Researchers From INRIA France Propose ‘Pythae’: An Open-Source Python Library Unifying Common And State-of-the-Art Generative AutoEncoder (GAE) Implementations

Variational AutoEncoders (VAE) have grown in popularity due to their scalability and computational efficiency. It is widely used in voice modeling, clustering, and data augmentation applications. This research represents a versatile open-source python library (Pythae). This library’s main goal is to provide a uniform implementation and a specialized framework for using generative autoencoder models in a simple, reproducible, and reliable manner. Additionally, this research improves the prior results with a better lower bound, encourages disentanglement, and rectifies the distance amongst distributions.
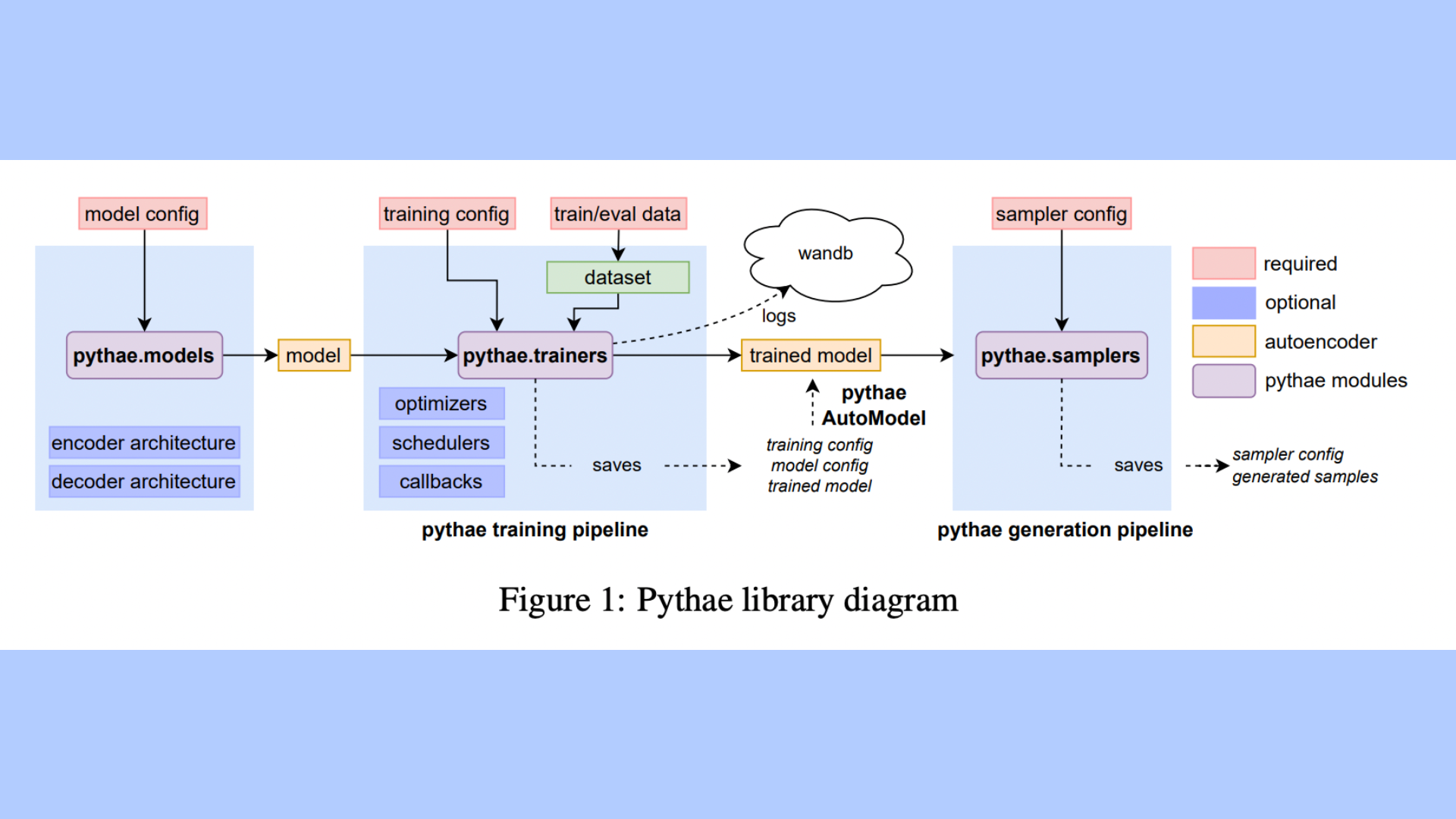
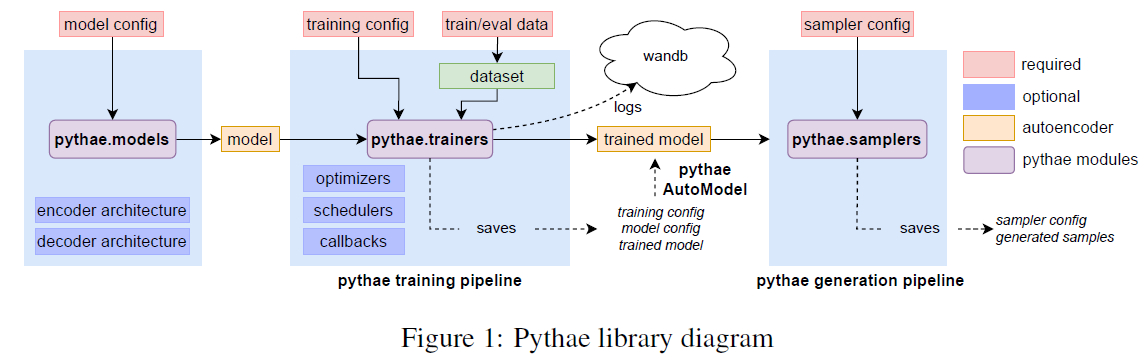
Pythae’s pipelines having just a few lines of code make it possible to create new data or train an autoencoder model. To start a model training or creation primarily uses the Pytorch framework and requires basic hyper-parameter tuning and data in the form of arrays or tensors. Additionally, the library incorporates a user-friendly experimental tracking tool (wandb) that enables users to compare and track Pythae-launched runs. The basic architecture of Pythae library that illustrates training and generation is showcased in Fig. 1.
This library is used to conduct benchmark comparisons of developed models for image reconstruction and generation, latent vector classification and clustering, and image interpolation. Three standard image datasets recalled as MNIST, CIFAR, and CELEBA are utilized for this task.
This research carries experimentation on fixed latent dimensions and varying latent dimensions. For the MNIST, CIFAR10, and CELEBA datasets, the fixed part’s latent dimensions are set to 16, 256, and 64, respectively. The reconstruction results showcase that the autoencoder-based models seem to perform best for the reconstruction task. Also, it proves that integrating regularisation to the encoder attains improved performance in contrast to the regular AutoEncoder. One prime discovery of this experiment is that implementing ex-post density for the variational approach results in better generation metrics even with ten components of GMM.
