Researchers from MIT and Microsoft Propose a Practical and Robust Video Conferencing Method Called Gemino That Uses Neural Compression System
We all saw the importance of good-quality video conferencing tools during COVID lockdowns. Education, entertainment, work meetings, and family visits became video conferences, and we spent hours finding the tool that gave us the best visual quality. The face-to-face communication continued via our screens when the faces were distant.
However, not all of us were lucky enough to benefit from this replacement communication technology. Those suffering from poor internet connection were talking with pixels and weird artifacts of their loved ones instead of the faces they were used to. To make matters worse, the video transmission was suspended if their network conditions became really unstable.
There have been attempts to address this issue and provide high-quality video conferencing even in poor network conditions using deep learning methods.
When it comes to video conferencing, the most essential part of the video is the face of the person speaking. The background details can be of a lower quality, and it would not affect the quality of experience for many people. Therefore, the deep learning-based solutions in video conferencing focus on improving faces.

These methods attempt to save bandwidth by generating each video frame using the compressed representation. During this generation phase, the face images are synthesized. Doing so can reduce the bandwidth significantly. However, robustness is an issue, especially in the face synthesis part. Since these approaches synthesize faces by warping a reference image into different poses and orientations, the reconstruction is problematic when the face movement is high.
Moreover, the high computational complexity of the process makes them impractical to use in most scenarios where the resolution is high, which is the case in most video conferencing applications nowadays.
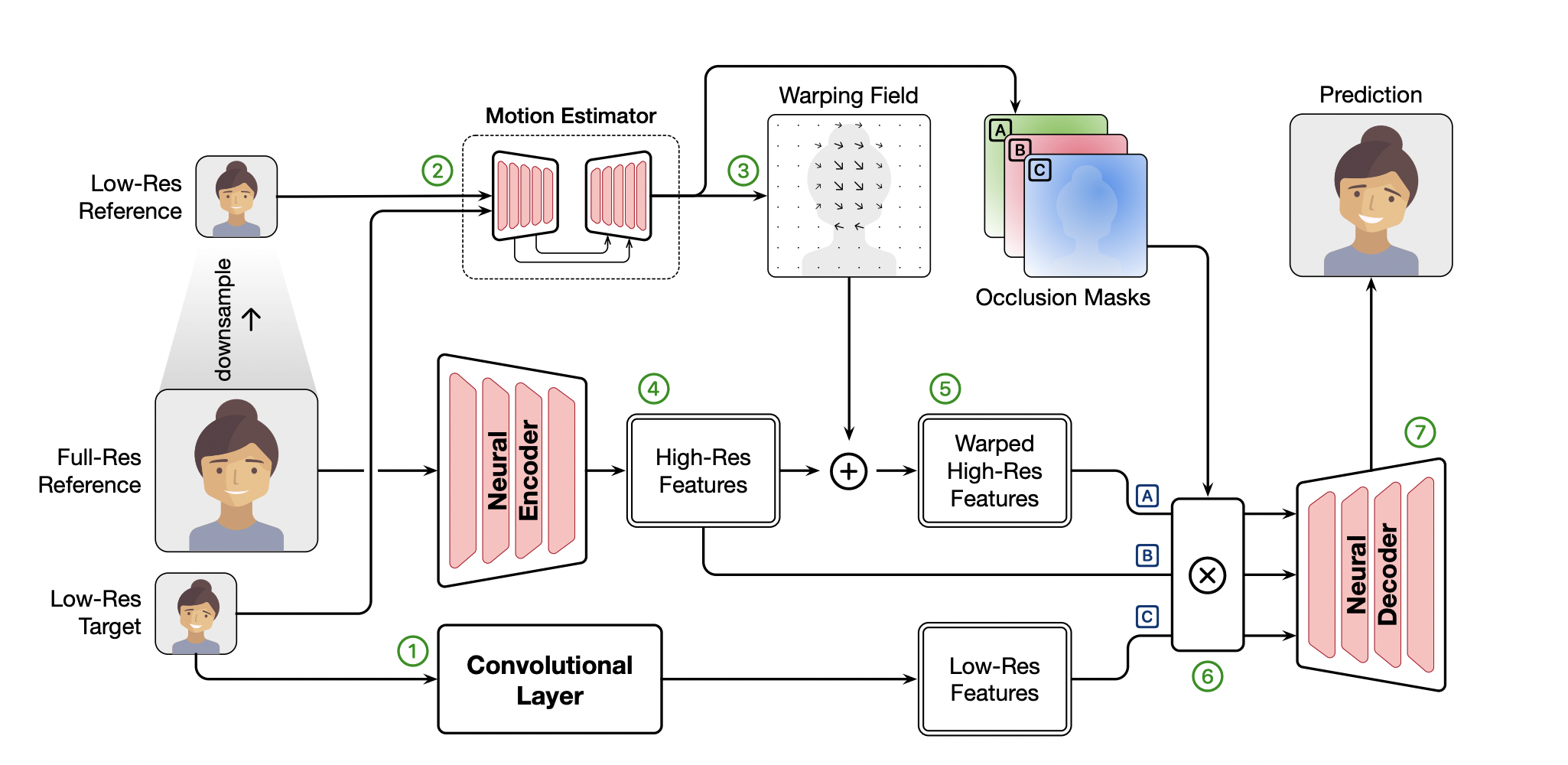
To tackle these problems, Gemino is proposed by researchers from MIT and Microsoft. Gemino is a neural compression system designed to improve video conferencing quality.
Existing methods transmit keyframes of a video instead of the entire video, hoping to synthesize the content on the client side to reduce the bandwidth. This can be problematic in some cases. For example, suppose an object, like the hand of the speaker, that was not in the reference frame suddenly appears. In that case, it is impossible to synthesize this object using the transmitted information. The only way is to send a new reference frame with the object in it, which will induce a significant cost to the network.
To solve this issue, Gemino transmits the entire video with a low resolution which contains much more information than keyframes. The video is then upscaled on the client side to the desired resolution. This is feasible as the low-resolution video size can be reduced significantly and become almost negligible when compressed with modern video codecs.
The main problem in this scenario is the upscaling and restoring of the lost information in the low-resolution space. To restore high-frequency details accurately, Gemino employs a reference frame that gives such texture information in a different posture than the target frame. It warps features retrieved from this reference frame depending on the motion between the reference and target frames, similar to synthesis techniques. Afterward, Gemino combines it with information collected from the low-resolution target picture to build the final reconstruction. This approach is named high-frequency-conditional super-resolution.
Moreover, Gemino trains a personalized model by fine-tuning the network on videos of a specific person to restore high-frequency information belonging to that person more accurately. Also, encoded low-resolution video frames are included in the dataset to increase robustness against codec-induced artifacts. Finally, to reduce the computational complexity, a multi-scale architecture is used where different components of the system work in different resolutions depending on the complexity of the problem.
This was a brief summary of Gemino. If you are interested in learning more about it, you can check the paper using the link below.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Gemino: Practical and Robust Neural Compression for Video Conferencing'. All Credit For This Research Goes To Researchers on This Project. Check out the paper. Please Don't Forget To Join Our ML Subreddit
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.