Researchers from McGill University and Microsoft Introduces Convolutional vision Transformer (CvT) that improves Vision Transformer (ViT) in Performance and Efficiency by Introducing Convolutions into ViT

Transformers have been widely used in the natural language processing (NLP) domain for years, and their introduction was a turning point for many NLP tasks. Their simplicity and generalization ability make them a key component in NLP tasks.
In 2020, a group of Google researchers came up with the concept of applying transformer structure to images and treating them similarly to sentences in languages. The idea was simple: an image is worth 16 x 16 words. This was the paper where the Vision Transformer (ViT) structure was first introduced, and the idea was adapted by many others afterward.
Similar to a transformer, ViT employs several embedding and tokenization techniques. A source picture is divided into a collection of image patches, and they are included in a collection of fixed-dimension encoded vectors. The transformer encoder network is given the encoded vector together with the position of a patch in the image.
ViT model could outperform state-of-the-art convolutional neural networks (CNN) in terms of computational effectiveness and accuracy, given that there is enough training data. However, when the training data is smaller, ViT struggles to perform as well as its CNN counterparts. As the authors mention in the CvT paper, one reason could be that ViT lacks several desirable characteristics that CNNs naturally possess that make CNNs especially well-suited to solving vision-related problems.
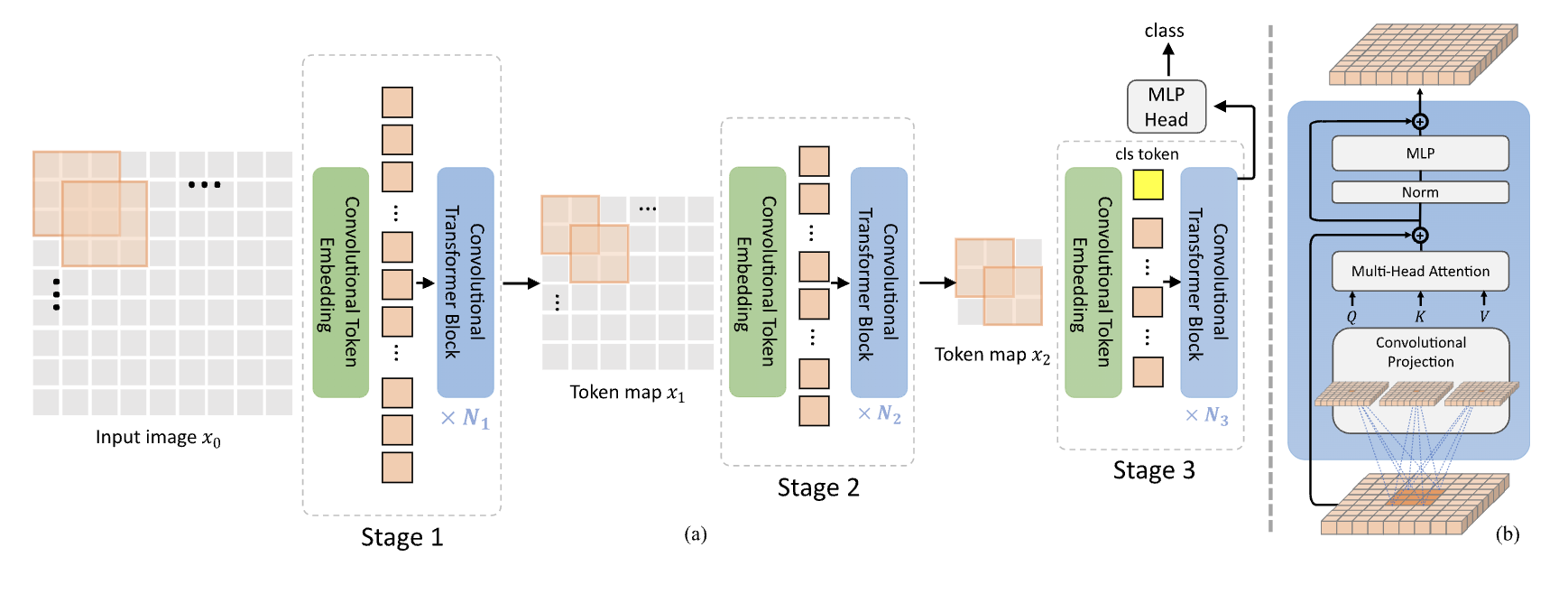
This is where the CvT comes to the rescue. This paper claims convolutions can be introduced into vision transformers to improve performance and their robustness while maintaining the computational efficiency of the original ViT structure. Convolutions are introduced to two core sections of ViT.
