Researchers From China Propose A Pale-Shaped Self-Attention (PS-Attention) And A General Vision Transformer Backbone, Called Pale Transformer
Transformers have recently demonstrated promising performance in a variety of visual tests. Inspired by Transformer’s success on a wide range of NLP tasks, Vision Transformer (ViT) first employed a pure Transformer architecture for image classification, demonstrating the promising performance of Transformer architecture for vision tasks.
However, the quadratic complexity of global self-attention leads to high computing costs and memory use, particularly for high-resolution situations, rendering it unsuitable for use in diverse visual tasks. Various strategies confine the range of attention inside a local region to increase efficiency and lower the quadratic computing complexity generated by global self-attention. As a result, their receptive fields in a single attention layer are insufficiently big, resulting in poor context modeling.
A new Pale-Shaped self-Attention (PS-Attention) method executes self-attention inside a pale-shaped zone to solve this issue. Compared to global self-attention, PS-Attention can considerably lower compute and memory expenses. Meanwhile, it can collect more fantastic contextual information while maintaining the same computational complexity as earlier local self-attention techniques.
One standard method for increasing efficiency is to replace global self-attention with local self-attention. A critical and challenging question is how to improve modeling capabilities in local situations. Here, the local attention region was considered a single row or column of the feature map in axial self-attention. Cross-shaped window self-attention was proposed, which may be regarded as multiple rows and column enlargement of axial self-attention.
Although these approaches outperform CNN equivalents in terms of performance, the dependencies in each self-attention layer are insufficient for collecting adequate contextual information.
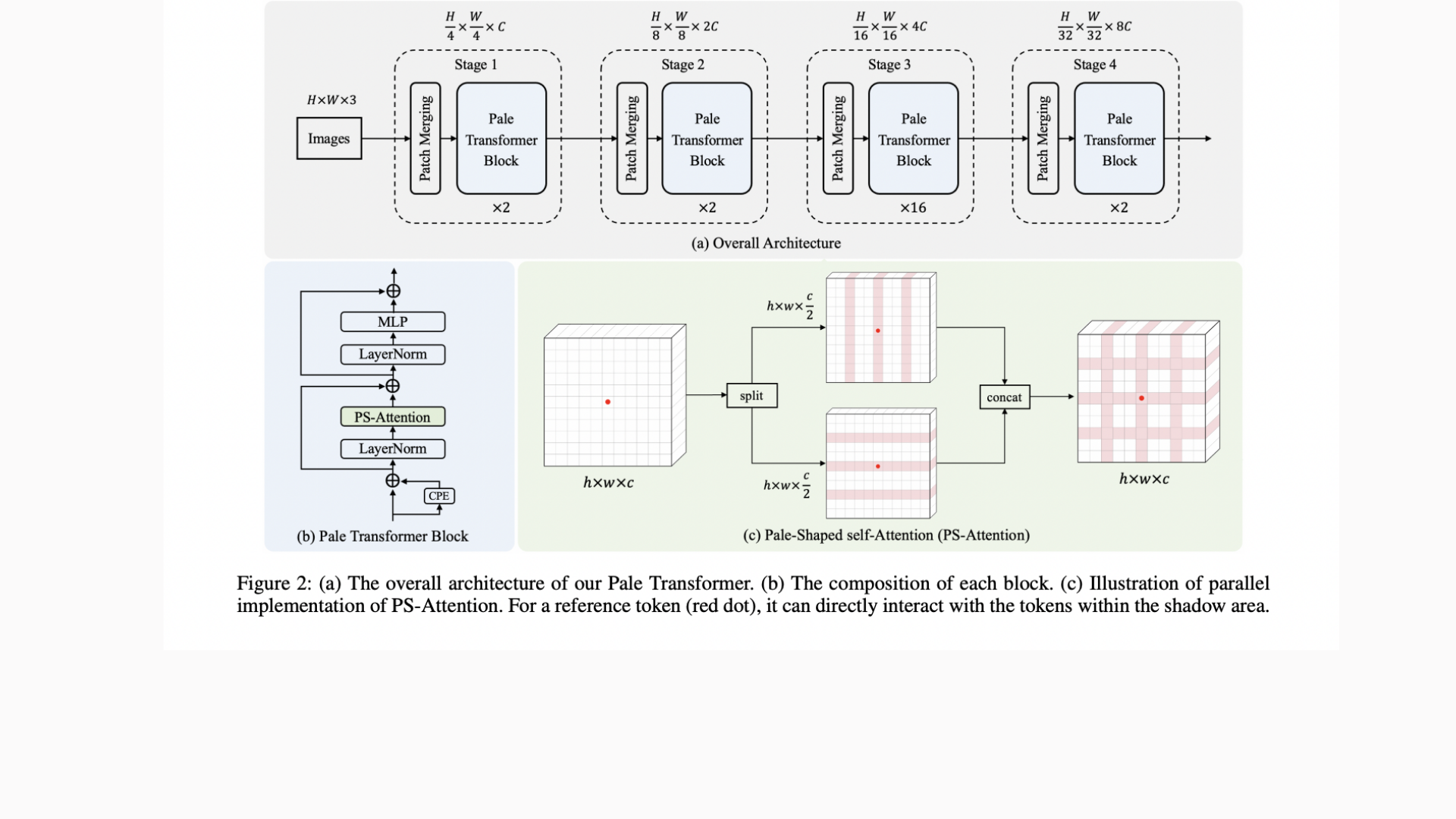
The suggested Pale-Shaped self-Attention (PS-Attention) effectively collects more prosperous contextual relationships. Specifically, the input feature maps are first spatially divided into numerous pale-shaped sections. Each pale-shaped region (abbreviated as pale) comprises the same number of the feature map’s interlaced rows and columns. The distances between neighboring rows or columns are the same for all pales. One of the pales, for example, is shown by the pink shadow in the following figure’s e part.

Then, inside each pale, self-attention is accomplished. Any token may directly interact with other tokens within the same pale, allowing the technology to capture deeper contextual information in a single PS-Attention layer. A more efficient parallel implementation of the PS-Attention was developed to further enhance performance. The PS-Attention outperforms the existing local self-attention mechanisms due to more expansive receptive fields and higher context modeling capacity.
The dominant research on enhancing the efficiency of Vision Transformer backbones was divided into two parts: eliminating superfluous computations through pruning procedures and building more efficient self-attention mechanisms.
The Pale Transformer, a generic vision transformer backbone with hierarchical architecture based on the suggested PS-Attention, scales up the technique to produce a set of models that outperform earlier efforts, including Pale-T (22M), Pale-S (48M), and Pale-B (85M). The new Pale-T outperforms state-of-the-art backbones by +0.7%, +1.1%, +0.7%, and +0.5% on ImageNet1k, 50.4 percent single-scale mIoU on ADE20K (semantic segmentation), 47.4 box mAP (object recognition), and 42.7 mask mAP (instance segmentation) on COCO.
Based on the suggested PS-Attention, the Pale Transformer is a generic Vision Transformer backbone that provides state-of-the-art image classification performance on ImageNet-1K. In addition, the Pale Transformer outperforms earlier Vision Transformer backbones on ADE20K for semantic segmentation and COCO for object identification and instance segmentation.
Paper: https://arxiv.org/pdf/2112.14000v1.pdf
Github: https://github.com/BR-IDL/PaddleViT
Suggested
Credit: Source link
Comments are closed.