Researchers From Google and Georgia Tech Introduce DiffSeg: A Straightforward Post-Processing AI Method for Creating Segmentation Masks
The objective of the computer vision task known as semantic segmentation is to assign a class or object to each pixel in an image. A dense pixel-by-pixel segmentation map of a picture, with each pixel corresponding to a particular type or object, is what is intended. Many subsequent processes rely on it as a precursor, including image manipulation, medical imaging, autonomous driving, etc. Zero-shot segmentation for images with unknown categories is far more difficult than supervised semantic segmentation, where a target dataset is given, and the categories are known.
A remarkable zero-shot transfer to any images is achieved by training a neural network with 1.1B segmentation annotations, as demonstrated in the recent popular work SAM. This is a significant step in ensuring that segmentation may be used as a building block for various tasks rather than being constrained to a specific dataset with predefined labels. However, it’s expensive to collect labels for every pixel. For this reason, exploring unsupervised and zero-shot segmentation techniques in the least constrained situations (i.e., no annotations and no prior knowledge of the target) is of significant interest in research and production.
Researchers from Google and Georgia Tech propose harnessing the strength of a stable diffusion (SD) model to build a universal segmentation model. Recently, stable diffusion models have generated high-resolution images with optimal prompting. In a diffusion model, it is plausible to assume the presence of data about object clusters.
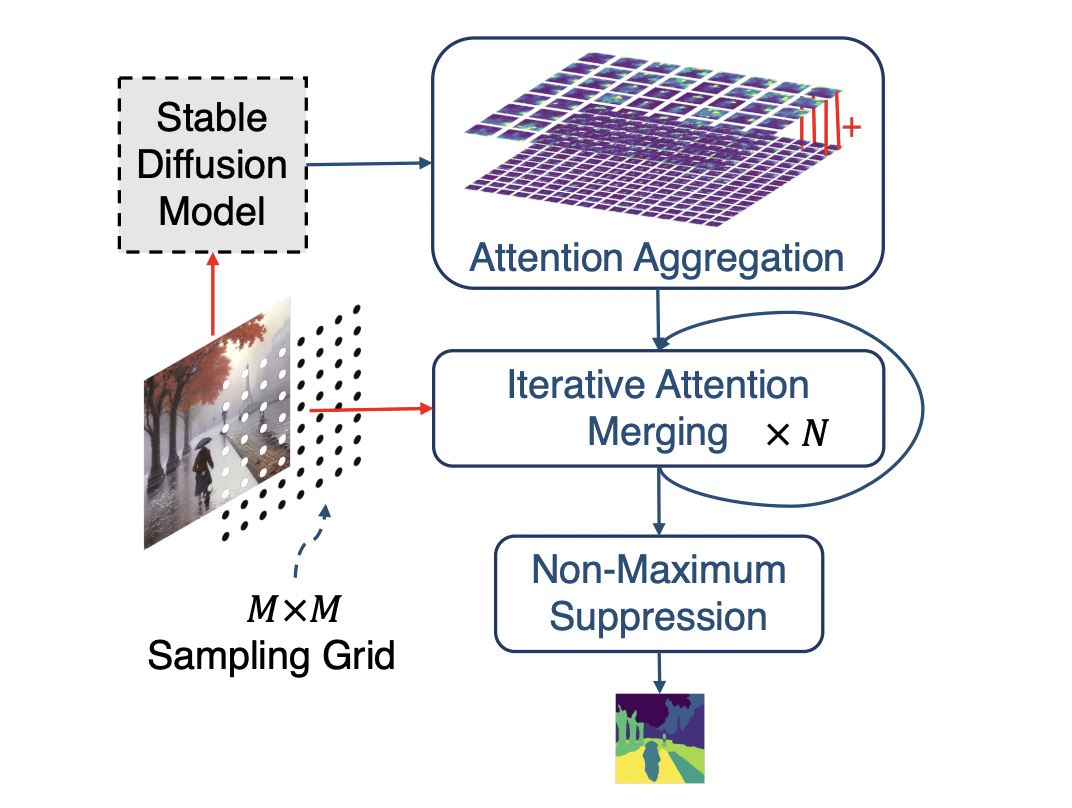
Since the self-attention layers in a diffusion model produce attention tensors, the team introduced DiffSeg, a straightforward yet effective post-processing method for creating segmentation masks. The algorithm’s three primary parts are attention aggregation, attention merging on an iterative basis, and non-maximal suppression. DiffSeg uses an iterative merging technique that begins with sampling a grid of anchor points to aggregate the 4D attention tensors in a spatially consistent manner, thus preserving visual information across several resolutions. Sampled anchors serve as jumping-off points for attention masks that merge similar objects. KL divergence determines the degree of similarity between two attention maps, which controls the merging process.
DiffSeg is a popular alternative to common clustering-based unsupervised segmentation algorithms because it is deterministic and does not require an input of the number of clusters. DiffSeg can take an image as input and generate a high-quality segmentation without any prior knowledge or specialized equipment (as SAM does).
Despite using fewer auxiliary data than previous efforts, DiffSeg achieves better results on both datasets. The researchers evaluate DiffSeg on two widely-used datasets: COCO-Stuff-27 for unsupervised segmentation and Cityscapes, a dedicated self-driving dataset. Compared to a previous unsupervised zero-shot SOTA method, the proposed method improves upon it by an absolute 26% pixel accuracy and 17% in mean IoU on COCO-Stuff-27.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.