Researchers from Grammarly and the University of Minnesota Introduce CoEdIT: An AI-Based Text Editing System Designed to Provide Writing Assistance with a Natural Language Interface
Large language models (LLMs) have made impressive advancements in generating coherent text for various activities and domains, including grammatical error correction (GEC), text simplification, paraphrasing, and style transfer. One of the emerging skills of LLMs is their ability to generalize and perform tasks that they have never seen before. To achieve this, LLMs are fine-tuned on instructions in an instruction-tuning process. This reduces the need for few-shot exemplars as the models become more proficient at understanding and following instructions.
One of the biggest difficulties for writers is editing their work to meet the requirements and limitations of their assignment. This can be challenging, even for experienced authors. To help overcome this, text editing benchmark tasks can be used to fine-tune the text editing capabilities of models. While previous studies have attempted to develop general-purpose text editing models using LLMs, their effectiveness, performance, and usability are often limited by factors such as unavailability or lack of task-specific datasets. Therefore, instruction tuning is essential to improve the overall quality of the text editing process.
Researchers from Grammarly (Vipul Raheja and Dhruv Kumar) and the University of Minnesota (Ryan Koo and Dongyeop Kang) introduce CoEdIT, an AI-based text editing system designed to provide writing assistance with a natural language interface. CoEdIT may be used as a writing assistant that can add, delete or change words, phrases, and sentences. CoEdIT meets syntactic, semantic, and stylistic edit criteria with state-of-the-art performance on several text editing benchmarks. The research group has demonstrated that CoEdIT can further generalize to make modifications along several dimensions in a single turn, even for unseen, adjacent, and composite instructions. They find that by adhering to natural language guidelines, CoEdIT can help authors with many facets of the text rewriting process.
The main contributions of the paper are as follows:
- The research team attained state-of-the-art performance on three stylistic editing tasks (paraphrasing, neutralization, and formality style transfer) in addition to GEC, text simplification, sentence fusion, and iterative text editing.
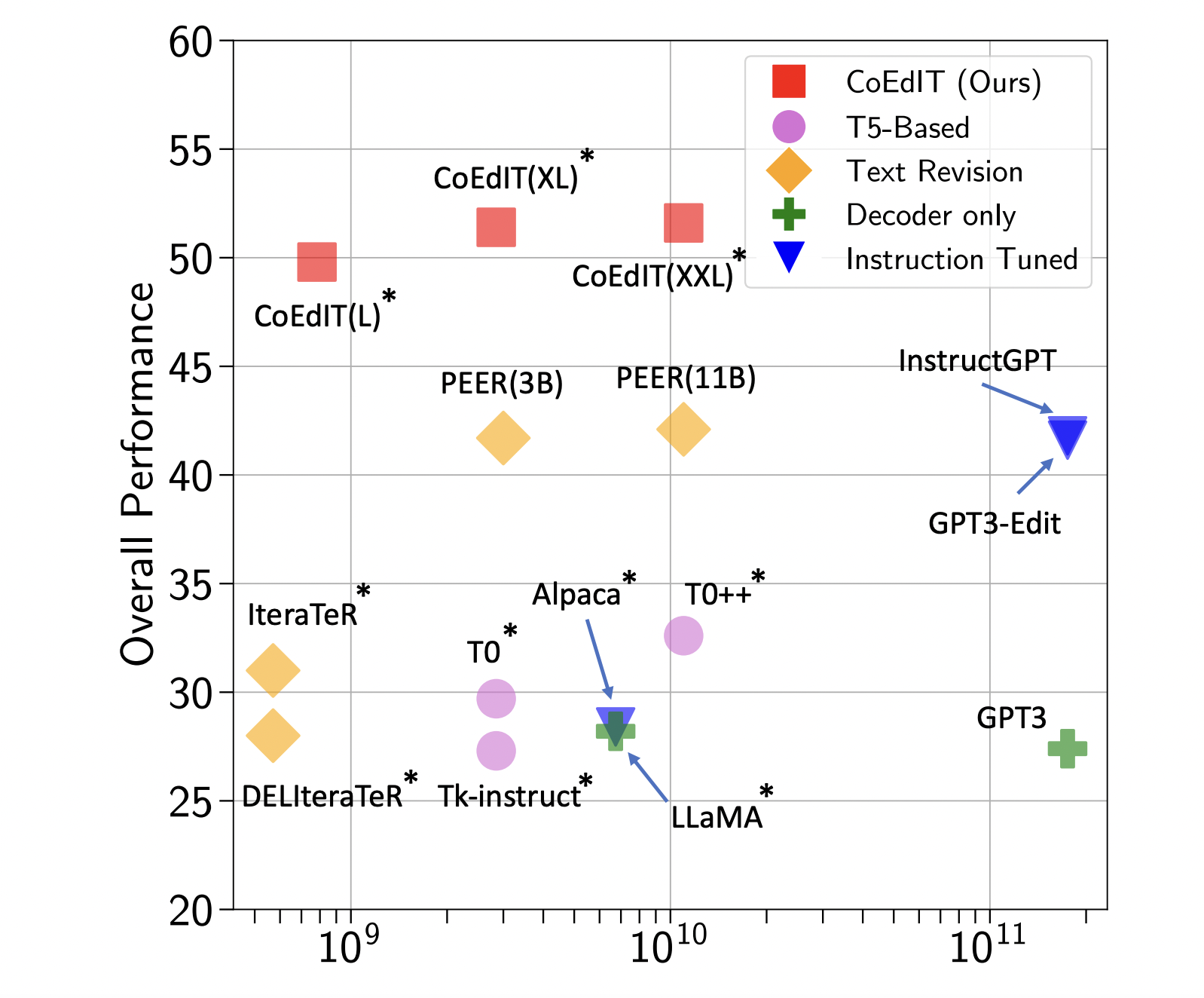
- The research team discovered that, on both manual and automatic assessments, even their smallest instruction-tuned model performs better than other supervised text editing, instruction-tuned, and general-purpose LLMs with roughly 60 times as many parameters.
