Researchers from Lawrence Livermore National Laboratory have Created an Open-Source Toolkit to Perform Machine Learning on the Energy Grid
As technology advances in this century, electricity usage increases as well. Well-advanced and expansive energy grids are being made to meet the demands, consisting of millions of smart meters. Smart meters are made with sensors that collect a wide range of data, from transformers to bus devices. So, to monitor and enhance the reliability and performance of various elements of the energy grid, all collected data must be aggregated and used to provide feedback to various decision-making factors. For example, frequent transformer faults, or fault in the distribution management system, that disrupts the workflow for several days would significantly be reduced using data in various detections and decision makings.
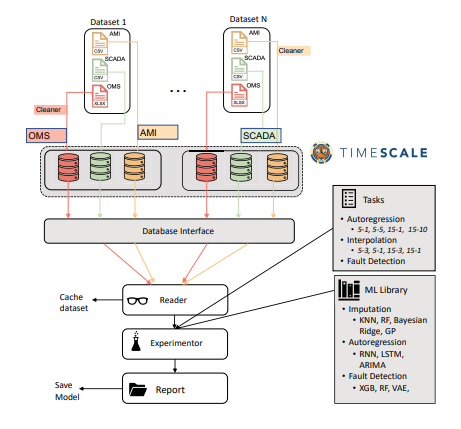
There are currently benchmark standards for electrical data acquisitions, from IEEE standard, as well as other standards like WAMS (Wide Area Monitoring System). WAMS provide several data collection and storage system for independent localities, namely AMI (Advanced Metering Infrastructure), OMS (Outage Management Systems), SCADA (Supervisory Control Data Acquisition), etc. So, a uniform system must enable researchers worldwide to perform various kinds of prediction or detection tasks that could be well-deployed across datasets and tasks.
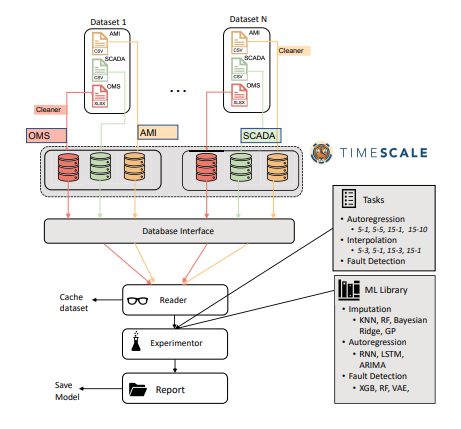
The researchers at Livermore Laboratory have developed an open-source library, “gridDS“, that would connect three key components. It’d first (a) collect and store data from various sources. Then it’d (b) model the data for various tasks, and then (c) apply ML models. For making the data pipeline, they have used SQL; python language, and Sklearn and Pytorch libraries for further ML pipeline. They have primarily focused on three tasks- (1) Autoregression, which is predicting future values given previous values; (2) Interpolation, which is fitting a curve and imputing missing values; and (3) Fault detection of any grid element. As the energy system dataset is so varied, consisting of several types of faults, including transformer faults to energy discharge, there is no uniform ML model for any task. Researchers must experiment and see which model works well in which scenario and region.
The library includes the capability to apply any framework for any task. It has several in-built ML algorithms which can be easily deployed for any task. Like, they have built RNNs, ARIMAs, etc., which can be used in Autoregression; Bayesian ridge regression, random forest regression, etc., which can be used for interpolation; and XGBoost, Variational Auto-encoders, etc., which can be used for fault detection. They have also compared the performance of different algorithms for various tasks and have shown that change in data horizon and data history significantly changes model performance.
This is the first library version that has been built, and it only contains primary ML and DL functionalities. So, in the future, it’s hoped that more advanced deep learning frameworks will be included in the library.
Github: https://github.com/xanderladd/gridds
Reference: https://techxplore.com/news/2022-08-open-source-data-science-toolkit-power.html
![]()
Asif Razzaq is an AI Journalist and Cofounder of Marktechpost, LLC. He is a visionary, entrepreneur and engineer who aspires to use the power of Artificial Intelligence for good.
Asif’s latest venture is the development of an Artificial Intelligence Media Platform (Marktechpost) that will revolutionize how people can find relevant news related to Artificial Intelligence, Data Science and Machine Learning.
Asif was featured by Onalytica in it’s ‘Who’s Who in AI? (Influential Voices & Brands)’ as one of the ‘Influential Journalists in AI’ (https://onalytica.com/wp-content/uploads/2021/09/Whos-Who-In-AI.pdf). His interview was also featured by Onalytica (https://onalytica.com/blog/posts/interview-with-asif-razzaq/).
Credit: Source link
Comments are closed.