Researchers From Max Plank Propose MIME: A Generative AI Model that Takes 3D Human Motion Capture and Generates Plausible 3D Scenes that are Consistent with the Motion
Humans are always interacting with their surroundings. They move about a space, touch things, sit on chairs, or sleep on beds. These interactions detail how the scene is set up and where the objects are. A mime is a performer who uses their comprehension of such relationships to create a rich, imaginative, 3D environment with nothing more than their body movements. Can they teach a computer to mimic human actions and make the appropriate 3D scene? Numerous fields, including architecture, gaming, virtual reality, and the synthesis of synthetic data, might benefit from this technique. For instance, there are substantial datasets of 3D human motion, such as AMASS, but these datasets seldom include details on the 3D setting in which they were collected.
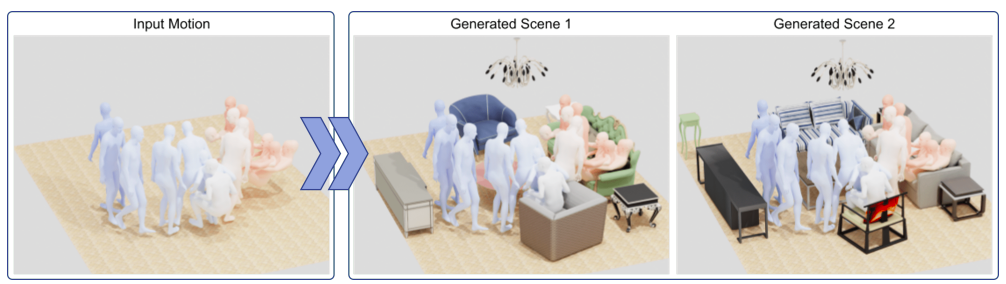
Could they create believable 3D sceneries for all the motions using AMASS? If so, they could make training data with realistic human-scene interaction using AMASS. They developed a novel technique called MIME (Mining Interaction and Movement to infer 3D Environments), which creates believable interior 3D scenes based on 3D human motion to respond to such inquiries. What makes it possible? The fundamental assumptions are as follows: (1) Human motion across space denotes the absence of items, essentially defining areas of the picture devoid of furniture. Additionally, this limits the kind and location of 3D objects when in touch with the scene; for instance, a sitting person must be seated on a chair, sofa, bed, etc.
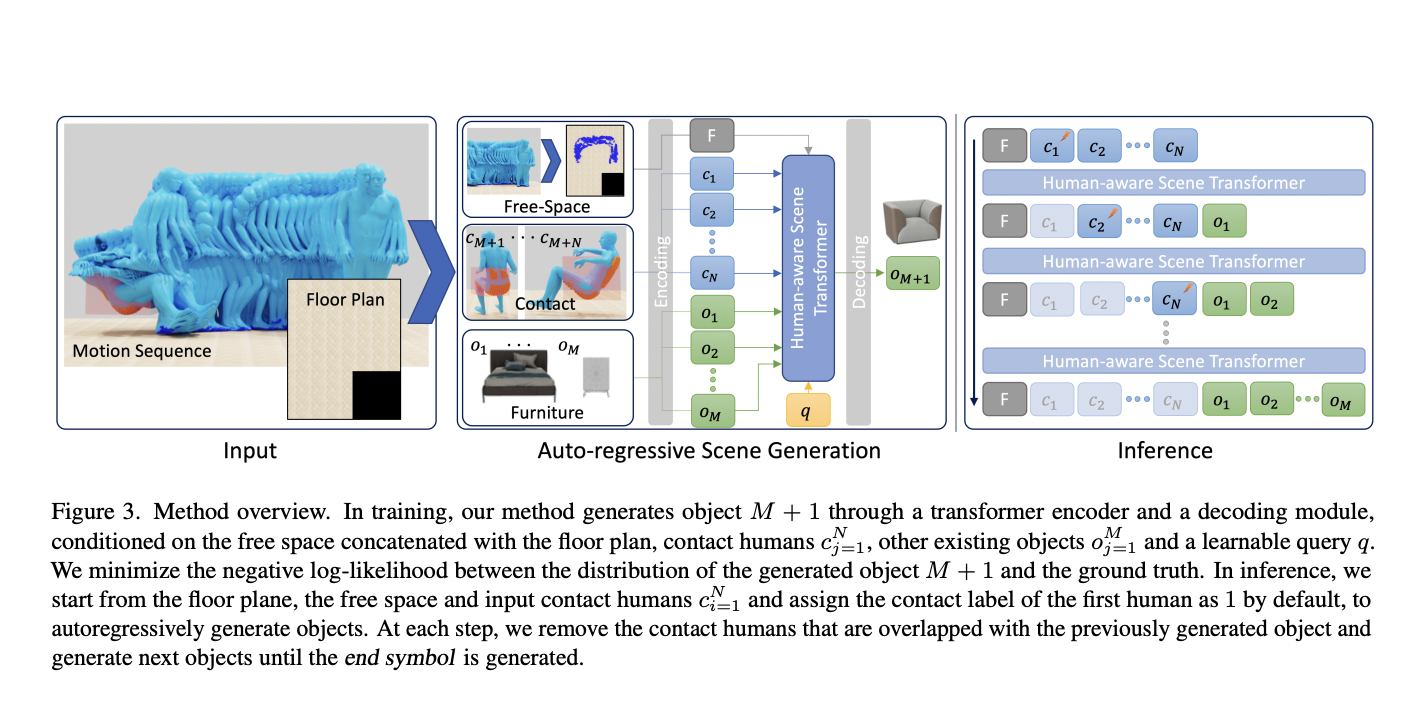
Researchers from the Max Planck Institute for Intelligent Systems in Germany and Adobe created MIME, a transformer-based auto-regressive 3D scene generation technique, to give these intuitions some tangible form. Given an empty floor plan and a human motion sequence, MIME predicts the furniture that will come into contact with the human. Additionally, it foresees believable items that do not come into touch with people but fit in with other objects and adhere to the free-space restrictions brought on by the motions of people. They partition the motion into contact and non-contact snippets to condition the 3D scene creation for human motion. They estimate potential contact poses using POSA. The non-contact postures project the foot vertices onto the ground plane to establish the room’s free space, which they record as 2D floor maps.
