Researchers from McGill University Present the Pythia 70M Model for Distilling Transformers into Long Convolution Models
The emergence of Large Language Models (LLMs) has transformed the landscape of natural language processing (NLP). The introduction of the transformer architecture marked a pivotal moment, ushering in a new era in NLP. While a universal definition for LLMs is lacking, they are generally understood as versatile machine learning models adept at simultaneously handling various natural language processing tasks, showcasing these models’ rapid evolution and impact on the field.
Four essential tasks in LLMs are natural language understanding, natural language generation, knowledge-intensive tasks, and reasoning ability. The evolving landscape includes diverse architectural strategies, such as models employing both encoders and decoders, encoder-only models like BERT, and decoder-only models like GPT-4. GPT-4’s decoder-only approach excels in natural language generation tasks. Despite the enhanced performance of GPT-4 Turbo, its 1.7 trillion parameters raise concerns about substantial energy consumption, emphasizing the need for sustainable AI solutions.
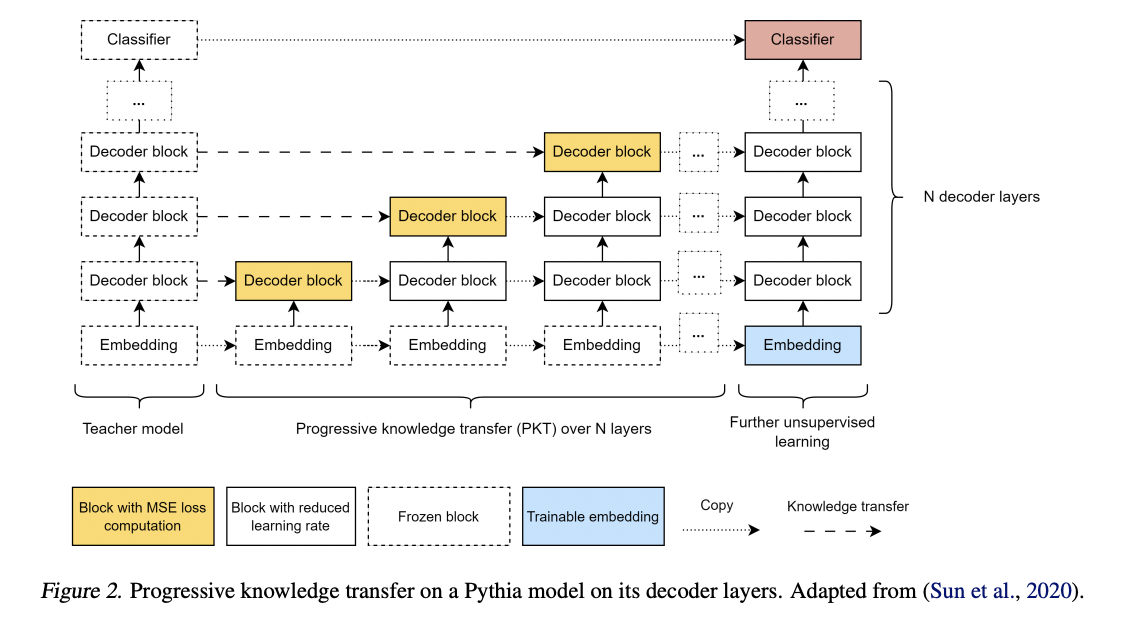
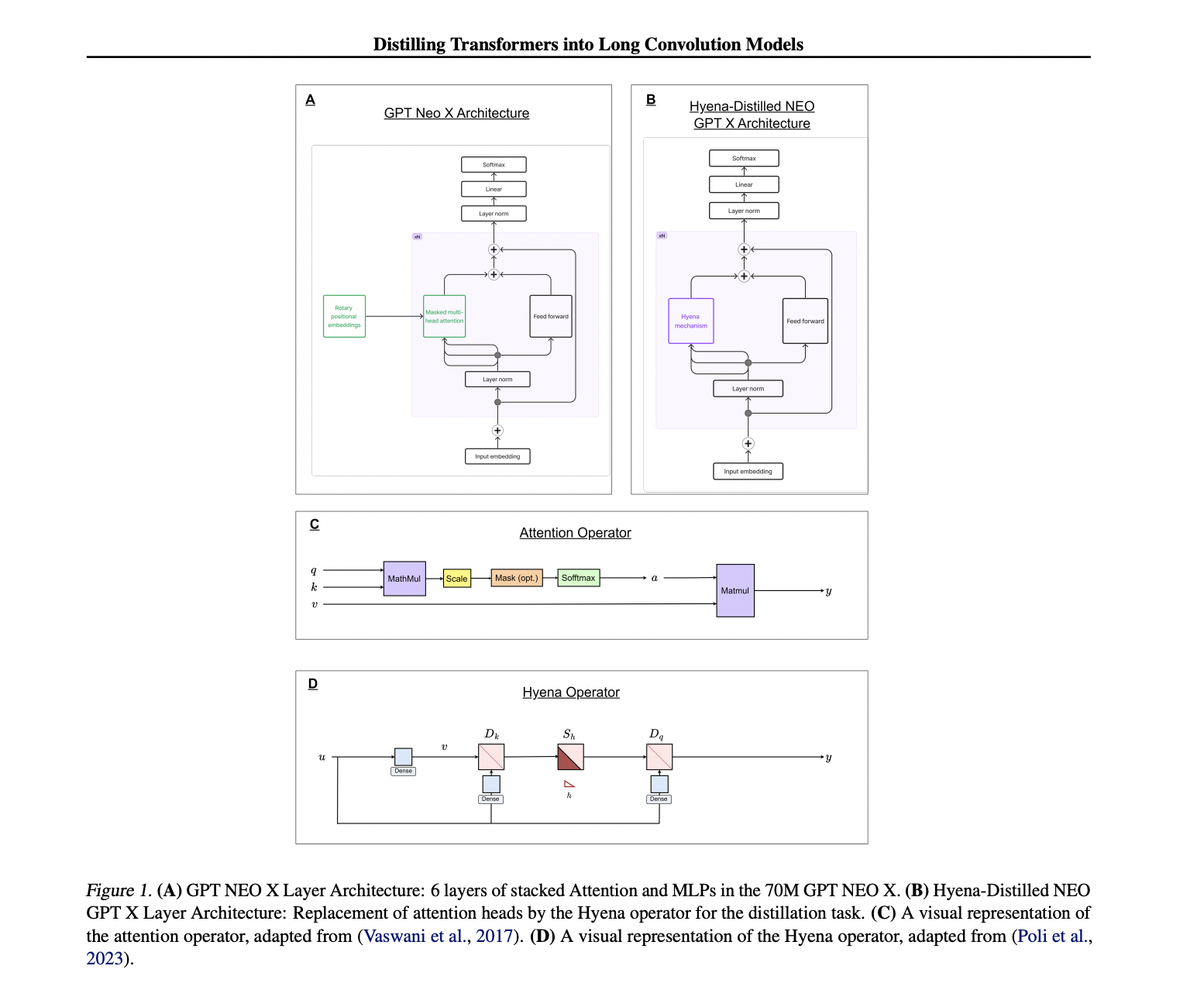
The researchers from McGill University have proposed the Pythia 70M model, a pioneering approach to enhancing the efficiency of LLM pre-training by advocating knowledge distillation for cross-architecture transfer. Drawing inspiration from the efficient Hyena mechanism, the method replaces attention heads in transformer models with Hyena, providing a cost-effective alternative to conventional pre-training. This approach effectively tackles the intrinsic challenge posed by processing long contextual information in quadratic attention mechanisms, offering a promising avenue for more efficient and scalable LLMs.
