Researchers from Microsoft Introduce Hydra-RLHF: A Memory-Efficient Solution for Reinforcement Learning with Human Feedback
Since becoming well known, the ChatGPT, GPT-4, and Llama-2 family models have won over users with their versatility as useful aides for various jobs. Model alignment using RLHF and many other foundation models is one factor in their effectiveness. Training a huge language model creates a network with a lot of knowledge. Still, because the network is not taught to distinguish among that information, it may exhibit undesirable behaviors and even cause social harm. By changing the model’s behavior, alignment seeks to address this problem and has grown to be crucial in developing secure and manageable foundation models.
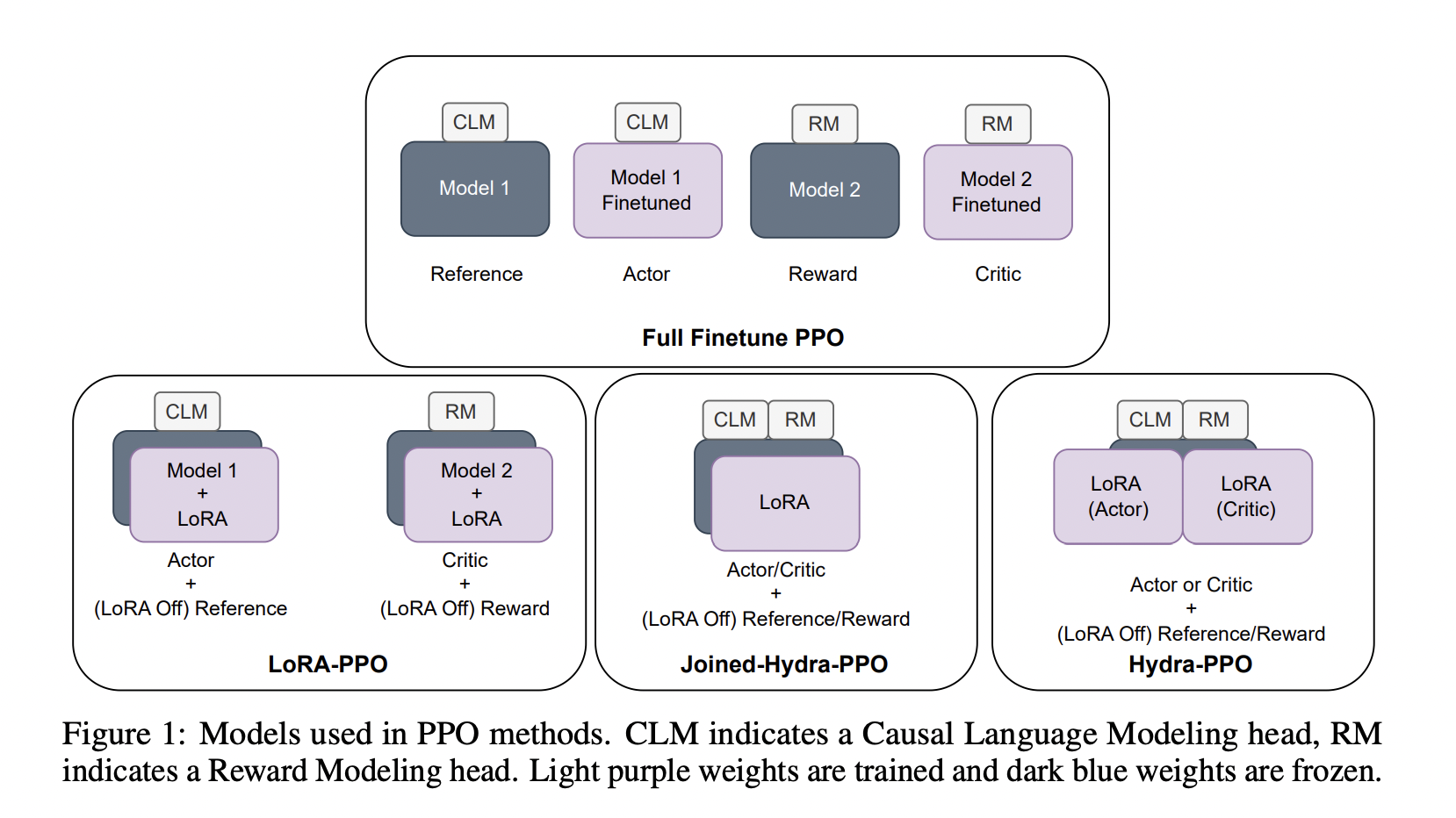
Although RLHF enhances model alignment, it has a restricted use due to its high complexity and large memory requirements when loading and training numerous models during PPO. There is a critical requirement to assess the variances in speed and performance of RLHF because its application is still in its infancy. They examine the training procedure and model architectures of the common RLHFPPO to meet this goal. Their inquiry discovered significant prospects for memory/computation cost reduction through model-sharing across Reference/Reward Models and Actor/Critic Models.
Researchers from Microsoft suggest Hydra-PPO to minimize the amount of learned and static models stored in memory during PPO in light of these findings. These memory savings may subsequently be used to enhance the training batch size, decreasing the per-sample latency of PPO by up to 65%, according to run-time and performance comparisons. They present a set of RLHF improvements called Hydra-RLHF. They create a decoder-based model called a hydra with two linear heads:
1) A causal head that predicts the token that will come after it in a sequence
2) A reward model head that provides the instant reward linked to the same input.
Multiple-headed models have been extensively studied, generally, and about reinforcement learning.
They have conducted comparison research that evaluates the effectiveness of several model alignment procedures as measured by GPT-4. They discovered that LoRA-PPO has better alignment than FFT but is more expensive. They introduce Hydra-RLHF, which combines reference and reward models and dynamically switches the current LoRA module during PPO, as a way to reduce memory use while preserving speed. HydraRLHF can train with up to 65% quicker per-sample latency with the extra RAM by using a larger batch size. The community may now use RLHF for a larger range of models and applications thanks to Hydra-RLHF.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.