Researchers From National Taiwan University and Microsoft Developed ‘Frido,’ A Feature Pyramid Diffusion Framework For Complex Scene Generation
One of the core applications of AI in recent years is to generate photos that are more and more realistic. Starting from VAEs, the progress took tremendous momentum after Ian Goodfellow’s remarkable GAN invention. For many years, GAN remained a benchmark for realistic image generation. However, although first developed in 2015, Diffusion Models attracted much interest from researchers and industry only at the start of this decade. A breakthrough showed that Diffusion Models could create higher quality images than GAN. We would discuss how Diffusion Models work and how they are further used to create complex scenes.
In the Diffusion Model, data is gradually diffused to a gaussian noise in T timesteps in a forward pass. And then, the model parameters are updated to recover the data by reversing the forward process. In the forward pass at each timestep, data distribution is converted into a gaussian distribution with some mean and variance, such that at T-th timestep, it would be converted into a normal gaussian. Now the issue is how to recover data from noise to update model parameters. Although we can reverse the forward pass to make a gaussian transition, updating model parameters will be computationally intractable. A critical step to this is the reparameterization trick. It can be assumed that during the reverse process, some noise value is added to the previous timestep, which can be viewed as the model predicting noise at each timestep. The model parameter is updated to predict the most likely noise value at each timestep. Now, decomposing a high-resolution image to noise and training the model would require a high computational load, which can be reduced using the latent space. A general pre-trained VQGAN or KL-autoencoder can encode data into some latent space and then use the Diffusion model in that low-volume latent space. The process is known as the Latent Diffusion Model. The diffusion model can also be conditioned on other variables, like generating images conditioned on text input. The drawback of this diffusion mechanism is that the generated image often cannot produce all details because the model cannot differentiate low-level visual details from high-level information of shape, structure, etc., due to inefficient encoding. As a result, when a text describes some complex scene, the generated image quality often drops. The researchers here have attempted to solve this issue. We would discuss here how they have done it.
Firstly, a Multi-Scale-Vector-Quantizer GAN is used to encode data into a feature pyramid latent space. The network encoder maps data into a latent feature space of N scales, scaled from high-level to low-level. The decoder network jointly reconstructs the data from all scales. The network is trained to minimize the l2 loss between data and reconstruction along with other losses of VQGAN. An image is encoded into an N-scale latent space using a pre-trained MSVQGAN. In the forward diffusion process, noise is added sequentially from a higher-level feature map to a lower level; for each level, the T-step diffusion process is repeated, resulting in a total of N X T timesteps.
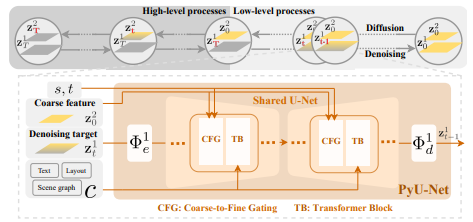
A feature pyramid U-Net (PyU-Net) is used as the neural estimator of noise in the reverse process. The predicted noise value depends on the previous higher-level feature map for a particular scale and timestep. In this way, there needs to be a separate U-Net to encode each stage, resulting in very high numbers of parameters. To reduce it, they have used a shared U-Net for all stages, with the layers specifying levels of the feature map. Now the issue is how to make the shared U-Net embedding aware of the stage and timestep and encode the low-level feature conditioned on the higher levels. The input feature is first convoluted with a higher-level feature map for a particular stage and timestep. Then the output is passed to a Spatio-temporal AdaIN together with summed embeddings of the stage and the timestep. The PyU-Net and Coarse-to-Fine Gating can diffuse an image from noise in a coarse-to-fine way. They called it Coarse-to-Fine Gating, as the PyU-Net produces embeddings from higher-level to lower-level feature maps.

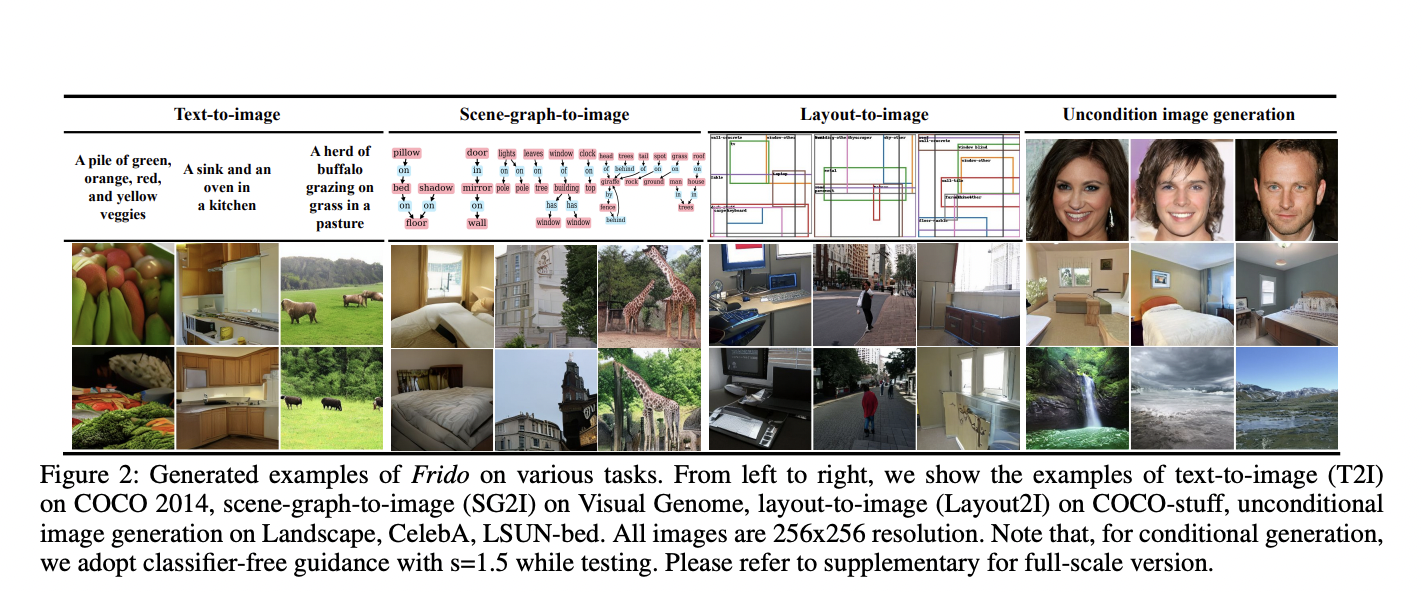
They named this framework FRIDO and tested it for generating an image in various ways, including from texts, scene graphs, labels, and layout. They have shown that each component (multi-scale encoder MSVQGAN, shared PyU-Net, Coarse-to-Fine Gating) significantly improves the image generation results. Using a shared PyU-Net instead of PyU-Net for each stage even increases the generation quality along with reducing model parameters. Frido sets new SOTA results for five tasks.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Frido: Feature Pyramid Diffusion for Complex Scene Image Synthesis'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, and github link. Please Don't Forget To Join Our ML Subreddit
![]()
I’m Arkaprava from Kolkata, India. I have completed my B.Tech. in Electronics and Communication Engineering in the year 2020 from Kalyani Government Engineering College, India. During my B.Tech. I’ve developed a keen interest in Signal Processing and its applications. Currently I’m pursuing MS degree from IIT Kanpur in Signal Processing, doing research on Audio Analysis using Deep Learning. Currently I’m working on unsupervised or semi-supervised learning frameworks for several tasks in audio.
Credit: Source link
Comments are closed.