Researchers from China Propose iTransformer: Rethinking Transformer Architecture for Enhanced Time Series Forecasting
Transformer has become the basic model that adheres to the scaling rule after achieving great success in natural language processing and computer vision. Time series forecasting is seeing the emergence of a Transformer, which is highly capable of extracting multi-level representations from sequences and representing pairwise relationships, thanks to its enormous success in other broad disciplines. The validity of transformer-based forecasts, which usually embed several variates of the same timestamp into indistinguishable channels and focus emphasis on these temporal tokens to capture temporal relationships, has lately come under scrutiny, though, from academics.
Transformer has become the basic model that adheres to the scaling rule after achieving great success in natural language processing and computer vision. Time series forecasting is seeing the emergence of a Transformer, which is highly capable of extracting multi-level representations from sequences and representing pairwise relationships, thanks to its enormous success in other broad disciplines. The validity of transformer-based forecasts, which usually embed several variates of the same timestamp into indistinguishable channels and focus emphasis on these temporal tokens to capture temporal relationships, has lately come under scrutiny, though, from academics.
They observe that multivariate time series forecasting may need to be a better fit for the Transformer-based forecasters’ current structure. Figure 2’s left panel makes note of the fact that points from the same time step that essentially reflect radically diverse physical meanings captured by contradictory measurements are combined into a single token with multivariate correlations erased. Furthermore, because of the real world’s highly local receptive field and misaligned timestamps of multiple time points, the token created by a single time step may find it difficult to disclose useful information. Furthermore, in the temporal dimension, permutation-invariant attention mechanisms are inappropriately used even though sequence order might have a significant impact on series variations.
As a result, Transformer loses its ability to describe multivariate correlations and capture crucial series representations, which restricts its application and generalization capabilities on various time series data. They use an inverted perspective on time series and embed the entire time series of each variate separately into a token, the extreme example of Patching that enlarges the local receptive field in response to the irrationality of embedding multivariate points of each time step as a token. The embedded token inverts and aggregates global representations of series, which may be better utilized by booming attention mechanisms for multivariate correlating and more variate-centric.
