Researchers from China Propose ALCUNA: A Groundbreaking Artificial Intelligence Benchmark for Evaluating Large-Scale Language Models on New Knowledge Integration
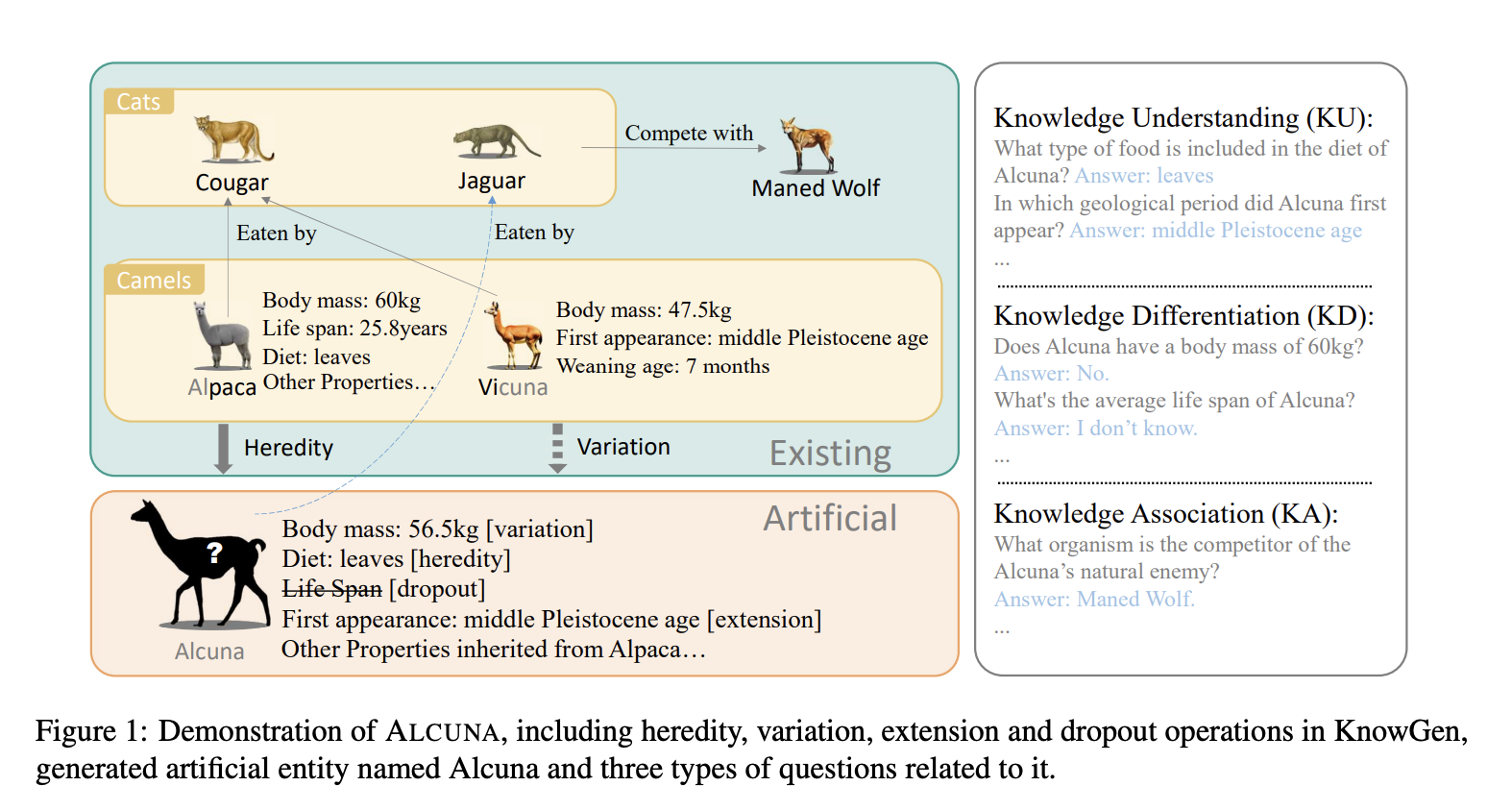
Evaluating large-scale language models (LLMs) in handling new knowledge is challenging. Researchers from Peking University introduced KnowGen, a method to generate new knowledge by modifying existing entity attributes and relationships. A benchmark called ALCUNA assesses LLMs’ abilities in knowledge understanding and differentiation. Their study reveals that LLMs often struggle with reasoning about new versus internal knowledge. It highlights the importance of caution when applying LLMs to new scenarios and encourages LLM development in handling new knowledge.
LLMs like FLAN-T5, GPT-3, OPT, LLama, and GPT-4 have excelled in various natural language tasks with applications in commercial products. Existing benchmarks assess their performance but rely on existing knowledge. Researchers propose Know-Gen and the ALCUNA benchmark to evaluate LLMs handling new knowledge. It emphasizes the need for caution when using LLMs with new scenarios or expertise and aims to spur development in this context.
LLMs have excelled in various tasks, but existing benchmarks may need to measure their ability to handle new knowledge. New standards are proposed to address this gap. Evaluating LLMs’ performance with new knowledge is crucial due to evolving information. Overlapping training and test data can affect memory assessment. Constructing a new knowledge benchmark is challenging but necessary.
Know-Gen is a method for generating new knowledge by modifying entity attributes and relationships. It evaluates LLMs using zero-shot and few-shot methods, with and without Chain-of-Thought reasoning forms. Their study explores the impact of artificial entity similarity to parent entities, assessing attribute and name similarity. Multiple LLMs are evaluated on these benchmarks, including ChatGPT, Alpaca-7B, Vicuna-13B, and ChatGLM-6B.
LLMs’ performance on the ALCUNA benchmark, assessing their handling of new knowledge, could be better, especially in reasoning between new and existing knowledge. ChatGPT performs the best, with Vicuna as the second-best model. The few-shot setting generally outperforms zero-shot, and the CoT reasoning form is superior. LLMs struggle most with knowledge association and multi-hop reasoning. Entity similarity has an impact on their understanding. Their method emphasizes the importance of evaluating LLMs on new knowledge and proposes the Know-Gen and ALCUNA benchmarks to facilitate progress in this area.
The proposed method is limited to biological data but has potential applicability in other domains adhering to ontological representation. Evaluation is constrained to a few LLM models due to closed-source models and scale, warranting assessment with a broader range of models. It emphasizes LLMs’ new knowledge handling but lacks an extensive analysis of current benchmark limitations. It also does not address potential biases or ethical implications related to generating new knowledge using the Know-Gen approach or the responsible use of LLMs in new knowledge contexts.
KnowGen and the ALCUNA benchmark can help to evaluate LLMs in handling new knowledge. While ChatGPT performs best and Vicuna is second best, LLMs’ performance in reasoning between new and existing knowledge could be better. Few-shot settings outperform zero-shot, and CoT reasoning is superior. LLMs struggle with knowledge association, emphasizing the need for further development. It calls for caution in using LLMs with new knowledge and anticipates these benchmarks will drive LLM development in this context.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.