The contact vertices predicted by POSA create 3D bounding boxes that reflect the contact postures and associated 3D human body models. The objects that satisfy the contact and free-space criteria are expected autoregressively use this data as input to the transformer; see Fig. 1. They expanded the large-scale synthetic scene dataset 3D-FRONT to create a new dataset named 3D-FRONT HUMAN to train MIME. They automatically add people to the 3D scenarios, including non-contact people (a series of walking motions and people standing) and contact people (people sitting, touching, and lying). To do this, they use static contact poses from RenderPeople scans and motion sequences from AMASS.
MIME creates a realistic 3D scene layout for the input motion at inference time, represented as 3D bounding boxes. They choose 3D models from the 3D-FUTURE collection based on this arrangement; then, they fine-tune their 3D placement based on geometric restrictions between the human positions and the scene. Their method produces a 3D set that supports human touch and motion while placing convincing objects in free space, unlike pure 3D scene creation systems like ATISS. Their approach permits the development of items not in contact with the person, anticipating the complete scene instead of individual objects, in contrast to Pose2Room, a recent pose-conditioned generative model. They show that their approach works without any adjustments on genuine motion sequences that have been recorded, like PROX-D.
In conclusion, they contribute the following:
• A brand-new motion-conditioned generative model for 3D room scenes that auto-regressively creates things that come into contact with people while avoiding occupying motion-defined vacant space.
• A brand-new 3D scene dataset made up of interacting people and people in free space was created by filling 3D FRONT with motion data from AMASS and static contact/standing poses from RenderPeople.
The code is available on GitHub along with a video demo. They also have a video explanation of their approach.
Check Out The Paper, Github, and Project. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.