Researchers from Columbia University and Apple Introduce Ferret: A Groundbreaking Multimodal Language Model for Advanced Image Understanding and Description
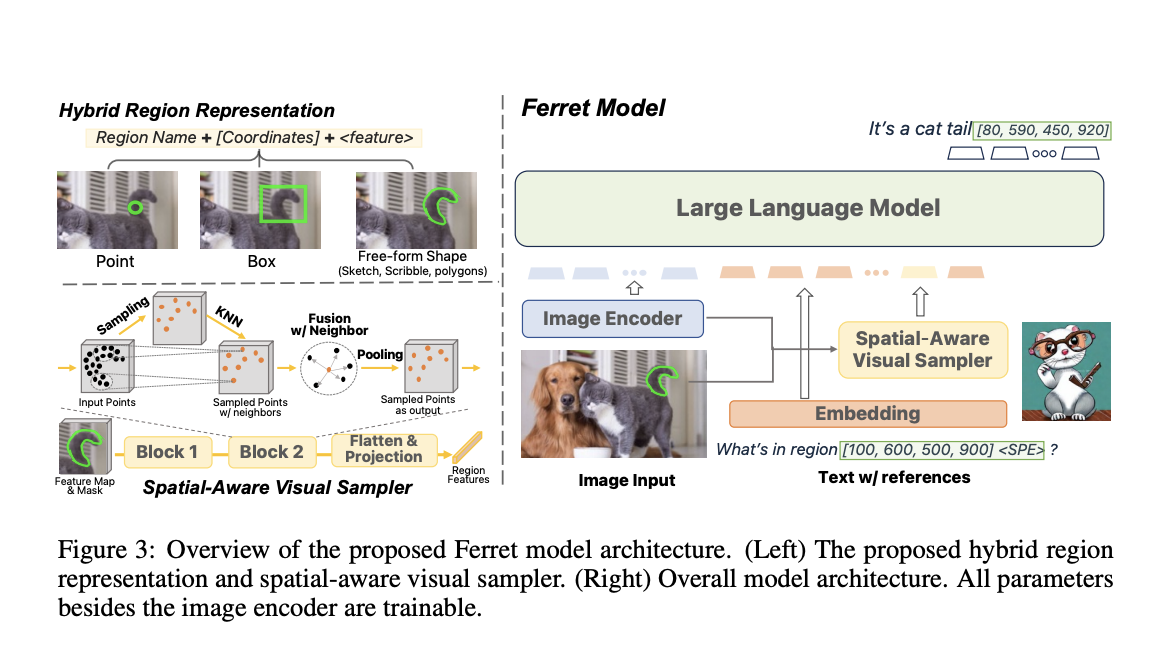
How to facilitate spatial knowledge of models is a major research issue in vision-language learning. This dilemma leads to two required capabilities: referencing and grounding. While grounding requires the model to localize the region in line with the provided semantic description, referring asks that the model fully understand the semantics of specific supplied regions. In essence, aligning geographical information and semantics is the knowledge needed for both referencing and grounding. Despite this, referencing and grounding are typically taught separately in current texts. Humans, on the other hand, can smoothly combine referring/grounding capacities with everyday discussion and Reasoning, and they can learn from one activity and generalize the shared knowledge to the other work without difficulty.
In this research, they investigate three key issues in light of the aforementioned disparity. (i) How might referencing and grounding be combined into a single framework, and how will they complement one another? (ii) How do you depict the many regions people often use to refer to things, such as points, boxes, scribbles, and freeform shapes? (iii) How can referencing and grounding, essential for practical applications, become open-vocabulary, instruction-following, and robust? Researchers from Columbia University and Apple AI/ML present Ferret, a brand-new refer-and-ground Multimodal Large Language Model (MLLM), to address these three issues. They first chose MLLM as Ferret’s foundation because of its strong vision-language global understanding capacity. As shown in Figure 1, Ferret initially encodes the coordinates of areas in plain language numerical form to unify referencing and grounding.
