Researchers from CMU and NYU Propose LLMTime: An Artificial Intelligence Method for Zero-Shot Time Series Forecasting with Large Language Models (LLMs)
Despite having some parallels to other sequence modeling issues, like text, audio, or video, time series has two characteristics that make it particularly difficult. Aggregated time series datasets frequently include sequences from drastically varied sources, occasionally with missing values, in contrast to video or audio, which normally have uniform input scales and sample rates. Furthermore, many time series forecasting applications, like those for weather or financial data, call for extrapolating from observations that only contain a small portion of the information that may be there. This makes precise point forecasts incredibly difficult, making uncertainty estimates all the more crucial.
Pretraining is not frequently used for time series modeling because there is no consensus unsupervised objective, and large, cohesive pretraining datasets are not easily accessible. However, large-scale pretraining has become a key component of training large neural networks in vision and text, enabling performance to scale directly with data availability. Therefore, basic time series approaches, such as ARIMA and linear models, frequently outperform deep learning techniques on common benchmarks. The authors show how large language models (LLM) might naively bridge the gap between the straightforward biases of conventional approaches and the intricate representational learning and generative capabilities of contemporary deep understanding.
To use pretrained LLMs for continuous time series prediction applications, researchers from present the very straightforward approach LLMTIME2, which is high level depicted in Figure 1. This technique, which considers time series forecasting as a next-token prediction in text and fundamentally depicts the time series as a string of numerical digits, makes it possible to apply robust pretrained models and probabilistic capabilities like probability assessment and sampling. They provide methods to (1) efficiently encode time series as a string of numerical digits and (2) convert the discrete LLM distributions to continuous densities that may describe complex multimodal distributions to achieve high performance.Using these strategies, they discover that LLMTIME may be applied without modifying the downstream data utilized by other models to outperform or match purpose-built time series methods for various issues.
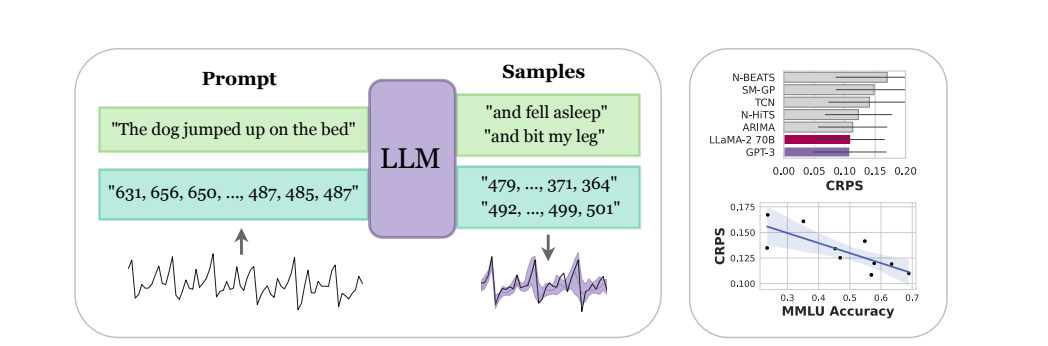
Figure 1: Using large language models (LLMs), researchers present LLMTIME, a method for time series forecasting that entails encoding numbers as text and selecting potential extrapolations as text completions. Without any training on the target dataset (i.e. zero-shot), LLMTIME can beat a number of well-known time series algorithms. The strength of the underlying base model scales with the performance of LLMTIME as well. It is noteworthy that models that go through alignment (like RLHF) do not adhere to the scaling trend.
For instance, Section 6 shows that GPT-4 performs worse than GPT-3.
The zero-shot property of LLMTIME has the following inherent benefits: (1) It facilitates the simple application of LLMs, removing the need for specialized knowledge of fine-tuning procedures and the significant computational resources required for these procedures. (2) It is well suited to scenarios with limited data availability, with little information for training or fine-tuning. (3) It avoids the considerable time, effort, and domain-specific expertise generally necessary for creating specialized time series models by using extensively pre-trained LLMs’ broad pattern extrapolation abilities. They look at how LLMs exhibit preferences for straightforward or repetitive sequences and demonstrate that these biases are consistent with the important features of time series, such as seasonality, to understand the reasons behind LLMTIME’s excellent performance. Aside from these biases, LLMs can also represent multimodal distributions and easily accommodate missing data, which is especially helpful for time series.
They also demonstrate how LLMs make it possible for attractive features like inquiring for extra side information and asking the LLM to justify its predictions. Finally, they show that performance tends to increase with size and that the quality of point forecasts also increases with the quality of the uncertainty representation, in addition to generally attractive forecasting performance. They also discovered that GPT-4 has worse uncertainty calibration than GPT-3, probably because of interventions like RLHF (reinforcement learning with human feedback).
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.