- Their data and models are publicly available.
- CoEdIT generalizes effectively to new, neighboring jobs not noticed during fine-tuning, and composite instructions with multiple task descriptions.
They want to answer the following research inquiries:
- RQ1: Can CoEdIT follow text editing guidelines and provide high-quality changes for various tasks?
- RQ2: Can CoEdIT generalize to carry out edits for novel text editing instructions?
- RQ3: Does CoEdIT help human authors write more effectively and efficiently?
First, they evaluate a baseline with no edits, in which the result is just a copy of the original input without any changes. When used for tasks like GEC, where the goal output and input mostly overlap, this method does rather well. Additionally, they evaluate current text editing LLMs that need to be adapted using instruction-specific data. In particular, they compare their FLAN-T5 models’ main alternatives, the T52 models, to understand the impact of task-specific fine-tuning. Additionally, they compare their models with IteraTeR and DELIteraTeR, two models that have demonstrated superior performance on various text editing tasks.
Their comparisons with instruction-tuned LLMs make up a significant subset:
- The primary comparison they make is with PEER, which is based mostly on the T5 LM-Adapted version. They compare against PEER-EDIT (3B and 11B versions) since their work aims to improve the quality of revisions.
- The LM Adapted version of T5 serves as the starting point for T0, T0++, and Tk-Instruct, which are then adjusted using the PromptSource and Super-NaturalInstructions datasets in that order.
- They also compare InstructGPT, a form of GPT3 fine-tuned via reinforcement learning, on a huge dataset of instructions and human-written outputs.
- Alpaca is an instruction-tuned version of the LLaMA-7B model trained on 52000 instructions following demos provided by GPT-3.4.
- GPT-3.5, often known as ChatGPT, is an enhanced InstructGPT version tailored for conversation. They use the OpenAI API for all activities related to inference.
- GPT-3 also provides a text editing API (GPT3-Edit), which is precisely analogous to the tasks they train CoEdIT on since it may be used for editing tasks rather than completion ones.
- Meta AI’s general-purpose language model, LLaMA, was trained solely using data that was made accessible to the public. They use the 7B model because of limitations in computation. Unless otherwise indicated, greedy decoding was used to create the outputs of all models.
They make comparisons in two settings, zero-shot and few-shot, against LLMs without instruction tuning.
