Researchers from Microsoft and UC Santa Barbara Propose LONGMEM: An AI Framework that Enables LLMs to Memorize Long History
Large language models (LLMs) have greatly improved the state-of-the-art in various understanding and generation tasks, revolutionizing natural language processing. Most LLMs gain from self-supervised training over huge corpora by gathering information from a fixed-sized local context and displaying emerging skills, including zero-shot prompting, in-context learning, and Chain-of-Thought (CoT) reasoning. The input length restriction of present LLMs precludes them from generalizing to real-world applications, such as extended horizontal planning, where the capacity to handle long-form material beyond a fix-sized session is crucial.
The simplest solution to the length limit problem is simply scaling up the input context length. For improved long-range interdependence, GPT-3, for example, raises the input length from 1k of GPT-2 to 2k tokens. The in-context dense attention is nevertheless severely confined by the quadratic computing complexity of Transformer self-attention, and this technique often requires computationally extensive training from the beginning. Another new area of research, which still mostly requires training from the start, focuses on creating in-context sparse attention to avoid the quadratic cost of self-attention.
While Memorising Transformer (MemTRM) is a well-known study, it approximates in-context scant attention through dense attention to both in-context tokens and memorized tokens retrieved from a non-differentiable memory for Transformers. MemTRM delivers significant perplexity benefits when modeling large books or papers by scaling up the resultant language model to handle up to 65k tokens. MemTRM’s linked memory approach, which uses a single model for encoding and fusing memory for language modeling, presents the memory staleness difficulty during training. In other words, cached earlier representations in memory may have distributional changes from those from the most recent model when the model parameters are changed, reducing the use of memory augmentation.
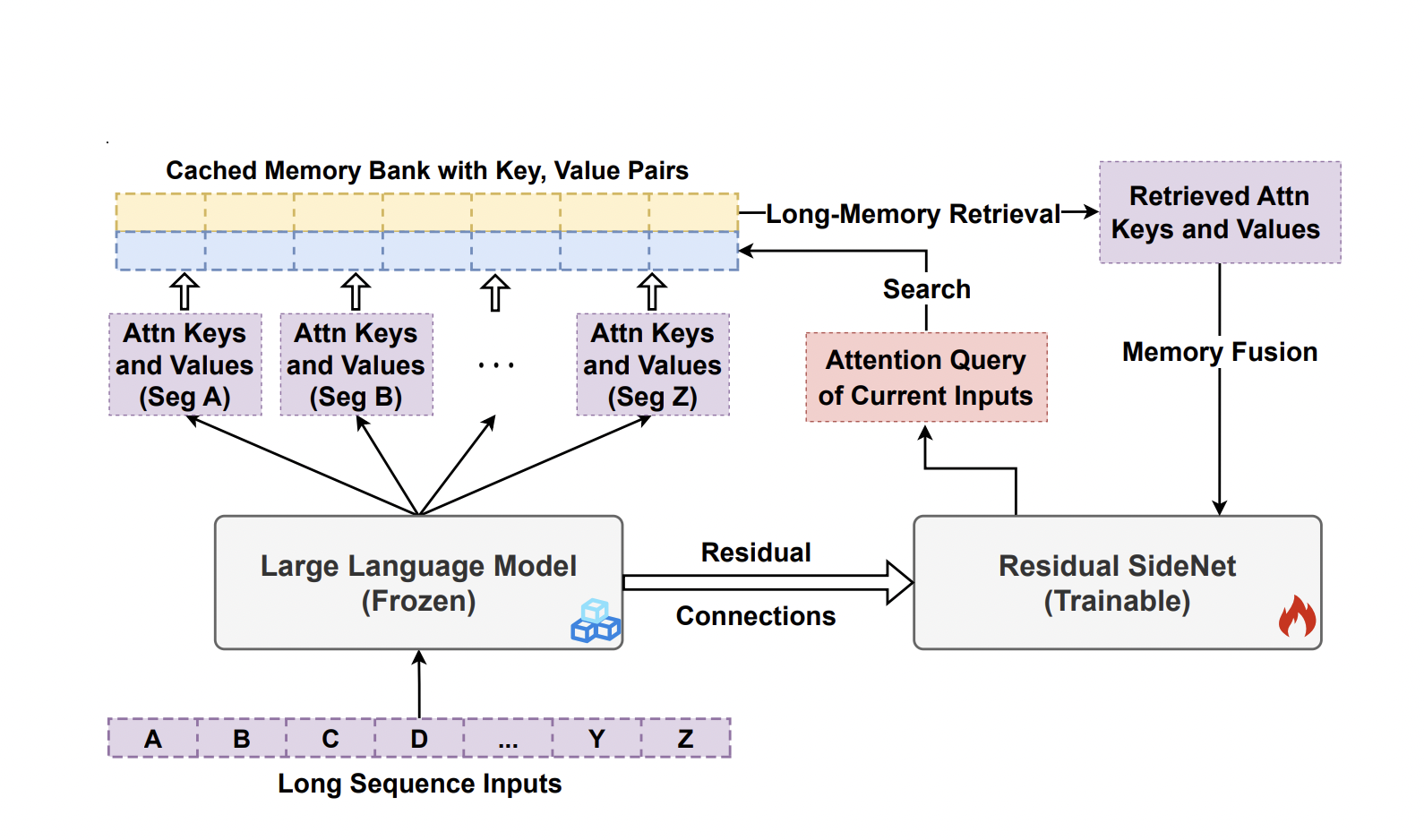
In this paper authors from UCSB and Microsoft Research propose the LONGMEM framework, which enables language models to cache long-form prior context or knowledge into the non-differentiable memory bank and take advantage of them via a decoupled memory module to address the memory staleness problem. They create a revolutionary residual side network (SideNet) to achieve decoupled memory. A frozen backbone LLM is used to extract the paired attention keys and values from the previous context into the memory bank. The resulting attention query of the current input is utilized in the SideNet’s memory-augmented layer to access cached (keys and values) for earlier contexts. The associated memory augmentations are then fused into learning hidden states via a joint attention process.
