
Paper: https://arxiv.org/pdf/2203.06906v1.pdf
Github: https://github.com/ymcui/pert
Suggested
Credit: Source link
Comments are closed.