Free-2 Min AI NewsletterJoin 500,000+ AI Folks
In comparison to GMM, experimentation is done with more complex density estimators. However, the results did not outperform the GMM approach. In GMM, several components play a vital role; hence, for MNIST and CIFAR it is set to 10. If the number of components is increased, it will result in overfitting, and if they are decreased, it will retrieve poor results. Compared to a standard VAE, models that explicitly encourage disentanglement in the latent space, such as the β-VAE and β-TC VAE, perform better in classification. In clustering, 100 separate runs of the k-means algorithm are performed, and mean accuracy is obtained. Here, models targeting disentanglement seem to be equaled by the original VAE. Also, the best outcomes appear to be achieved via adversarial strategies and other alternatives to the conventional VAE KL regularisation procedure. For interpolation, a starting and ending image in the test set of MNIST and CIFAR10 are chosen, and a linear interpolation is performed in the produced latent spaces between the two encoded images.
In varying latent dimensions, the same configurations are kept as fixed latent dimensions, with the latent space varying in the range [16; 32; 64; 128; 256; 512]. In this scenario, the optimal choice for all four tasks is the latent dimension of 16 to 32 on the MNIST dataset and 32 to 128 on the CIFAR10 dataset.
In conclusion, on the most frequent tasks, including reconstruction, generation, and classification, AE-based generative approaches produce the most outstanding results. However, they are susceptible to the selection of the latent dimension and don’t scale well on complex tasks such as interpolation.
This Article is written as a summary article by Marktechpost Staff based on the paper 'Pythae: Unifying Generative Autoencoders in Python A Benchmarking Use Case'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.