Researchers from Inception, MBZUAI, and Cerebras Open-Sourced ‘Jais’: The World’s Most Advanced Arabic Large Language Model
Large language models like GPT-3 and their impact on various aspects of society are a subject of significant interest and debate. Large language models have significantly advanced the field of NLP. They have improved the accuracy of various language-related tasks, including translation, sentiment analysis, summarization, and question-answering. Chatbots and virtual assistants powered by large language models are becoming more sophisticated and capable of handling complex conversations. They are used in customer support, online chat services, and even companionship for some users.
Building Arabic Large Language Models (LLMs) presents unique challenges due to the characteristics of the Arabic language and the diversity of its dialects. Similar to large language models in other languages, Arabic LLMs may inherit biases from the training data. Addressing these biases and ensuring the responsible use of AI in Arabic contexts is an ongoing concern.
Researchers at Inception, Cerebras, and Mohamed bin Zayed University of Artificial Intelligence ( UAE ) introduced Jais and Jais-chat, a new Arabic language-based Large Language Model. Their model is based on the GPT-3 generative pretraining architecture and uses only 13B parameters.
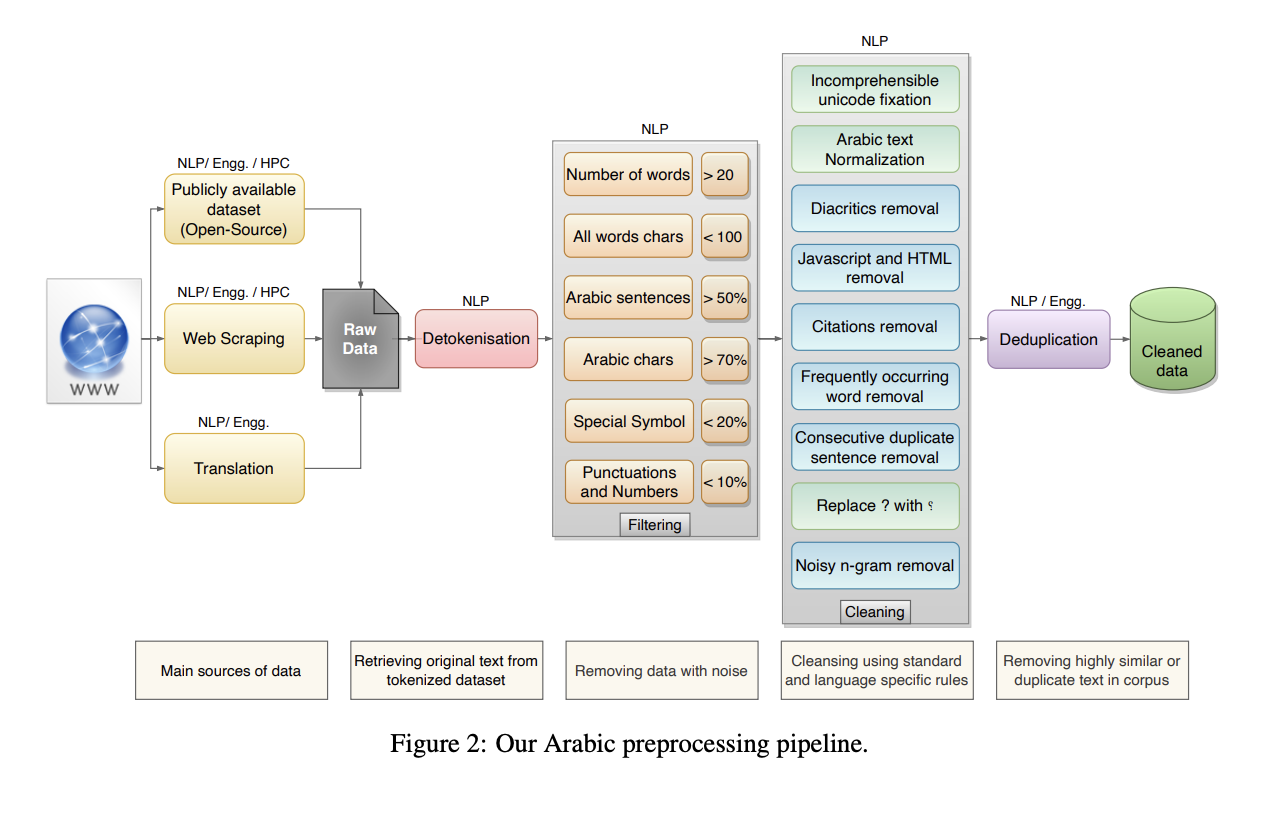
Their primary challenge was to obtain high-quality Arabic data for training the model. Compared to English data, which has corpora of up to two trillion tokens, they were readily available, but the Arabic corpora were significantly smaller. Corpora are large, structured collections of texts used in linguistics, natural language processing (NLP), and text analysis for research and language model training. Corpora serve as valuable resources for studying language patterns, semantics, grammar, and more.
They trained bilingual models to resolve this by augmenting the limited Arabic pretraining data with abundant English pretraining data. They pretrained Jais on 395 billion tokens, including 72 billion Arabic and 232 billion English tokens. They developed a specialized Arabic text processing pipeline that includes thorough data filtering and cleaning to produce high-quality Arabic data.
They say that their model’s pretrained and fine-tuned capabilities outperform all known open-source Arabic models and are comparable to state-of-the-art open-source English models that were trained on larger datasets. Considering the inherent safety concerns of LLMs, they further fine-tune it with safety-oriented instructions. They added extra guardrails in the form of safety prompts, keyword-based filtering, and external classifiers.
They say that Jais represents an important evolution and expansion of the NLP and AI landscape in the Middle East. It advances the Arabic language understanding and generation, empowering local players with sovereign and private deployment options and nurturing a vibrant ecosystem of applications and innovation; this work supports a broader strategic initiative of digital and AI transformation to usher in an open, more linguistically inclusive, and culturally-aware era.
Check out the Paper and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.