Researchers from NTU and SenseTime Propose SHERF: A Generalizable Human NeRF Model for Recovering Animatable 3D Human Models from a Single Input Image
The fields of Artificial Intelligence and Deep Learning are constantly progressing at a fast pace. From Large Language Models based on Natural Language Processing to text to image models using the concepts of Computer vision, AI has come a long way. With Human Neural Radiance Fields (NeRFs), the reconstruction of high-quality 3D human models from 2D photos has become possible without the need for precise 3D geometry data. This development has important ramifications for several applications, including augmented reality (AR) and virtual reality (VR). Human NeRFs expedite the process of creating 3D human figures from 2D observations, reducing time and resources that would otherwise be needed to acquire ground truth 3D data.
The majority of the current techniques for reconstructing 3D human models using NeRFs use monocular films or several 2D photos acquired from different perspectives using multi-view cameras. Since this method has drawbacks when used in real-world situations where people’s photos are taken from random camera angles, this imposes considerable obstacles to producing accurate 3D human reconstructions. To address the issues, a team of researchers has introduced SHERF, the first generalizable Human NeRF model that can recover animated 3D human models from a single input image.
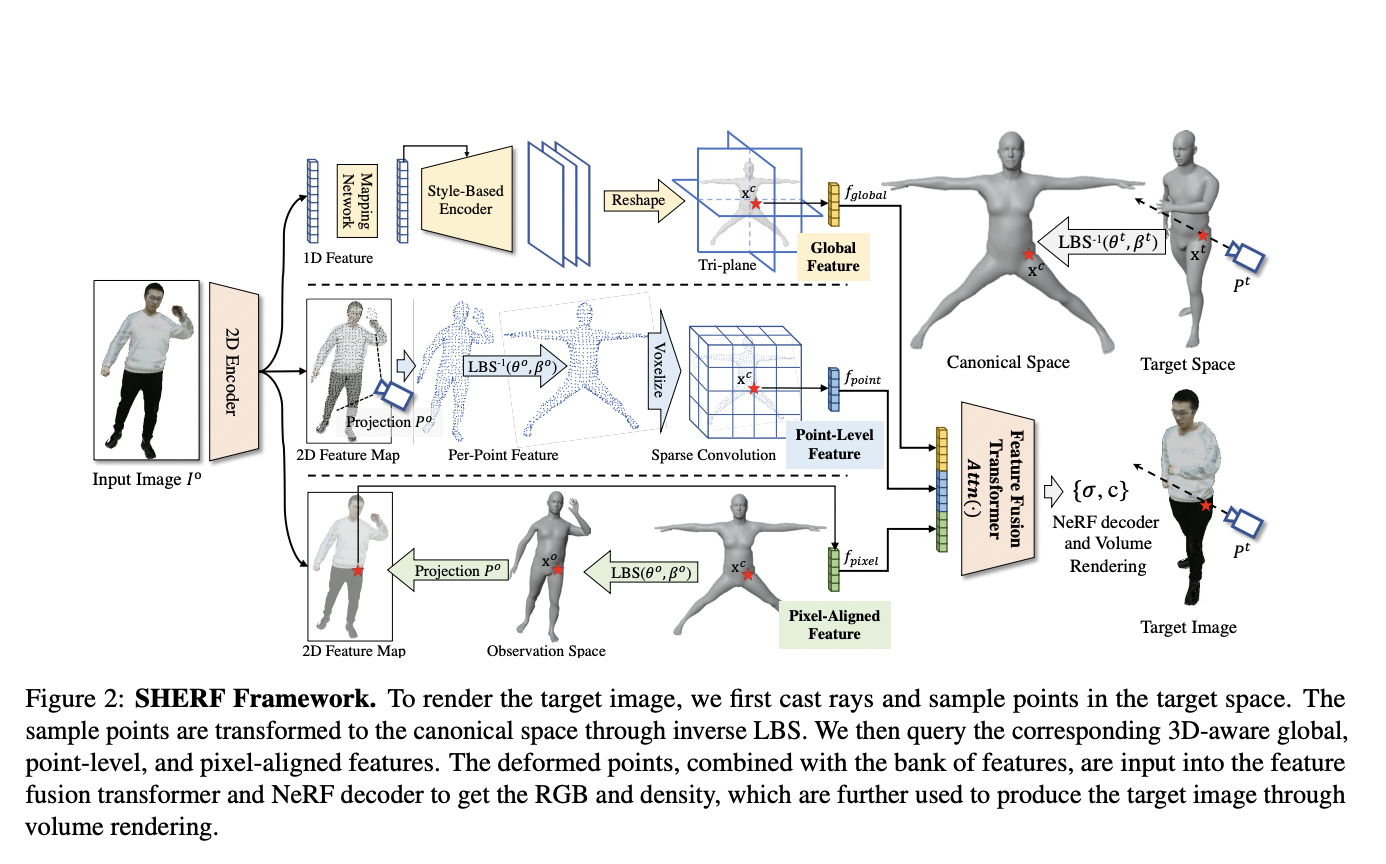
SHERF operates in a canonical space, and it can render and animate the reconstructed models from any free views and poses by producing 3D human representations in a standardized reference frame. This contrasts with conventional techniques, which mainly rely on fixed camera angles. The encoded 3D human representations include both detailed local textures and global appearance information for the successful and high-quality synthesis of viewpoints and positions. This is accomplished by using the concept of a bank of 3D-aware hierarchical features, which has a variety of features that are intended to make thorough encoding easier.
The team has mentioned the three levels of the hierarchical features, which are global, point-level, and pixel-aligned. Each of these traits has a distinct function, and the information acquired from the single input image is intended to be improved by global features, which try to close any gaps left by the incomplete 2D observation. While pixel-aligned features are responsible for preserving the smaller details that contribute to the overall correctness and realism of the model, point-level features provide significant signals of the underlying 3D human anatomy.
The team has developed a device called a feature fusion transformer to efficiently combine these 3D-aware hierarchical features, and this transformer is made to combine and utilize the many hierarchical feature types, ensuring that the encoded representations are as comprehensive and informative as possible. Comprehensive testing on multiple datasets, including THuman, RenderPeople, ZJU_MoCap, and HuMMan, has been used to demonstrate the efficacy of SHERF. The findings showed that SHERF performs above the present state-of-the-art levels, showing higher generalizability for combining unique views and positions.
The primary contributions have been summarized by the team as follows –
- SHERF has been introduced, which is the pioneering generalizable Human NeRF model that recovers animatedly 3D human models from just one image.
- It extends Human NeRF’s applicability to real-world scenarios by adapting to a broader context.
- SHERF employs 3D-aware hierarchical features, capturing fine-grained and global attributes. This enables the recovery of detailed textures and fills gaps in information from incomplete observations.
- SHERF excels by outperforming previous generalizable Human NeRF methods, and it has achieved superior results in both views and pose synthesis across extensive datasets.
In conclusion, this amazing research has definitely represented a huge step forward in the field of 3D human reconstruction, especially in real-world situations where obtaining photos from random camera angles presents specific difficulties.
Check out the Paper, Project, and GitHub. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.