Researchers From Italy Propose A New AI Method Focussed on Unsupervised Feature Learning for MER (Multimodal Emotion Recognition)
The use of technology to assist humans or robots in recognizing emotions is a relatively new field of study and still challenging since perception depends on several factors such as age, gender, and cultural background, in addition to the lack of annotated data. The technique of detecting human emotion is known as emotion recognition.
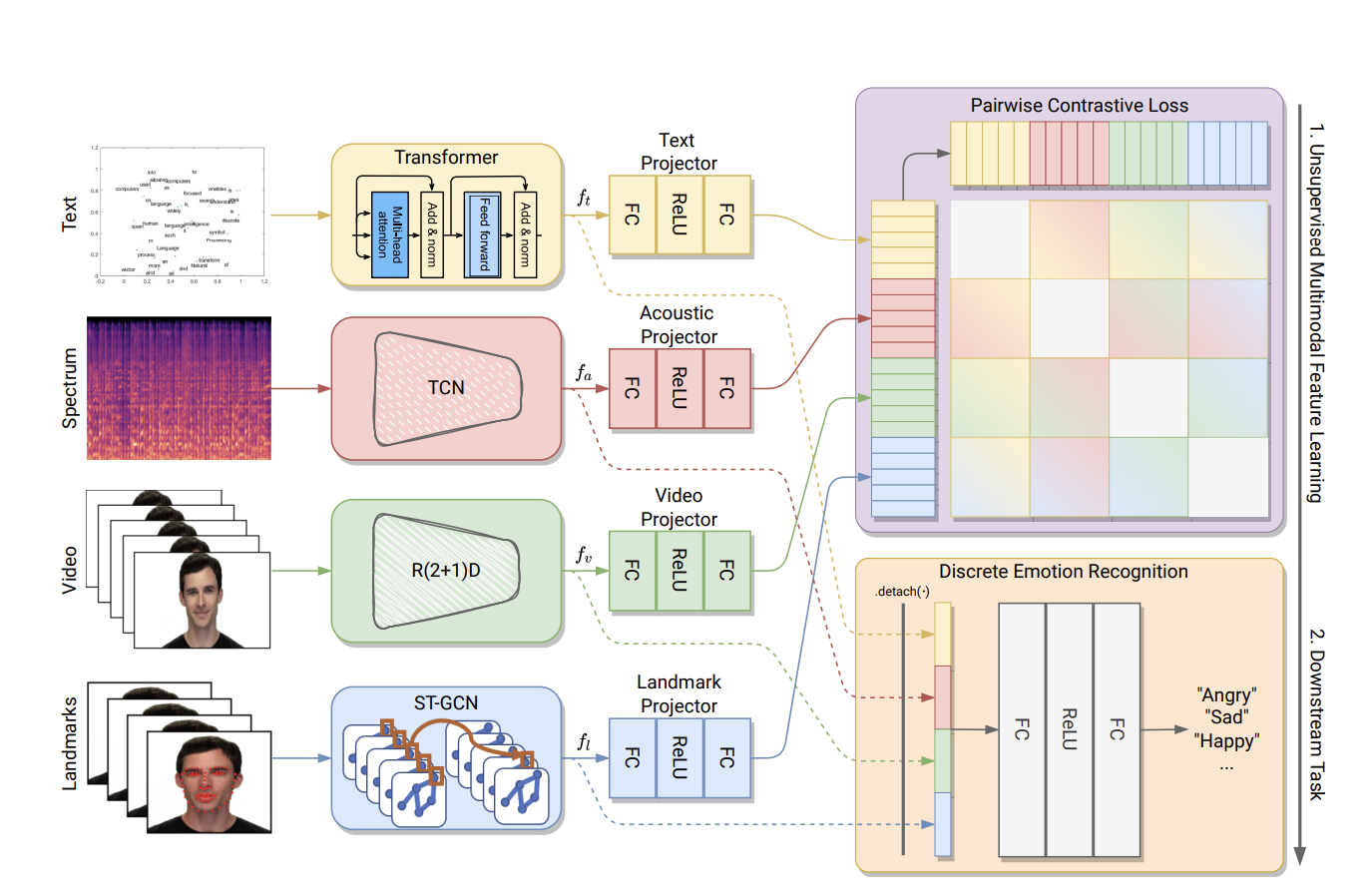
Several works introduced different approaches to performing the task of emotion recognition. Most of them principally focused on learning unimodal emotions by using a single modality. However, the technology generally performs best when integrating several modalities into the environment. A research team from Italy recently proposed a new multimodal architecture based on four unsupervised trained sub-networks. Each subnet processes a particular type of data such as text, visual (facial images and landmarks), and acoustic.
The novel approach is an end-to-end network that comes with four main ideas:
- It follows an unsupervised learning fashion to be functional without data annotation.
- Spatial data augmentation, modality alignment, numerous batch sizes, or epochs are unnecessary.
- Backbones pre-trained on emotion recognition tasks are unnecessary.
- A late data fusion is applied in the inference step.
Specifically, the model exploits four modalities in a contrastive learning framework. For a data sample described in multiple modalities, the target is to draw the embeddings of the same two modalities of different sequences away while pushing the embeddings of the same two modalities of the same sequence to be close. Since class labels are not used, the goal is to make the representations of the same sequence in different modalities similar to one another. When both are a part of the same data sample, feature embedding between one modality and another modality is carried out. In addition, the learned feature representations of the different modalities are concatenated only during the test phase. To perform the discrete emotion recognition task, the authors propose to utilize a 512-dimensional feature representation learned by each backbone. The learned features are merged, a multi-head attention mechanism is applied, then the overall feature representation is fed to a prediction layer that gives the emotion classes as output.
The authors elected different backbone for each modality. The choice of networks used was made according to a study of the state-of-the-art to implement the most appropriate model for each type of data, such as MTCNN for the facial images modality and TCN for the acoustic modality.
The databases used are RAVDESS for the speech part and CMU-MOSEI, the most used database in multimodal emotion recognition. Two evaluation metrics are used to evaluate the proposed model: weighted accuracy (w-ACC) and F1-measure.
During the experimental study, an ablation study demonstrated that when the fusion is carried out on the features extracted by the four sub-networks, the prediction is more efficient than the result given by each modality taken separately when trained following a supervised strategy. Combining the four streams also provides a more accurate result than when less than four sub-networks are used. The comparisons with state-of-the-art methods show that the new multimodal network suggested in this study is competitive with numerous sophisticated supervised existing approaches and even outperforms a few of them.
In this article, we presented a new network that was developed to perform the task of emotion recognition. It is a multimodal network that combines four streams, each processing a different type of data. The four data types used are text, facial images, landmark images, and acoustic data. The modalities were trained following an unsupervised approach thanks to a pairwise unsupervised contrastive Loss. The results proved the effectiveness of the new proposal, which even outperformed some supervised models.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'Multimodal Emotion Recognition with Modality-Pairwise Unsupervised Contrastive Loss'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.