Researchers from MIT Developed a Machine Learning Technique that Enables Deep-Learning Models to Efficiently Adapt to new Sensor Data Directly on an Edge Device
With the rapid advancement of technology, Edge devices are an essential part of our everyday existence, perfectly integrating into our networked society. These widely used Edge devices produce an unparalleled amount of data at the edge of our networks.
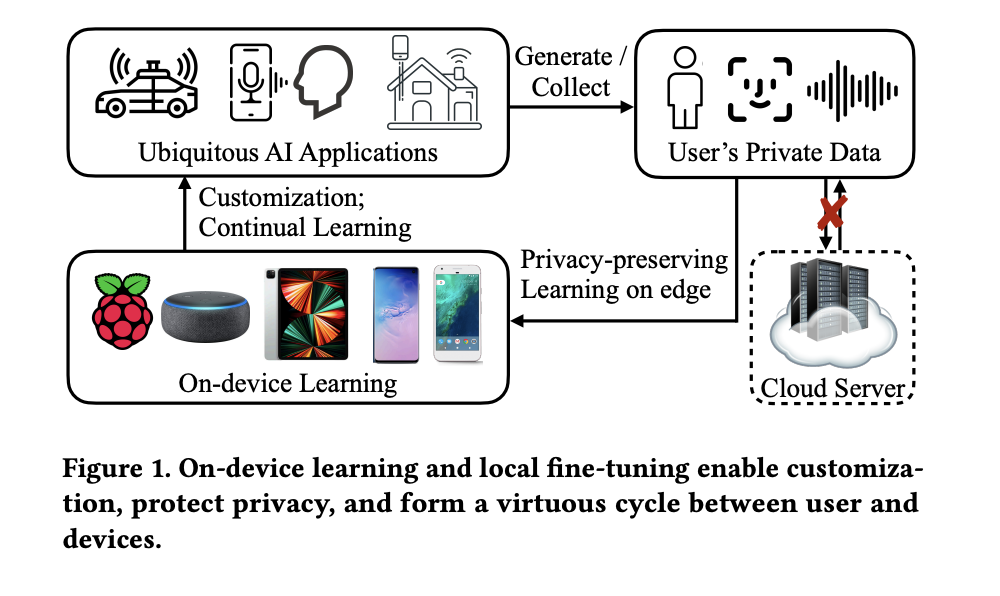
The demand for smart, customized, and confidential AI is increasing because one model can’t meet the diverse requirements of various users. Even though edge devices often handle deep learning tasks, the training of deep neural networks usually happens on powerful cloud GPU servers.
However, existing training frameworks are specifically for powerful cloud servers with accelerators, which must be optimized to enable effective learning on edge devices.
Customized deep learning models could enable AI chatbots to adapt to a user’s accent or smart keyboards that continuously improve word predictions based on previous typing activity.
User data is typically sent to cloud servers because smartphones and other edge devices frequently lack the memory and processing power required for this fine-tuning process. These servers are where the model is updated because they have the resources to complete the difficult task of fine-tuning the AI model.
Consequently, the researchers at MIT and other places have developed PockEngine—a technique that allows deep-learning models to effectively adjust to fresh sensor data directly on an edge device. PockEngine only stores and computes the precise portions of a large machine-learning model that require updating to increase accuracy.
Most of these calculations are completed during model preparation, before runtime, which reduces computational overhead and expedites the fine-tuning procedure. PockEngine dramatically accelerated on-device training; it performed up to 15 times faster on certain hardware platforms. PockEngine prevented models from losing accuracy. Their fine-tuning technique allowed a well-known AI chatbot to answer challenging queries more accurately.
PockEngine speeds up to 15 times faster on some hardware platforms. The training process is further accelerated by PockEngine’s integration of an extensive set of training graph optimizations.
Benefits of on-device fine-tuning include enhanced privacy, lower expenses, customization options, and lifetime learning. However, more resources are needed to make this process easier.
They said that PockEngine generates a backpropagation graph while the model is compiling and preparing for deployment. It accomplishes this by removing redundant sections of layers, resulting in a simplified diagram that can be utilized during runtime. Then, additional optimizations are made to improve efficiency.
This method is especially useful for models that need a lot of examples to be fine-tuned, as the researchers applied it to the large language model Llama-V2. PockEngine adjusts every layer separately for a particular task, tracking the improvement in accuracy with each layer. By weighing the trade-offs between accuracy and cost, PockEngine can ascertain each layer’s relative contributions and the required fine-tuning percentage.
The system first fine-tunes each layer on a certain task, one at a time, and measures the accuracy improvement after each layer. The researchers emphasized that PockEngine identifies the contribution of each layer, as well as trade-offs between accuracy and fine-tuning cost, and automatically determines the percentage of each layer that needs to be fine-tuned.
With a 15× speed boost over the pre-built TensorFlow for Raspberry Pi, PockEngine has proven to have impressive speed improvements. Furthermore, it achieves a noteworthy memory savings of 5.6× memory savings during backpropagation on Jetson AGX Orin; PockEngine showed impressive speed increases. Primarily, PockEngine allows LLaMav2-7B on NVIDIA to be fine-tuned effectively.
Check out the Paper and MIT Blog. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.