Researchers from MIT, Yonsei University, and University of Brasilia Introduce ‘Computer Progress’: A New Portal to Analyze the Computational Burden From Over 1,000 Deep Learning Research Papers

Deep Learning is now being used to predict how proteins fold, translate between languages, Analyze medical scans, and play complex games like Go, to mention a few examples of a rapidly gaining traction technology. The success of this machine-learning technology in those and other fields has propelled it from obscurity in the early 2000s to domination today.
Fortunately, decades of Moore’s Law and other advances in computer hardware resulted in a roughly 10-million-fold increase in the number of computations that a computer could perform in a second for artificial neural networks—later renamed “deep learning” when they included additional layers of neurons. As a result, when researchers returned to deep learning in the late 2000s, they did so using tools that were up to the task.
These more powerful computers allowed for networks with many more connections and neurons, allowing for better modeling of complicated processes. Researchers could smash record after record as they applied deep learning to new tasks.
Computational Burden
Computer Progress is a new website created by researchers from MIT, Yonsei University, and the University of Brasilia that assesses the computing weight of over 1,000 deep learning research articles. The site’s data demonstrate that the computational burden is increasing quicker than projected, suggesting that methods can yet be improved.
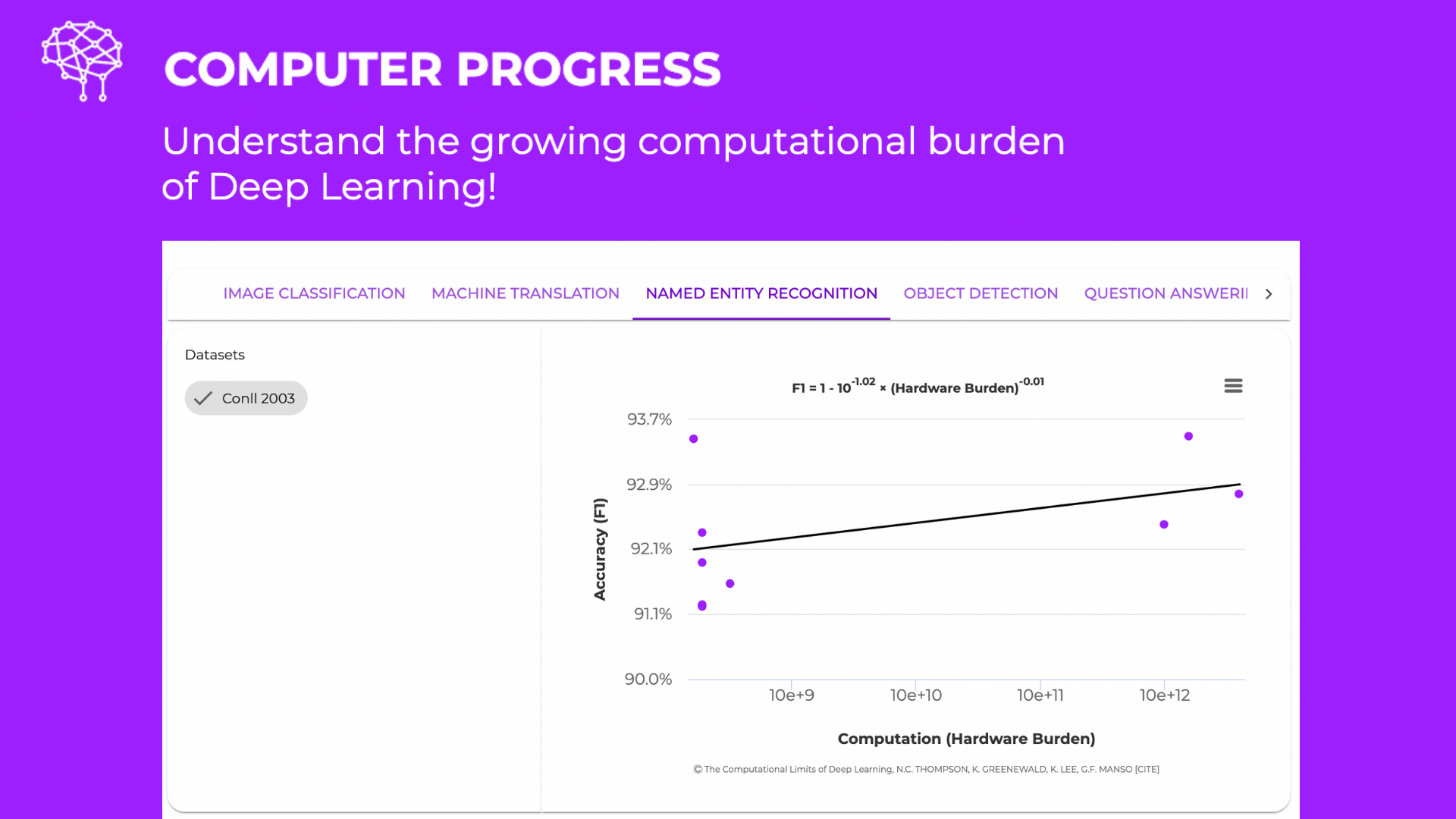
The launch was announced on Twitter by lead researcher Neil Thompson. In a paper published in IEEE Spectrum, Thompson, Kristjan Greenewald of the MIT-IBM Watson AI Lab, professor Keeheon Lee of Yonsei University, and Gabriel Manso of the University of Brasilia discussed the work’s rationale and findings. The researchers looked over 1,058 arXiv deep learning research publications to develop a scaling formula that connects a model’s performance to the computational load or the amount of computing power required to train it. The lower bound of computational burden for performance is a fourth-order polynomial in theory; however, the researchers discovered that current algorithms perform much worse; for example, ImageNet image classification algorithms scale as a ninth-order polynomial, requiring 500 times the compute to reduce the error rate by half. According to the authors, these scaling patterns indicate that academics should look for better algorithms.
