Researchers From Microsoft and CMU Introduce ‘COMPASS’: A General-Purpose Large-Scale Pretraining Pipeline For Perception-Action Loops in Autonomous Systems

Humans have the essential cognitive capacity to comprehend the world via multimodal sensory inputs and use this ability to perform a wide range of activities. Autonomous agents can observe an environment’s underlying condition through many sensors in a comparable way and evaluate how to complete a job correctly. Localization (or “where am I?”) is a fundamental question that an autonomous agent must answer before navigation, and it is frequently addressed via visual Odometry.
Collision avoidance and knowledge of the temporal evolution of their condition concerning the surroundings are required for highly dynamic tasks such as car racing. As a result, it’s probable to create general-purpose pre-trained models for autonomous systems independent of functions and form factors.
In a recent paper, COMPASS: Contrastive Multimodal Pretraining for Autonomous Systems, a general-purpose pre-training pipeline was proposed to circumvent such restrictions coming from task-specific models. COMPASS has three main features:
- It is a large-scale pre-training pipeline for perception-action loops in autonomous systems that may be used for various applications. COMPASS’s learned representations adapt to multiple situations and dramatically increase performance on relevant downstream tasks.
- It was created with multimodal data in mind. The framework is designed to use rich information from several sensor modalities, given the presence of a large number of sensors in autonomous systems.
- It is taught self-supervised without manual labeling, allowing it to use enormous amounts of data for pre-training.

COMPASS may address various downstream problems: drone navigation, vehicle racing, and visual odometry tasks. Learning generic representations for autonomous systems presents many challenges.
Although general-purpose pre-trained models have made significant advances in natural language processing (NLP) and computer vision, developing such models for autonomous systems has its own set of obstacles.
Autonomous systems deal with the intricate interaction between perception and action due to environmental elements and application circumstances. In contrast to language models, which focus on underlying linguistic representations, and visual models, which focus on object-centric semantics, this is a significant difference. Existing pre-training methodologies are insufficient for autonomous systems because of these factors.
Because multimodal sensors are used to detect the environment, the model must interpret multimodal data. Multimodal learning techniques now in use are primarily concerned with mapping multimodal data into common latent areas. Although they are suboptimal for autonomous systems, they show favorable video, audio, and text applications.
Different features of multimodal input, such as sampling rate and temporal dynamics, are ignored by approaches that learn a single joint latent space. However, because various autonomous systems can be outfitted with a broad range of sensor configurations, mapping onto discontinuous latent areas loses the link between the modalities and restricts its application in complicated autonomous systems.
COMPASS is a multimodal pre-training framework for autonomous systems’ perception and action. COMPASS creates multimodal representations that may be used in various situations and activities.
COMPASS’s design was based on two questions:
- What critical bits of information are required for all autonomous system tasks?
- How to extract the needed information from complex multimodal data?
The spatial and temporal restrictions of autonomous systems must be considered while designing the network architecture. The motion, its temporal features, and the sensors’ spatial, geometric, and semantic signals must all be accounted for in the representation.
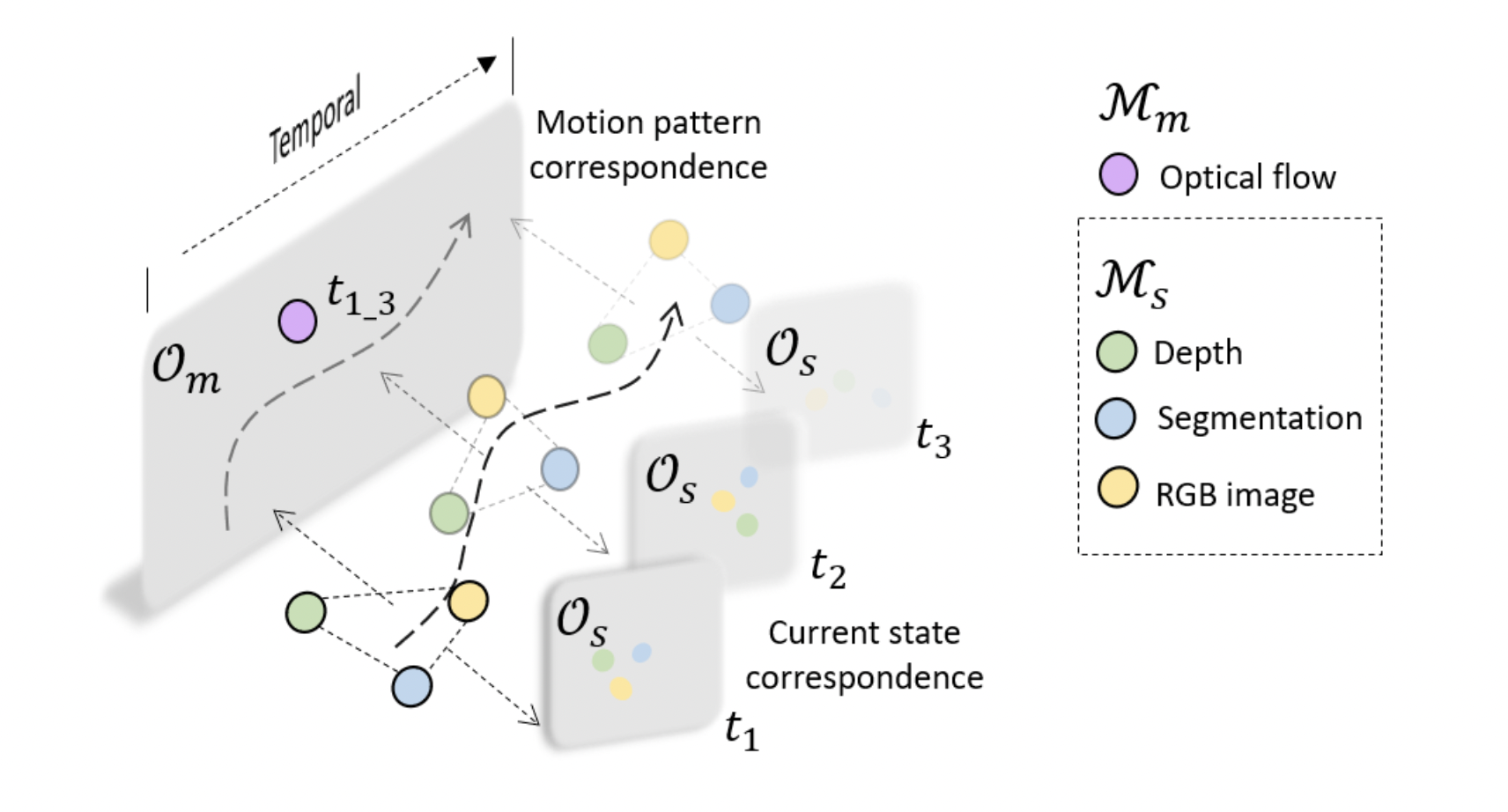
As a result, a multimodal graph encapsulates the modalities’ spatiotemporal features. Each modality is mapped into two factorized spatiotemporal latent subspaces in the chart:
- the motion pattern space and,
- the present state space.
The modality is then associated with the distinct latent areas via multimodal correspondence in self-supervised training.
While many sensor modalities are rich in spatial and semantic clues (e.g., RGB pictures, depth sensors), specific modalities (e.g., IMU, Optical Flow) primarily offer information regarding the time aspect. Simultaneously train two latent spaces, a “motion pattern space” Om and a “current state space” Os.
The self-supervised goal for training COMPASS is based on the idea that if the representation correctly captures spatiotemporal information across several modalities, each modality should have some predictive power, both for itself and for the others. This intuition is turned into a contrastive learning goal. The notion of the modality-specific encoders E extracting embeddings from each modality is visually depicted in the figure below.
A spatiotemporal link was realized in which spatial modalities from different timesteps are aggregated via an aggregator head G and projected into the motion pattern space to better correlate spatial and temporal modalities. A multimodal network comprising spatial, material, and spatiotemporal links, for example, can be used to learn multimodal representations by recording the underlying features of modalities (such as static and dynamic) as well as any shared information (for example, geometry, motion).
Finally, simulation addressed the problem of data scarcity. The TartanAir dataset (TartanAir: A Dataset to Push the Limits of Visual SLAM – Microsoft Research) was used to train the model, built on the earlier work in high-fidelity simulation using AirSim.