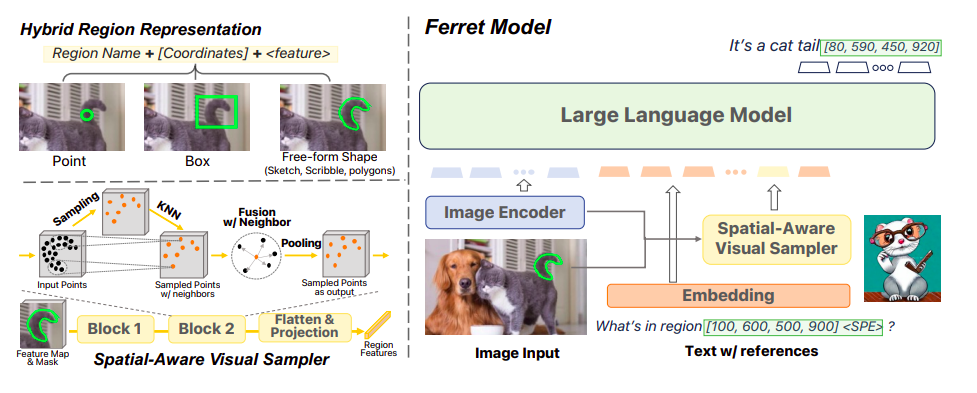
Figure 3: A general picture of the architecture for the suggested Ferret model. The suggested hybrid region representation and spatially aware visual sampler are shown on the left. The overall model architecture (right). The image encoder is the only parameter that cannot be trained.
However, it is impractical to represent a variety of regional forms, such as strokes, scribbles, or intricate polygons, with a single point or a box of coordinates. These forms are necessary for more accurate and all-encompassing human-model interaction. To address this issue, they also suggest a spatial-aware visual sampler to acquire the optical characteristics for areas in any form, accounting for the variable sparsity in those shapes. The visual areas in the input are then represented in Ferret using a hybrid region representation made up of discrete coordinates and continuous visual characteristics. With the techniques mentioned above, Ferret can handle input that combines free-form text and referenced areas, and it can ground the specified items in its output by automatically creating the coordinates for each groundable object and text.
As far as they know, Ferret is the first application to handle inputs from MLLMs with free-formed regions. They gather GRIT, a Ground-and-Refer Instruction-Tuning dataset of 1.1M samples, to create the refer-and-ground capabilities in Ferret open-vocabulary, instruction-following, and resilience. GRIT has various layers of spatial knowledge, including descriptions of regions, connections, objects, and complicated Reasoning. It contains data that combines location and text in both the input and the output, as well as location-in textout (referring) and text-in location-out (grounding). With the help of carefully crafted templates, most of the dataset is transformed from current vision(-language) tasks like object identification and phrase grounding to instruction-following.
To aid in training an instruction-following, open-vocabulary refer-and-ground generalist, 34K refer-and-ground instruction-tuning chats are also gathered using ChatGPT/GPT-4. They also do spatially aware negative data mining, which enhances model robustness. The ferret possesses high open-vocabulary spatial awareness and localization ability. It performs better when measured against traditional referencing and grounding activities. More than that, they think refer-and-ground capabilities should be incorporated into daily human discussions, for example, when individuals refer to something unfamiliar and inquire about its function. To assess this new skill, they present the Ferret-Bench, which covers three new types of tasks: Referring Description, Referring Reasoning, and Grounding in Conversation. They compare Ferret to the finest MLLMs already in use and find that it can outperform them by an average of 20.4%. Ferret also has the remarkable ability to reduce object hallucinations.
They have made three different contributions overall. (i) They suggest Ferret, which enables fine-grained and open-vocabulary reference and grounding in MLLM. Ferret employs a hybrid region representation outfitted with a unique spatial-aware visual sampler. (ii) they create GRIT, a large ground-and-refer instruction tuning dataset for model training. It also includes extra spatial negative examples to strengthen the model’s resilience. To evaluate tasks simultaneously needing referring/grounding, semantics, knowledge, and Reasoning, they create the Ferret-Bench (iii). Their model performs better than others in various activities and has less object hallucination.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.