Researchers From Meta AI And the University Of Cambridge Examine How Large Language Models (LLMs) Can Be Prompted With Speech Recognition Abilities
Large Language Models are the new trend, thanks to the introduction of the well-known ChatGPT. Developed by OpenAI, this chatbot does everything from answering questions precisely, summarizing long paragraphs of textual data, completing code snippets, translating the text into different languages, and so on. LLMs have human imitating capabilities and are based on sub-fields of Artificial Intelligence, including Natural Language Processing, Natural Language Understanding, Natural Language Generation, Computer Vision, and so on.
Without any explicit supervision, LLMs are trained by anticipating the next word in a vast amount of textual data, as a result of which they develop the ability to encode a sizeable amount of knowledge about the outside world inside the constraints of their neural networks, which makes them useful for a variety of downstream tasks. Though LLMs have shown great performance in different fields, recent research has incorporated a tiny audio encoder into the model to extend the capabilities of LLMs a step further by enabling speech recognition.
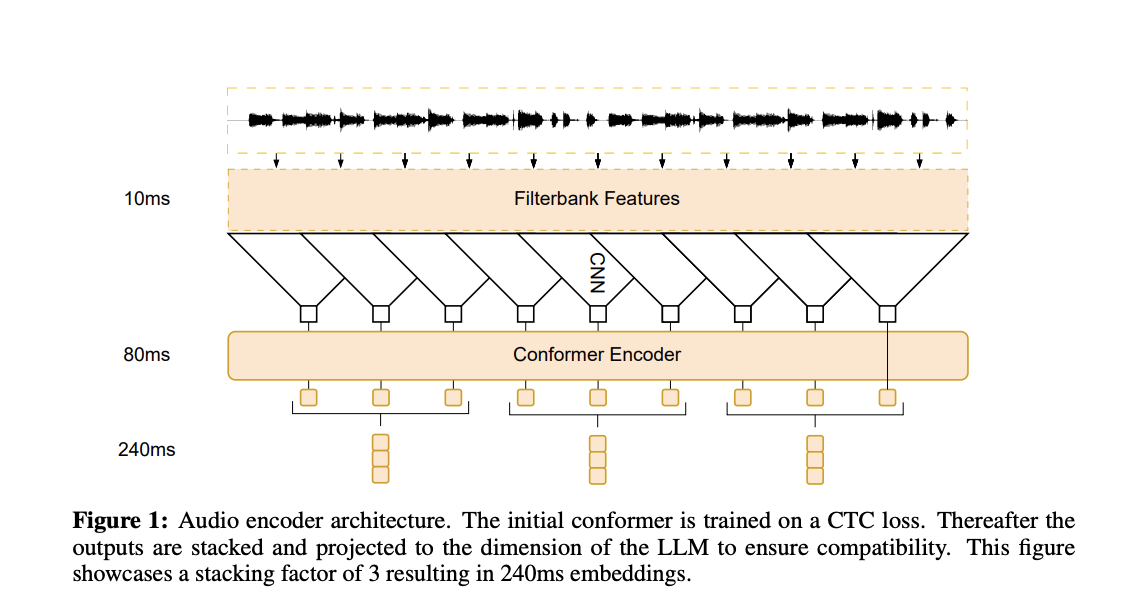
The procedure entails directly incorporating a series of audial embeddings, such as audio data representations, into the already-existing text token embeddings. This enables the LLM to do automatic speech recognition (ASR) tasks much like its text-based equivalent because of its integrated representation. It can also translate spoken communication into printed text. The team has shared that a decoder-only big language model can perform multilingual speech recognition and outperforms supervised monolingual training baselines when trained on an audio sequence. The size and frame rate of the audio encoder model, the low-rank adaption of LLM parameters, text token masking, and the type of large language model utilized are just a few of the variables the research examines to improve recognition accuracy.
Through analysis of the audio encoder’s outputs that the audio embeddings match the corresponding text tokens accurately, the team has demonstrated the effective fusion of the audio and textual information. For evaluation, the team has used the Multilingual LibriSpeech (MLS) dataset to gauge the efficacy of this strategy. The open-sourced LLaMA-7B, a large language model, incorporates a conformer encoder, a kind of neural network specifically intended for audio processing. The outcomes showed that this adjustment enables the LLM to perform 18% better on voice recognition tasks than monolingual baselines. The LLaMA-7B, which was mainly trained in English text, excels at multilingual speech recognition.
In addition to the main experiment, the research has also examined other aspects of the performance of the augmented LLM. To find out if the LLM can be frozen during training while retaining its initial capabilities, researchers have conducted ablation trials. This entails refraining from changing the LLM’s parameters while the ASR system is being trained and shows that it is still capable of performing multilingual ASR well even while the LLM is frozen.
The team has also investigated the effects of scaling up the audio encoder, raising the audio encoder stride, which is a parameter associated with how audio is split, and producing fewer audio embeddings. Through these tests, the aim is to improve the effectiveness and efficiency of the ASR system. In conclusion, the approach seems promising as the results demonstrate the viability of multilingual ASR even with larger audio encoders or longer strides, suggesting that LLMs are capable of processing long-form audio inputs.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.