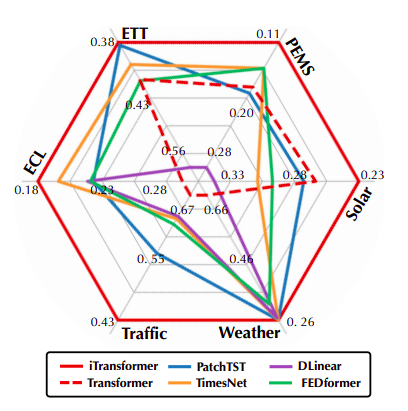
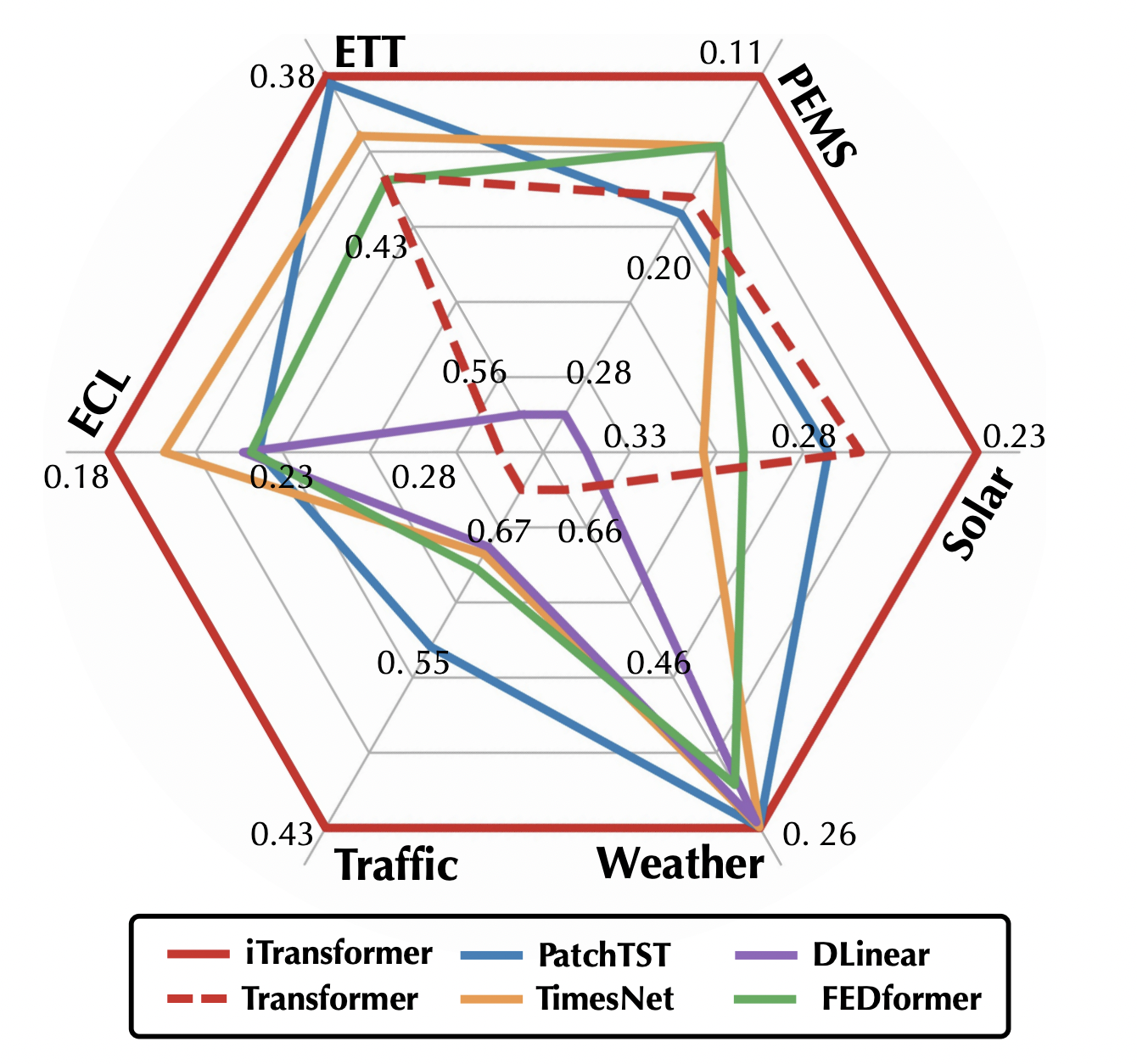
Figure 1: iTransformer’s performance. TimesNet is used to report average results (MSE).
In the meanwhile, the feed-forward network may be trained to acquire sufficiently well-generalized representations for different variates that are encoded from any lookback series and then decoded to forecast subsequent series. For the reasons outlined above, they think that Transformer is being utilized incorrectly rather than being ineffectual for time series forecasting. They go over Transformer’s architecture again in this study and promote iTransformer as the essential framework for time series forecasting. In technical terms, they use the feed-forward network for series encoding, adopt the attention for multivariate correlations, and embed each time series as variate tokens. In terms of experimentation, the suggested iTransformer unexpectedly addresses the shortcomings of Transformer-based forecasters while achieving state-of-the-art performance on the real-world forecasting benchmarks in Figure 1.
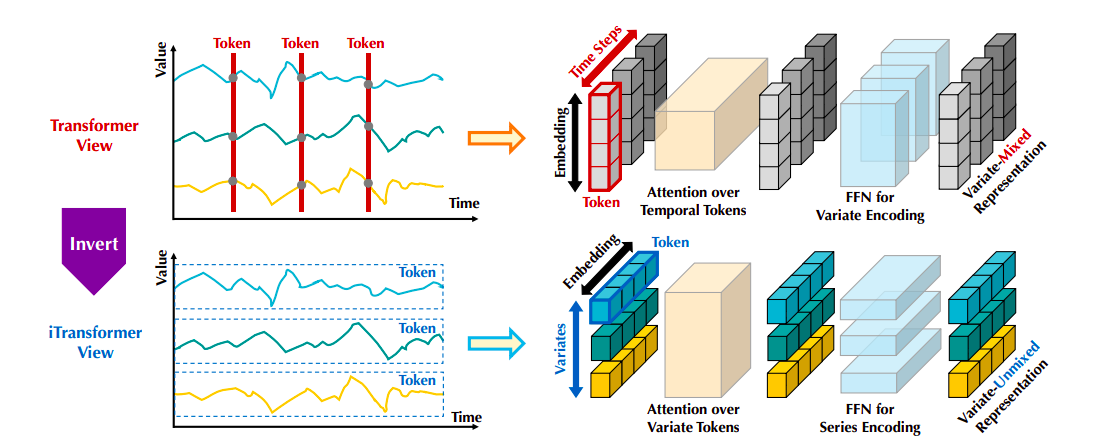
Figure 2: A comparison of the suggested iTransformer (bottom) and the vanilla Transformer (top).In contrast to Transformer, which embeds each time step to the temporal token, iTransformer embeds the whole series independently to the variate token. As a result, the feed-forward network encodes series representations, and the attention mechanism can show multivariate correlations.
Three things they have contributed are as follows:
• Researchers from Tsinghua University suggest iTransformer, which views independent time series as tokens to capture multivariate correlations by self-attention. It uses layer normalization and feed-forward network modules to learn better series-global representations for time series forecasting.
• They reflect on the Transformer architecture and refine the competent capability of native Transformer components on time series is underexplored.
• On real-world predicting benchmarks, iTransformer consistently obtains state-of-the-art results in experiments. Their thorough analysis of the inverted modules and architectural decisions points to a potential path for advancing Transformer-based predictors in the future.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.