Researchers from Microsoft and Tsinghua University Propose SCA (Segment and Caption Anything) to Efficiently Equip the SAM Model with the Ability to Generate Regional Captions
The intersection of computer vision and natural language processing has long grappled with the challenge of generating regional captions for entities within images. This task becomes particularly intricate due to the absence of semantic labels in training data. Researchers have pursued methods that efficiently address this gap, seeking ways to enable models to understand and describe diverse image elements.
Segment Anything Model (SAM) has emerged as a powerful class-agnostic segmentation model, demonstrating a remarkable ability to segment diverse entities. However, SAM needs to generate regional captions, limiting its potential applications. In response, a research team from Microsoft and Tsinghua University has introduced a solution named SCA (Segment and Caption Anything). SCA can be seen as a strategic augmentation of SAM, specifically designed to empower it with the capability to generate regional captions efficiently.
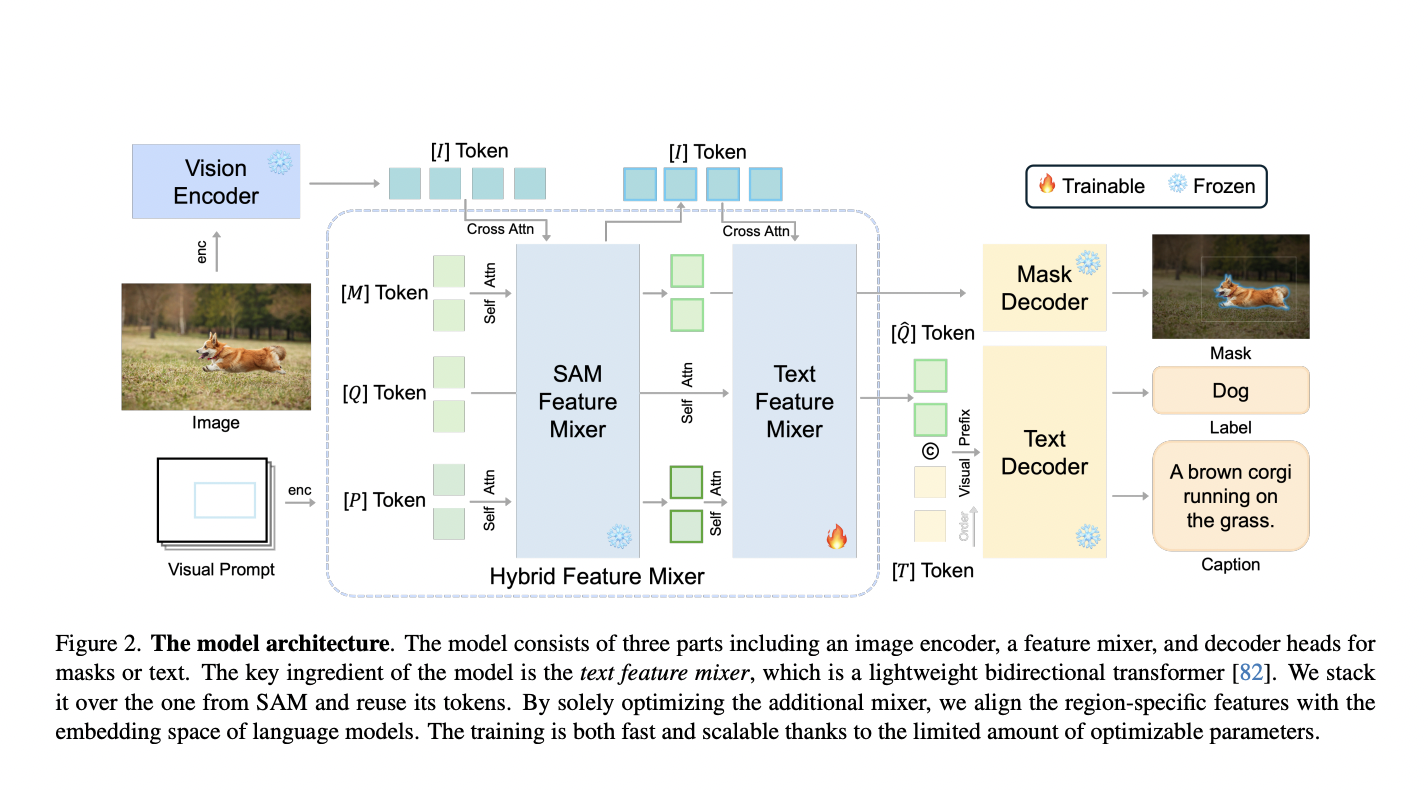
Analogous to building blocks, SAM provides a robust foundation for segmentation, while SCA adds a crucial layer to this foundation. This addition comes in the form of a lightweight query-based feature mixer. Unlike a traditional mixer, this component bridges SAM with causal language models, aligning region-specific features with the embedding space of language models. This alignment is crucial for subsequent caption generation, creating a synergy between SAM’s visual understanding and language models’ linguistic capabilities.
The architecture of SCA is a thoughtful composition of three main components: an image encoder, a feature mixer, and decoder heads for masks or text. The feature mixer, the linchpin of the model, is a lightweight bidirectional transformer. It operates as the connective tissue between SAM and language models, optimizing the alignment of region-specific features with language embeddings.

One of the key strengths of SCA lies in its efficiency. With a small number of trainable parameters, typically in the order of tens of millions, the training process becomes faster and more scalable. This efficiency results from strategic optimization, focusing solely on the additional feature mixer while keeping the SAM tokens intact.
The research team adopts a pre-training strategy with weak supervision to overcome the scarcity of regional caption data. In this approach, the model is pre-trained on object detection and segmentation tasks, leveraging datasets that contain category names rather than full-sentence descriptions. This weak supervision pre-training is a practical solution to transfer general knowledge of visual concepts beyond the limited regional captioning data available.
Extensive experiments have been conducted to validate the effectiveness of SCA. Comparative analyses against baselines, evaluation of different Vision Large Language Models (VLLMs), and testing of various image encoders have been conducted. The model demonstrates strong zero-shot performance on Referring Expression Generation (REG) tasks, showcasing its adaptability and generalization capabilities.
In conclusion, SCA is a promising advancement in regional captioning, seamlessly augmenting SAM’s robust segmentation capabilities. The strategic addition of a lightweight feature mixer, coupled with the efficiency of training and scalability, positions SCA as a noteworthy solution to a persistent challenge in computer vision and natural language processing.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
Credit: Source link
Comments are closed.