Researchers from Microsoft Asia and Peking University Proposed NUWA-Infinity, a Model to Generate High-Resolution, Arbitrarily-Sized Images and Videos
In recent years, the generation of images or videos from different types of inputs (text, visual, or multimodal) has gained increased popularity. In this context, the two main challenges that researchers worldwide are studying are 1) how to produce high-resolution images and 2) how to produce longer videos. This is because high-resolution images and long-duration videos can provide better visual effects for practical applications, such as design, advertisement, and entertainment. For example, just imagine the impact of a neural network able to produce a movie just given its script.
Nevertheless, generating arbitrarily-sized high-resolution images or videos is a very complex task, especially compared to the NLP world. First of all, while text generation in NLP has been studied for many years, visual applications are still in their early stages. The most efficient existing approaches, such as diffusion models, can only generate fixed-size images.
Second, different from text data, images and videos have two (width and height) and three (width, height, and duration) dimensions, respectively. This suggests that visual synthesis models should consider and model different generation orders and directions for different types of tasks.
For this reason, a group of researchers from Microsoft Asia and Peking University proposed NUWA-Infinity to tackle the problem of Infinite Visual Synthesis. The exciting thing about this method is its autoregression over autoregression mechanism. More clearly, a first autoregressive transformer takes care of generating the single tokens (as in standard autoregressive approaches) that compose a patch, while a second one deals with the dependencies between the overall patches.
Together with this, two other techniques necessary to make the above-mentioned model efficient were introduced: Nearby Context Pool (NCP) and Arbitrary Direction Controller (ADC).
Model
The model takes an input which can be a text or an image and aims to produce an image or a video with a user-specified resolution and duration. As already said, NUWA is based on two autoregressive models: a global one, which works on patches, based on all the previously generated patches, and a local one, which generates the tokens that composes every patch. The final image/video is then produced by composing the different patches.
ADC
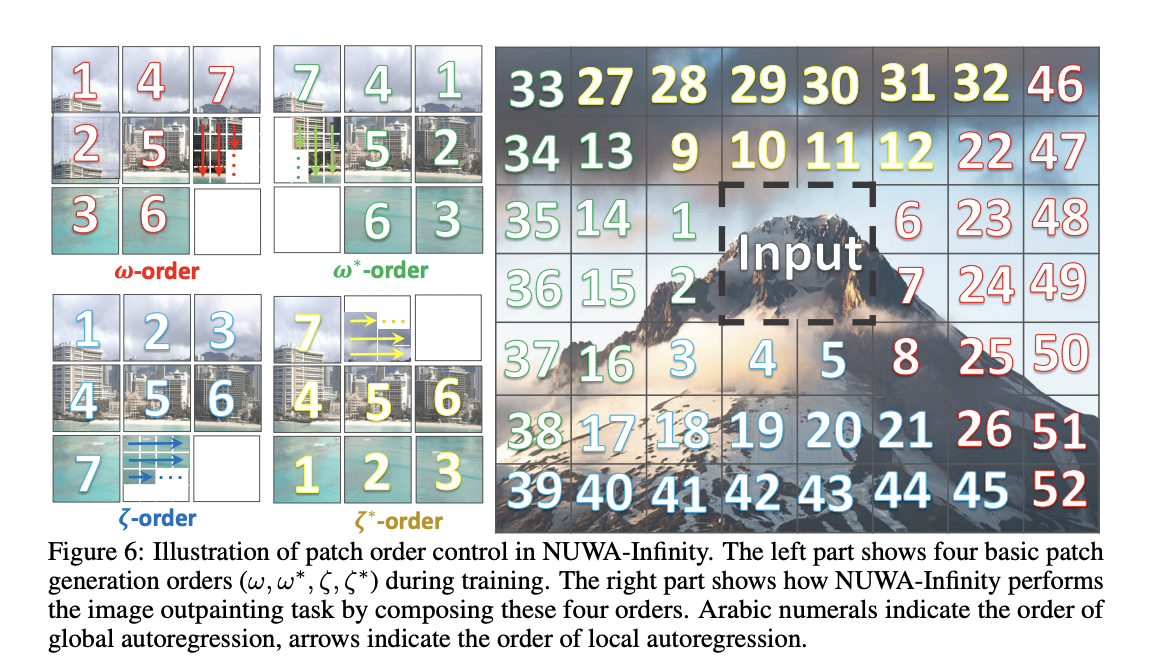
ADC was then proposed to solve the problem of the multi-dimensionality of images and video, contrary to text which is one-dimension. The main idea is that a single order left-to-right is not sufficient. ADC is composed of two functions: Split and Emb. The first takes an image or video and returns an ordered patch sequence. In the training phase, four basic generation orders (shown in the figure below, left) can be used. At inference time, the ability that NUWA learns during training of generating patches following different orders is used. For example, in the case of inpainting, it starts from a central patch and extends the image in all directions (figure below, right).

Once performed the split function, the Emb function assigns the position embedding to the being generated patch and defines its context from the already generated patches. The authors proposed a dynamic positional embedding, i.e., that change over time. Depending on the considered patch, the positional embedding of all the other patches changes accordingly.
NCP
NCP is meant to solve the problem of long-term relationships by caching related patches considering the context of the current patch and not all the previously generated patches. It is based on three functions: Select, Add and Remove. Add save the cache of the patch (defined as the multi-layer hidden states). Select takes the caches of the nearby patches of the considered patch to define the context. A maximum extent is used to define the ‘limits’ of the context. Finally, Remove deletes the caches of those patches which have no effect on the context anymore.
Training
During training, the network receives a pair text-image. The text is encoded by a text encoder, while the image (or video) is split into patches, and a patch generation order is selected with ADC. A pre-trained VQ-GAN transforms the images into visual tokens (a, b, c, d in the image below).
Given a patch, its context is selected with NCP, and once obtained the context, it is used to perform positional embedding with ADC.
Then, an L-layers vision decoder takes as input the patches and the context. Cross-attention (used usually for multimodal data) is also added to the decoder to tackle text-image relationships.
Finally, Add and Remove functions of NCP are used to clean the context for the next patch. The model is trained with a cross-entropy based on the generated token and the ground truth. The full process is resumed in the figure below.
Experiments
The model was tested on four different datasets (built by the authors) for five different tasks: Unconditional Image Generation, Image Outpainting, Image Animation, Text-to-Image, Text-to-Video, obtaining excellent and high-definition content for all the approaches. Some examples of these applications are shown below. The animations, which are one of the most interesting aspects of this paper, can be visualized here: https://nuwa-infinity.microsoft.com/
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Leonardo Tanzi is currently a Ph.D. Student at the Polytechnic University of Turin, Italy. His current research focuses on human-machine methodologies for smart support during complex interventions in the medical domain, using Deep Learning and Augmented Reality for 3D assistance.
Credit: Source link
Comments are closed.