Researchers From Idiap Research Institute Propose ‘HyperMixer’: An MLP-Based Green AI Alternative To Transformers

In recent years, transformer topologies have advanced the state-of-the-art in a wide range of natural language processing (NLP) activities. Vision transformers (ViT) are now being used more frequently in computer vision. However, because of the quadratic complexity of transformers over input length, they consume a lot of energy, which limits their research and development and industrial deployment.
An MLP-based Green AI Replacement to Transformers presents a novel Multi-Layer Perceptron (MLP) model, HyperMixer, as an energy-efficient alternative to transformers that preserves similar inductive biases, according to a recent article published by the Idiap Research Institute in Switzerland.
The researchers demonstrate that HyperMixer may achieve performance comparable to transformers while significantly reducing processing time, training data, and hyperparameter tuning expenses.
HyperMixer is a new all-MLP model with inductive biases inspired by transformers. On the GLUE benchmark, HyperMixer’s performance was compared to competitors’. HyperMixer learns attention patterns similarly to transformers, as demonstrated by this ablation.
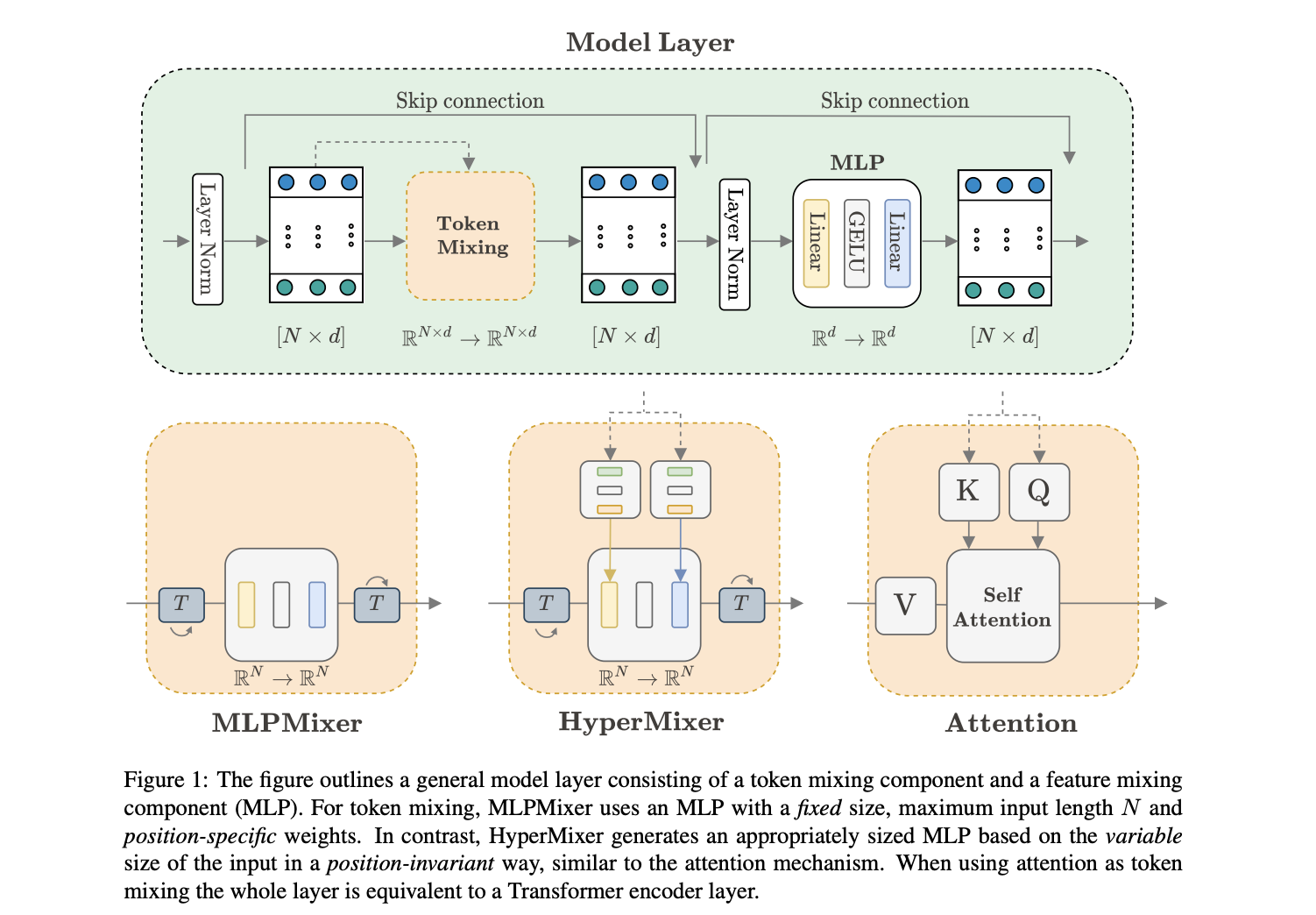
Multi-layer perceptrons (MLPs) generate interest in the computer vision community as a simpler alternative to transformers. Although MLPMixer’s appropriateness as a transformer replacement is doubted because its token mixing MLP learns a fixed-size set of position-specific mappings, potentially separating it from the inductive biases required to tackle NLP problems.
The proposed HyperMixer uses hypernetworks to dynamically generate a token mixing MLP, overcoming two issues that traditional MLPs face: 1) The input does not have to be one-dimensional. 2) The hypernetwork represents the interaction of tokens with standard weights across all positions in the input, ensuring that the model can learn generalizable rules that describe the structural relationship between entities. This is also known as systematicity.
HyperMixer learns to generate a variable-size collection of mappings in a position-invariant manner like the attention process in transformers. Still, it also reduces the quadratic complexity to linear, giving it a competitive alternative for training on longer inputs.

HyperMixer was compared against baseline models such as MLPMixer, gMLP, transformers, and FNet on many different datasets. On all datasets (except SST-2, where no model clearly wins), HyperMixer outperforms MLPMixer and all non-transformer baselines on NLP tasks, especially those that require modeling token interactions.
Although HyperMixer includes inductive biases similar to transformers, it is theoretically and computationally easier. It can be viewed as a Green AI alternative to transformers, as it reduces the cost of single-example processing time, dataset size requirements, and hyperparameter adjustment. HyperMixer learns patterns that are remarkably comparable to transformers’ self-attention mechanisms due to its inductive biases that resemble those of transformers.
Because of the resource-intensive nature of today’s substantial pre-trained transformer language models, the machine learning research community is looking at methods that will lead to a more Green AI paradigm. The suggested HyperMixer is a significant step forward in this approach, displaying the same inductive biases that have made transformers so successful for natural language interpretation but at a far lower cost.
Paper: https://arxiv.org/pdf/2203.03691.pdf
Suggested
Credit: Source link
Comments are closed.