Researchers from Cornell Introduce Quantization with Incoherence Processing (QuIP): A New AI Method based on the Insight that Quantization Benefits from Incoherent Weight and Hessian Matrices
Improvements in areas such as text creation, few-shot learning, reasoning, and protein sequence modelling have been made possible by large language models (LLMs). Due to their enormous scale, these models might have hundreds of billions of parameters, necessitating complex deployment strategies and inspiring study into efficient inference techniques.
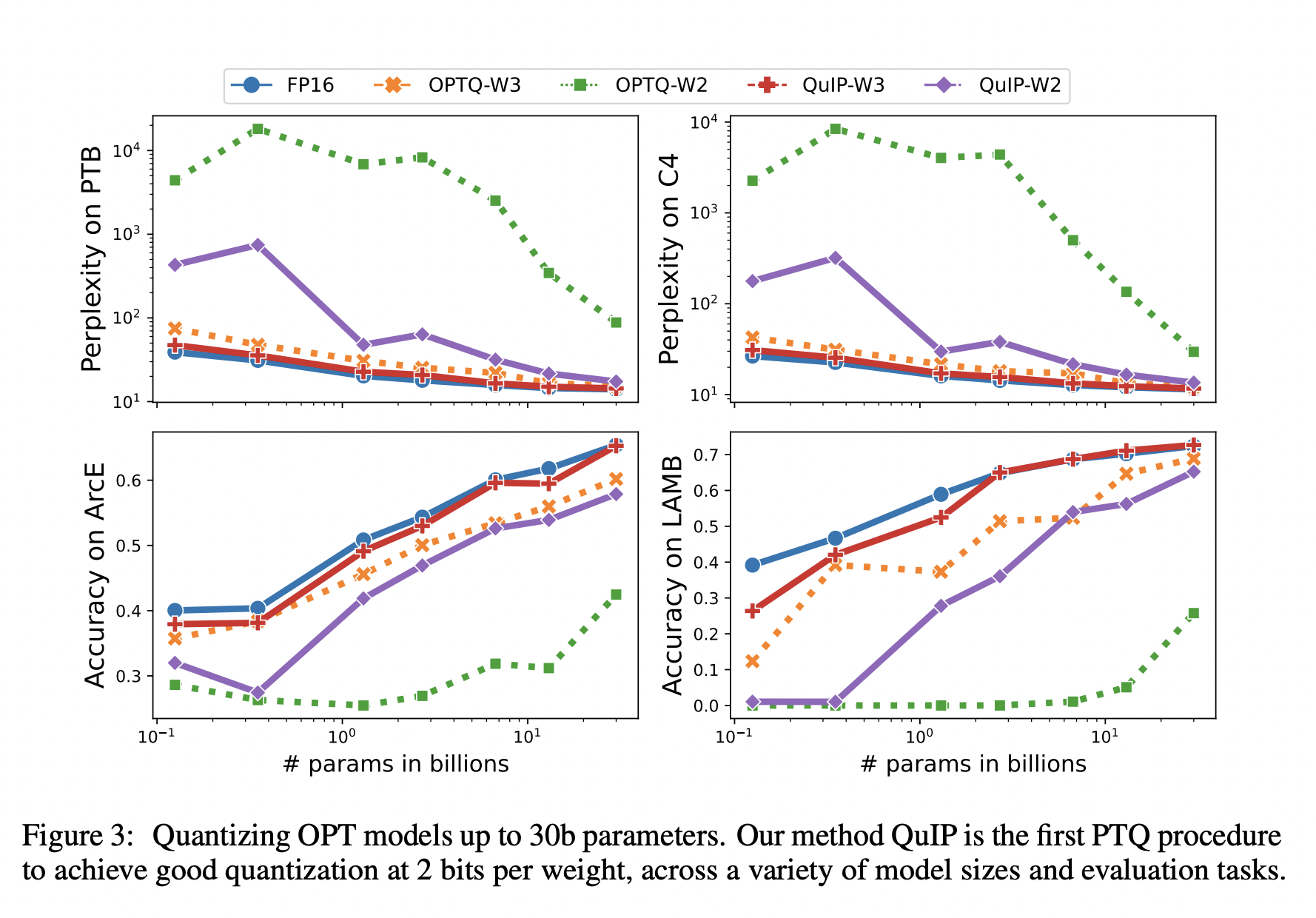
New research by Cornell University quantizes LLM parameters after training to boost performance in real-world scenarios. Their key insight is that it is easier to adaptively round the weights to a finite set of compressed values when the weight and proxy Hessian matrices are incoherent. Intuitively, this is because both the weights themselves and the directions in which it is important to have good rounding accuracy are not too large in any one coordinate.
Using this insight, the researchers create two-bit quantization techniques that are both theoretically sound and scalable to LLM-sized models. Based on this realization, they provide a novel technique called quantization with incoherence processing (QuIP).
There are two phases to QuIP:
- An efficient pre- and post-processing that ensures the Hessian matrices are incoherent by multiplying them by a Kronecker product of random orthogonal matrices.
- An adaptive rounding procedure that minimizes a quadratic proxy objective of the error between the original weights and the quantized weights using an estimate of the Hessian. “Incoherence processing” refers to both the initial processing phase and the final processing phase of the proposed method.
In addition to their practical implementation, they provide a theoretical study, the first of its kind for a quantization algorithm that scales to LLM-sized models, investigates the impact of incoherence and demonstrates the superiority of the quantization procedure relative to a broad category of rounding techniques. This study also presents the first theoretical analysis for OPTQ, an earlier technique, showing that QuIP without incoherence processing yields a more efficient implementation of that method.
The empirical results show that incoherence processing significantly enhances large-model quantization, particularly at higher compression rates, and results in the first LLM quantization approach to achieve usable results with only two bits per weight. Small gaps between 2-bit and 4-bit compression are observed for large LLM sizes (>2B parameters), and these gaps shrink further with model size, suggesting the possibility of accurate 2-bit inference in LLMs.
Interactions between transformer blocks, or even between layers within a block, are not taken into account by the proxy objective. The team state that the benefits of including such interactions at this scale and whether or not they are worth the computational effort are currently unknown.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.