Given the amount of training data, deep neural networks are frequently over-parameterized, meaning they have more model parameters than anticipated. This is proved to increase model performance and generalization empirically, whereas training approaches like stochastic gradient descent (SGD) and regularisation prevent over-fitting. Researchers have also discovered that improving model performance or accuracy necessitates an increase in training data and an increase in model size. Thompson and his colleagues suggest a theoretical bottom bound that computing rises as the fourth power of performance, assuming that performance gains need a quadratic increase in training data size and that computation grows quadratically with model parameters.
To verify this theory, the researchers examined through in-depth learning publications in the fields of computer vision (CV) and natural language processing on image recognition, object identification, question answering, named-entity recognition, and machine translation (NLP). They retrieved the accuracy metrics of the models presented and the computational cost of training the models, which is defined as the number of processors multiplied by the computation rate multiplied by the duration (essentially, the total number of floating-point operations). They then used linear regression to represent the model’s performance as a function of computation. Model performance scales substantially worse than the fourth-degree polynomial anticipated by theory, ranging from 7.7th degree for question answering to a polynomial of degree “about 50” for object identification, named-entity recognition, and machine translation.
On the other hand, Improved algorithms may be able to alleviate these scalability issues. According to the MIT study, “three years of algorithmic innovation is comparable to a tenfold gain in computer capacity.” In 2020, OpenAI conducted a similar analysis on image recognition algorithms, discovering that “the amount of computing required to train a neural net to the same performance on ImageNet classification has been falling by a factor of two every 16 months since 2012.” Thompson and a colleague recently reviewed 113 computer algorithm problem fields, including computer networking, signal processing, operating systems, and encryption, to see if better algorithms enhanced problem-solving performance. They discovered that while “about half” of issues, or “algorithm families,” did not improve, 14% made “transformative” advances, and 30%-43 percent made improvements “similar to or higher than those consumers experienced from Moore’s Law.”
Many of the complementary ideas offered by the Computer Progress team to increase deep learning efficiency have already been explored. Due to optical computing, large deep learning models might use less power, and total model size can be reduced by quantization and pruning. Finally, meta-learning allows you to cut down on the number of training cycles required to finish model training.
The compute vs. performance scaling statistics, as well as links to the original publications and a request for academics to contribute their own performance results, may be found on the Computer Progress website.
References:
Paper: https://arxiv.org/abs/2007.05558
Suggested
Credit: Source link
Comments are closed.