The COMPASS model may be fine-tuned for numerous downstream tasks after pre-training. The relevant pre-trained COMPASS encoders to tiny neural network modules responsible for task-specific predictions such as robot movements, camera postures, and so on, based on the sensor modalities available for the task of interest. The data and objectives from the specific job were then used to fine-tune this integrated model.
Navigation via Drone
The purpose of this job is to allow a quadrotor drone to go through a series of gates that are unknown to it beforehand. A diversified collection of gates in the simulated environment vary in design, size, color, and texture. The model is expected to forecast velocity commands based on RGB pictures from the drone’s camera in this environment so that the drone may successfully pass through a series of gates. Fine-tuning COMPASS for this velocity prediction job outperforms training a model from the ground up. Furthermore, fine-tuning performance with various quantities of data compares to starting from scratch in terms of training. Even with fewer data, COMPASS fine-tuning typically delivers fewer mistakes than training from the beginning.
Visual Odometry
Visual Odometry (VO) is a technique for calculating camera motion from many picture frames. This is a critical component of visual SLAM, frequently utilized in robot localization. COMPASS was tested for the VO task on a widely known real-world dataset (The KITTI Vision Benchmark Suite (cvlibs.net).
Using the COMPASS pre-trained flow encoder in this VO pipeline produces better results than various other VO approaches and is similar to SLAM methods. COMPASS responds well to fine-tuning on real-world settings, despite pre-trained solely on simulation data.
Racing of Vehicles
The objective is to make autonomous vehicles compete in Formula One races. Visual distractors such as advertising signs, tires, grandstands, and fences are included in the simulated environment to enhance authenticity and raise job complexity. The control module must estimate the steering wheel angle based on RGB pictures from the surroundings for a car to properly move around the course and avoid obstructions.
COMPASS can generalize to previously unknown settings. According to a hypothesis, better perception facilitated by pre-training promotes generalization to unseen contexts.
By comparing loss curves from different pre-trained models on the same ‘unseen’ settings, the usefulness of pre-training on multimodal data can be estimated. COMPASS obtains the best overall performance by pre-training on multimodal data. Furthermore, compared to a model trained from scratch, these pre-training models have significant gaps (Scratch). When compared, it could be seen that scratch is more affected by overfitting than the other two models.
COMPASS is trained totally agnostic to any downstream tasks, in contrast to previous task-specific techniques in autonomous systems, with the primary objective of retrieving common knowledge across numerous scenarios. It learns to correlate multimodal data with attributes, encoding the Spatio-temporal aspect of data seen in autonomous systems. It generalizes to various downstream tasks, including drone navigation, car racing, and optical Odometry, even in unknown, real-world, and low-data contexts.
Paper: https://www.microsoft.com/en-us/research/uploads/prod/2022/02/COMPASS.pdf
Github: https://github.com/microsoft/COMPASS
Reference: https://www.microsoft.com/en-us/research/blog/compass-contrastive-multimodal-pretraining-for-autonomous-systems/
Suggested
Credit: Source link
Comments are closed.