The researchers utilize the efficient Hyena mechanism, replacing attention heads in transformer models with Hyena. This innovative approach improves inference speed and outperforms traditional pre-training in accuracy and efficiency. The method specifically addresses the challenge of processing long contextual information inherent in quadratic attention mechanisms, striving to balance computational power and environmental impact, showcasing a cost-effective and environmentally conscious alternative to conventional pre-training methods.
Studies present perplexity scores for different models, including Pythia-70M, pre-trained Hyena model, Hyena student model distilled with MSE loss, and Hyena student model fine-tuned after distillation. The pre-trained Hyena model shows improved perplexity compared to Pythia-70M. Distillation further enhances performance, with the lowest perplexity achieved by the Hyena student model through fine-tuning. In language evaluation tasks using the Language Model Evaluation Harness, the Hyena-based models demonstrate competitive performance across various natural language tasks compared to the attention-based Pythia-70M teacher model.
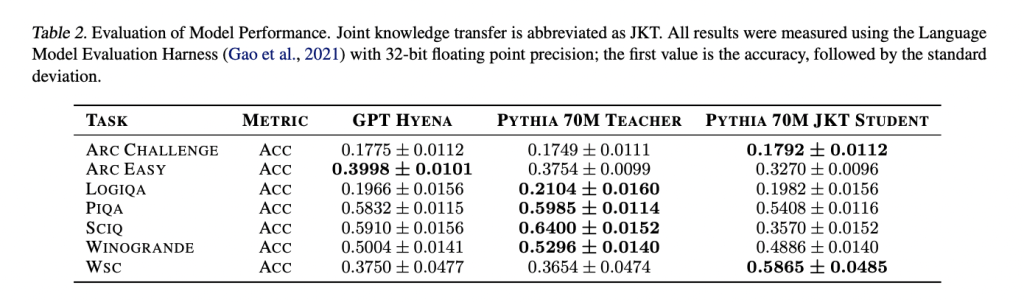
To conclude, the researchers from McGill University have proposed the Pythia 70M model. Employing joint knowledge transfer with Hyena operators as a substitute for attention enhances the computational efficiency of LLMs during training. Evaluating perplexity scores on OpenWebText and WikiText datasets, the Pythia 70M Hyena model, undergoing progressive knowledge transfer, outperforms its pre-trained counterpart. Fine-tuning post-knowledge transfer further reduces perplexity, indicating improved model performance. Although the student Hyena model shows slightly lower accuracy in natural language tasks compared to the teacher model, the results suggest that joint knowledge transfer with Hyena offers a promising alternative for training more computationally efficient LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link
Comments are closed.