Researchers from KAIST and Google introduced collaborative score distillation (CSD): an AI method that extends the singular of the text-to-image diffusion model for consistent visual synthesis
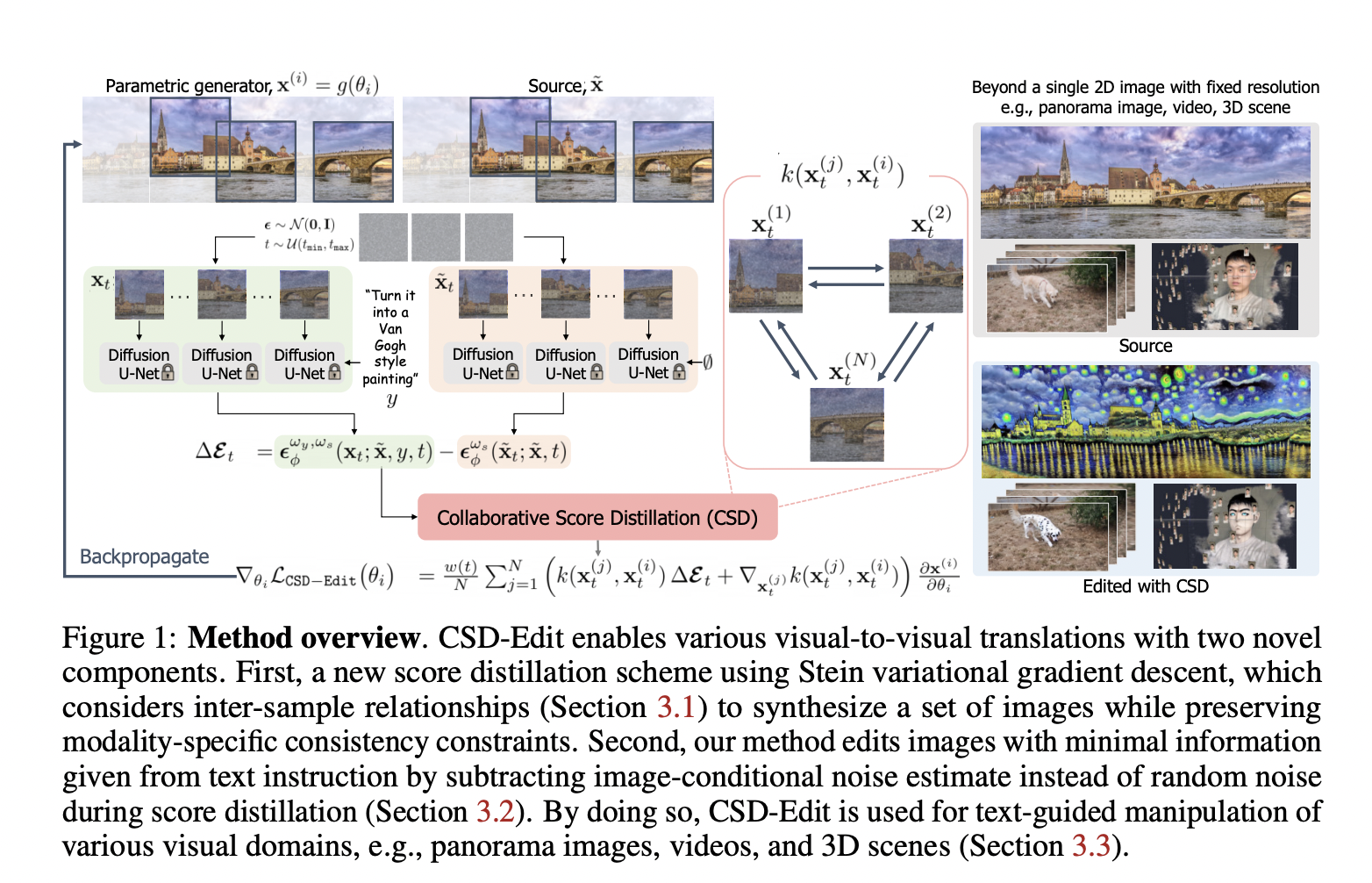
Text-to-image diffusion models have been built up by employing billions of image-text pairings and effective topologies, demonstrating amazing capabilities in synthesizing high-quality, realistic, and diversified pictures with the text provided as an input. They have also expanded into several applications, including image-to-image translation, controlled creation, and customization. One of the most recent uses in this area is the ability to extend beyond 2D pictures into other complex modalities without changing diffusion models by employing modality-specific training data. This study aims to address the challenge of using the knowledge of pre-trained text-to-image diffusion models to increasingly challenge high-dimensional visual generating tasks beyond 2D pictures without changing diffusion models utilizing modality-specific training data.
They begin with the hunch that many complex visual data, including films and 3D environments, may be represented as a collection of pictures restricted by consistency specific to a certain modality. For instance, a 3D scene is a collection of multi-view frames having view consistency, whereas a movie is a collection of frames with temporal consistency. Unfortunately, because their generative sampling method does not consider consistency when utilizing the image diffusion model, image diffusion models are not equipped with the capacity to guarantee consistency across a group of pictures for synthesis or editing. As a result, when picture diffusion models are applied to these complicated data without taking consistency into account, the outcome could be more coherent, as seen in Figure 1 (Patch-wise Crop), where it is clear where photos have been stitched together.

Such behaviors have been seen in video editing as well. Hence subsequent research has suggested adopting the picture diffusion model to address video-specific temporal consistency. Here, they draw attention to a novel strategy called Score Distillation Sampling (SDS), which uses the rich generative prior of text-to-image diffusion models to optimize any differentiable operator. By condensing the learned diffusion density scores, SDS frames the challenge of generative sampling as an optimization problem. While other researchers demonstrated SDS’s efficacy in producing 3D objects from the text using Neural Radiance Fields priors, which via density modeling assume coherent geometry in 3D space, it has yet to be investigated for the consistent visual synthesis of other modalities.
In this study, authors from KAIST and Google Research suggest Collaborative Score Distillation (CSD), a straightforward yet efficient technique that expands the text-to-image diffusion model’s potential for reliable visual synthesis. The key to their approach is twofold: first, they use Stein variational gradient descent (SVGD) to generalize SDS by having numerous samples share information gleaned from diffusion models to achieve inter-sample consistency. Second, they provide CSD-Edit, a powerful technique for consistent visual editing that combines CSD with the recently developed instruction-guided picture diffusion model Instruct-Pix2Pix.
They use a variety of applications, including panorama picture editing, video editing, and 3D scene reconstruction, to show how adaptable their methodology is. They demonstrate how CSD-alter can alter panoramic images with spatial consistency by maximizing several picture patches. Additionally, their method achieves a superior balance between instruction accuracy and source-target image consistency compared to previous approaches. In experiments with video editing, CSD-Edit reaches temporal consistency by optimizing numerous frames, leading to temporal frame-consistent video editing. They also use CSD-Edit to generate and edit 3D scenes, promoting uniformity across various viewpoints.
Check out the Paper and Project Page. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 800+ AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.