Better knowledge transfer from the pretrained backbone LLM is made possible by newly built cross-network residual connections between the SideNet and the frozen backbone LLM. The pre-trained LLM may be modified to utilize long-contextual memory by repeatedly training the residual SideNet to extract and fuse memory-augmented long-context. There are two primary advantages to their decoupled memory system. First, the decoupled frozen backbone LLM and SideNet in their proposed architecture isolate memory retrieval and fusion from encoding prior inputs into memory.
This efficiently addresses the problem of memory staleness since the backbone LLM only serves as the long-context knowledge encoder. In contrast, the residual SideNet serves as the memory retriever and reader. Second, it is computationally inefficient and suffers from catastrophic forgetting to change the LLM with memory augmentations directly. In addition to being able to access the knowledge that was previously learned, LONGMEM can also prevent devastating forgetting since the backbone LLM is frozen throughout the effective memory-augmented adaption stage. Depending on the subsequent activities, LONGMEM can input different kinds of long-form text and information into the memory bank.
They focus on two illustrative instances: memory-augmented in-context learning with thousands of task-relevant demonstration examples and language modeling with full-length book contexts. They assess how well the proposed LONGMEM performs on several long-text language modeling tasks and memory-augmented in-context learning for language understanding. According to experimental findings, their model regularly surpasses the strong baselines regarding its capacity for long-text modeling and in-context learning. Their approach significantly increases the ability of LLM to represent long-context language by -1.38 ~ -1.62 perplexity over various length splits of the Gutenberg-2022 corpus.
Surprisingly, their model greatly outperforms the current strong x-former baselines to attain the state-of-the-art performance of 40.5% identification accuracy on ChapterBreak, a difficult long-context modeling benchmark. Lastly, compared to MemTRM and baselines without memory enhancement, LONGMEM displays strong in-context learning benefits on common NLU tasks.
Check Out The Paper and Github link. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.