First, transformers are partitioned into multiple stages to form a hierarchical structure. Convolutional token embedding, which applies an overlapping convolution operation with stride on a 2D-reshaped token map, is applied at the start of each step, followed by layer normalization. This enables the model to execute spatial downsampling and concurrently increase the number of feature maps, as is done in CNNs, in addition to capturing local information and gradually shortening the sequence length while simultaneously lengthening token features across stages.
Second, the linear projection before each self-attention block is replaced with the proposed convolutional projection, which uses a depth-wise separable convolution operation on a 2D reshaped token map. This reduces the semantic ambiguity in the attention process and enables the model to capture the local spatial context in more detail. Additionally, it allows the control of computational complexity since the key and value matrices may be subsampled with a stride of convolution to increase efficiency by a factor of four or more with little to no performance loss.
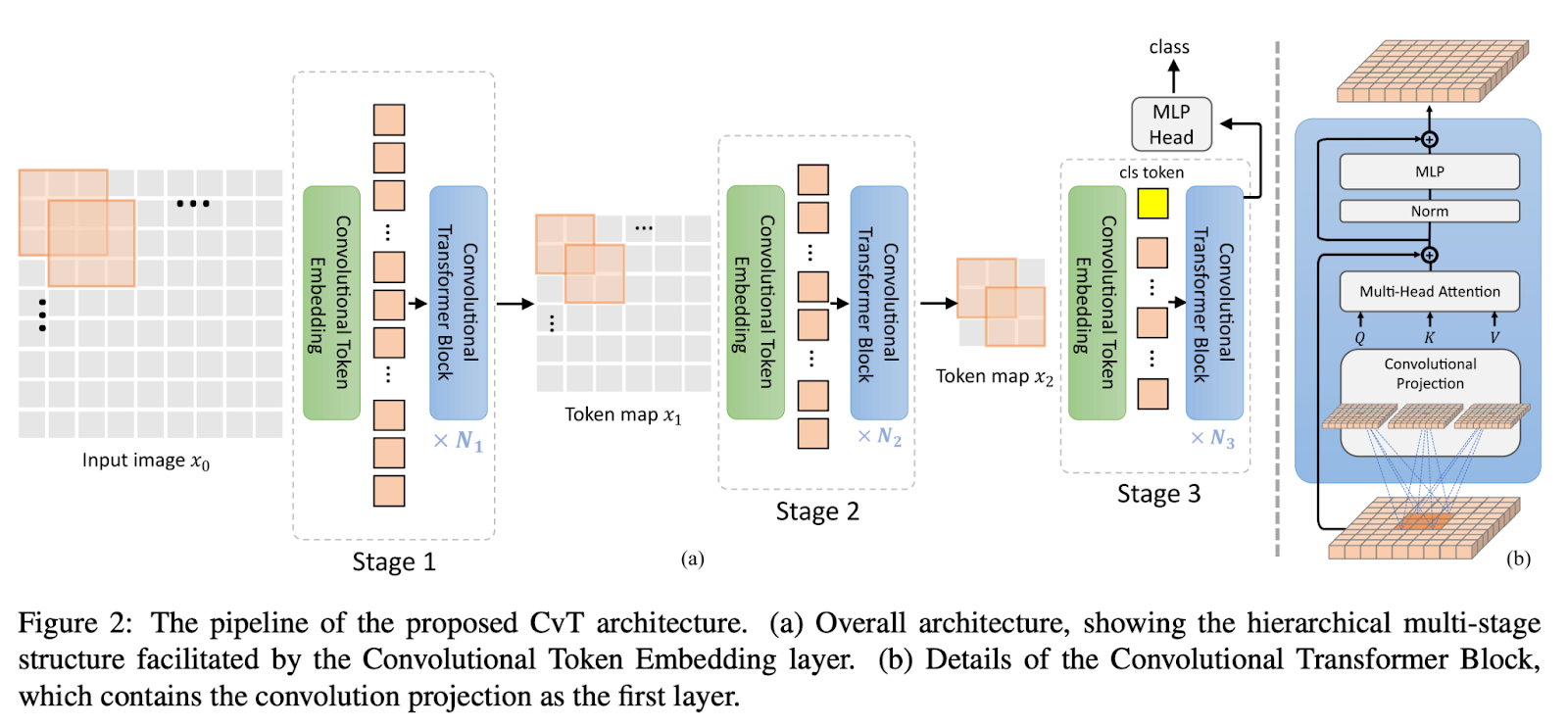
To sum up, the proposed CvT structure introduces all the benefits of CNNs, such as local receptive fields, shared weights, and spatial subsampling, while maintaining the advantages of the Transformer structure. The results show us CvT can achieve state-of-the-art performance while being lightweight and efficient.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'CvT: Introducing Convolutions to Vision Transformers'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and code. Please Don't Forget To Join Our ML Subreddit
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.