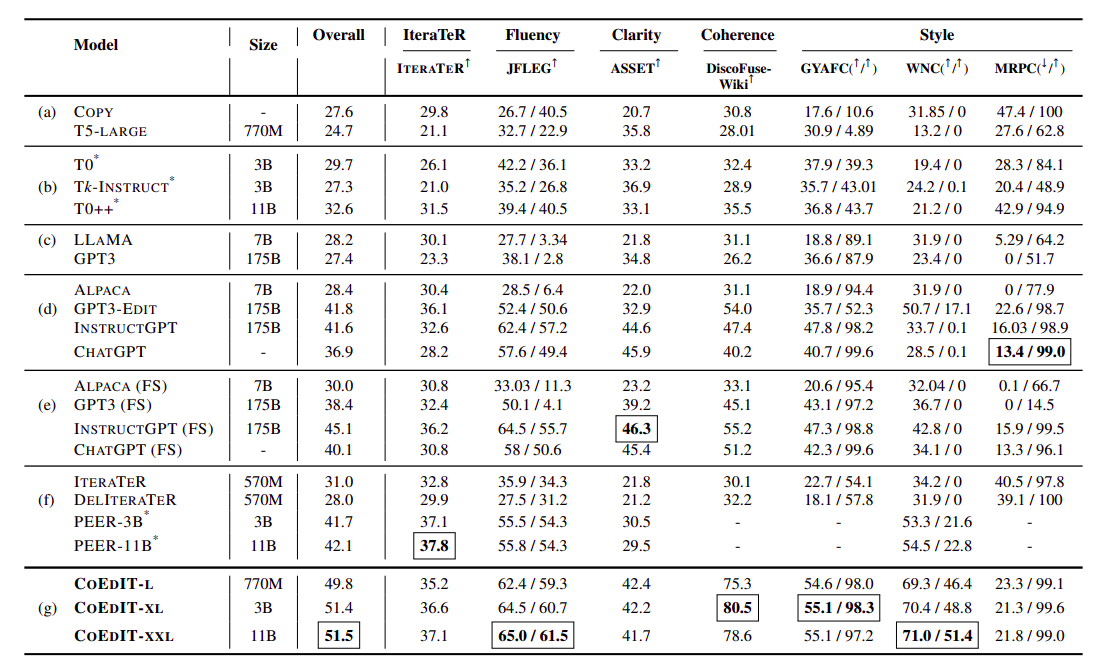
Table 1 answers Research Question 1 by comparing CoEdIT’s performance with other models in various text editing tasks. They start by presenting the findings from the most well-known evaluation sets here, and then in Table 2, they give extra results (i.e., subtasks and other datasets). The models are divided into seven categories. While the second group (b) consists of instruction-fine-tuned T5-based models on non-text-editing tasks, the first group (a) consists of the copy baseline and T5-Large baseline fine-tuned using prefix-tuning (each data point is prefixed with task-specific tags rather than instructions). They discovered that CoEdIT performs significantly better on all tasks than these models. The following two sets (c, d) display several LLMs that were assessed in a zero-shot scenario and that range in size from 7 billion to 175 billion parameters. Group (d) models are instruction-tuned, whereas group (c) models are decoder-only.
They discovered that CoEdIT performs better on most of the tasks than models that were many times bigger, such as ChatGPT and InstructGPT, and better than all LLMs similar to its model size (like Alpaca and LLaMA). This suggests that rather than scaling model size, it would be better to densify the task/instruction space because the existing general-purpose and instruction-tuned models are underfitted. While Alpaca and T5-based models (Tk-Instruct, T0, T0++) have demonstrated great performance in the past on zero-shot tasks, these models perform less well than CoEdIT. Additionally, they observe that for more difficult tasks, such as those falling within the Style intent category, the decoder-only models (like GPT-3 and LLaMA) frequently repeat the input.
