Researchers from CMU and Peking Introduces ‘DiffTOP’ that Uses Differentiable Trajectory Optimization to Generate the Policy Actions for Deep Reinforcement Learning and Imitation Learning
According to recent studies, a policy’s depiction can significantly affect learning performance. Policy representations such as feed-forward neural networks, energy-based models, and diffusion have all been investigated in earlier research.
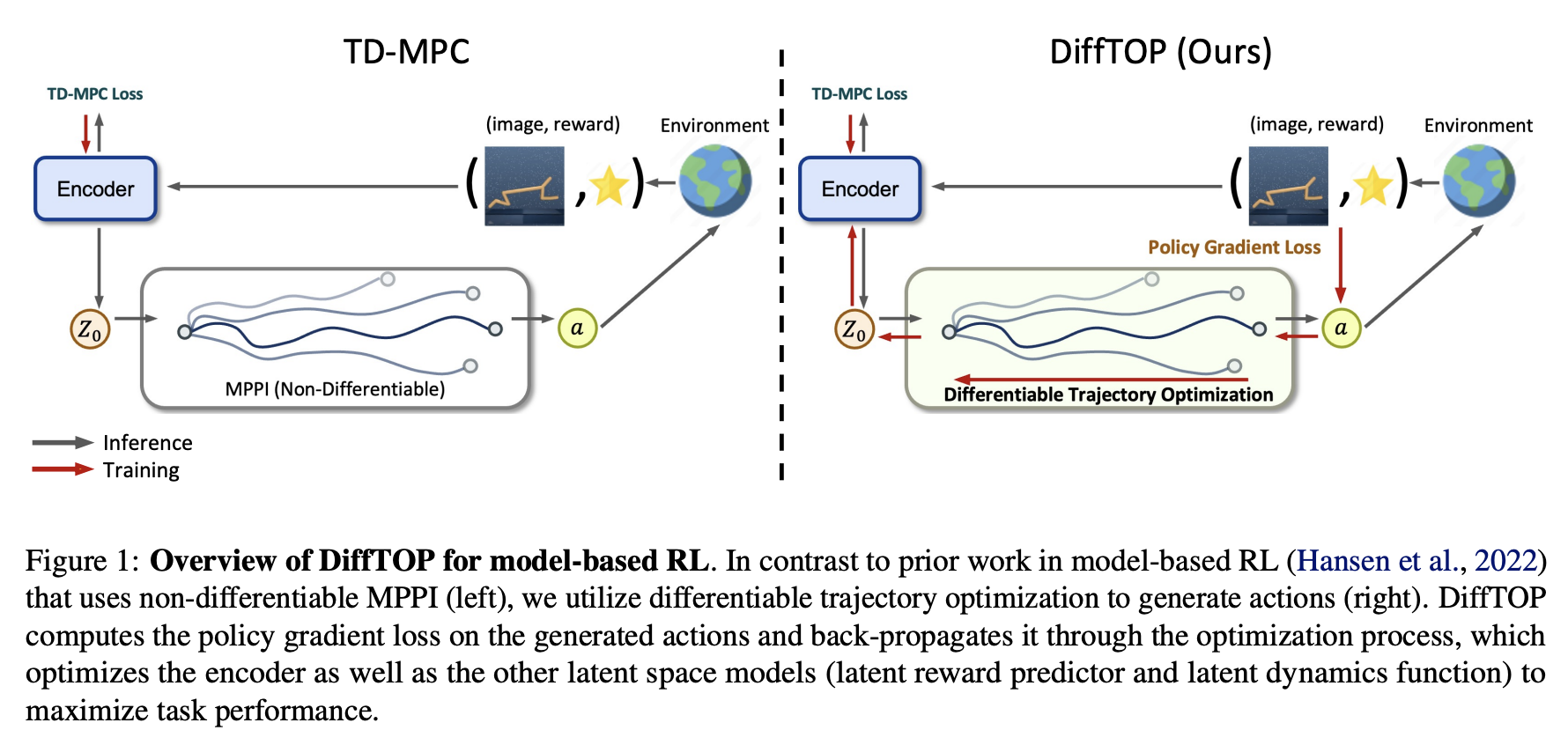
A recent study by Carnegie Mellon University and Peking University researchers proposes producing actions for deep reinforcement and imitation learning using high-dimensional sensory data (images/point clouds) and differentiable trajectory optimization as the policy representation. A cost function and a dynamics function are typically used to define trajectory optimization, a popular and successful control approach. Consider it a policy whose parameters define the cost function and the dynamics function, in this case represented by neural networks.
After receiving the input state (such as pictures, point clouds, or robot joint states) and the learned cost and dynamics functions, the policy will solve the trajectory optimization problem to determine the actions to take. It is also possible to make trajectory optimization differentiable, which opens the door to back-propagation inside the optimization process. Problems with low-dimensional states in robotics, imitation learning, system identification, and inverse optimal control have all been addressed in earlier work using differentiable trajectory optimization.
This is the first demonstration of a hybrid approach that combines deep model-based RL algorithms with differentiable trajectory optimization. The team learns the dynamics and cost functions to optimize the reward by computing the policy gradient loss on the generated actions, which is made possible by using differentiable trajectory optimization for action generation.
Models that perform better during training (e.g., with a lower mean squared error) when learning a dynamics model are not always better when it comes to control, and this is the “objective mismatch” problem that this method seeks to solve in present model-based RL algorithms. In order to solve this problem, they developed DiffTOP, which stands for “Differentiable Trajectory Optimization.” By optimizing the trajectory, they maximize task performance by back-propagating the policy gradient loss, which optimizes both the latent dynamics and the reward models.
The comprehensive experiments demonstrate that DiffTOP outperforms previous state-of-the-art methods in both model-based RL (15 tasks) and imitation learning (13 tasks) using standard benchmarking with high-dimensional sensory observations. These tasks included 5 Robomimic tasks using images as inputs and 9 Maniskill1 and Maniskill2 challenges using point clouds as inputs.
The team also compares their approach to feed-forward policy classes, Energy-Based Models (EBM), and Diffusion and evaluates DiffTOP for imitation learning on common robotic manipulation task suites using high-dimensional sensory data. Compared to the EBM approach utilized in previous work, which can experience training instability because it requires sampling high-quality negative samples, their training procedure using differentiable trajectory optimization leads to improved performance. The proposed method of learning and optimizing a cost function during testing allows us to outperform diffusion-based alternatives as well.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.