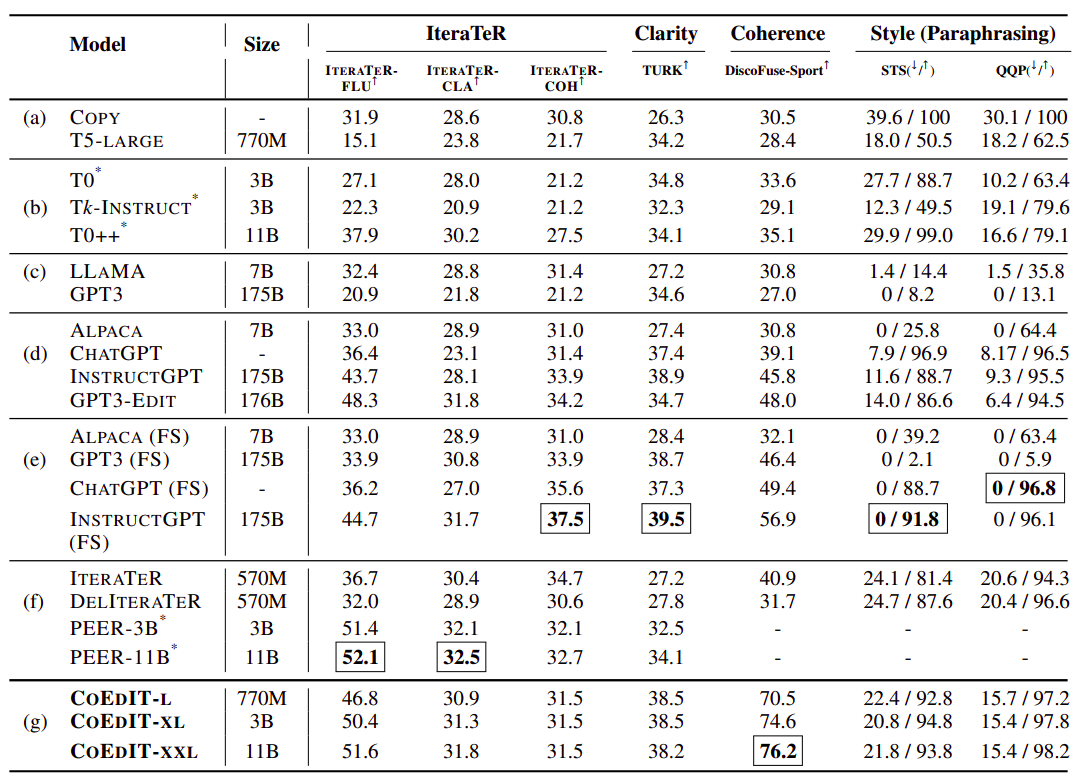
This is because the models either repeated the input sentence or produced a continuation that had nothing to do with the task, which may be explained by their inability to comprehend the requested task. Subsequently, in group (e), they assess the LLMs in a few-shot configuration. They conduct these experiments in a 4-shot evaluation setup. Example inputs were created by randomly selecting four inputs from the CoEdIT dataset for each job, ensuring every example set would fit inside the input window for every model. The instructive prompt has the input sentence prepended to it, along with its matching updated reference. They do few-shot evaluations of three instruction-tuned LLMs (InstructGPT, ChatGPT, and Alpaca) and decoder-only LLMs (GPT-3).
They note that, except MRPC for GPT-3, providing explicit examples enhances performance in all models for all tasks. This might be the case because GPT-3 repeats its generations similarly, leading to low semantic similarity and a poor BLEU score. Since scores tend to remain consistent across tasks, they don’t offer any results for GPT3-Edit in the few-shot situation, which suggests that GPT3-Edit’s in-context learning skills might need to be stronger. Overall, they discover that for most tasks, even their smallest, 770 million parameter model can compete with LLMs evaluated in a few-shot situation.
The research team contrasts their models with task-specific text editing models like IteraTeR, DELIteraTeR, and PEER in the last group (f). Because IteraTeR and DELIteraTeR only prepended instructions to the inputs and were trained with task-specific tags, their performance is significantly poorer than the scores in the original research. Moreover, they were not prepared to follow instructions; instead, they were trained using BART and Pegasus, which have separate pre-training objectives related to summarization. CoEdIT outperforms PEER on average in all documented evaluations except the IteraTeR benchmark. Since PEER utilizes Wikipedia as the source of instructional edit data, this is mostly due to the difference in task-specific fine-tuning.
While CoEdIT attains cutting-edge results on several text editing benchmarks, it possesses certain constraints with its methodology and assessment techniques. Like most previous efforts, task-specific fine-tuning primarily targets sentence-level editing assignments. Its efficacy on much longer text sequences more suited to real-world editing conditions has yet to be determined. Furthermore, the primary focus of their system is on non-meaning-altering text alterations.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Thanks to the Grammarly Research Team for the thought leadership/ Educational article. The Grammarly Research Team has supported us in this content/article
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.