Researchers from NVIDIA Introduce Retro 48B: The Largest LLM Pretrained with Retrieval before Instruction Tuning
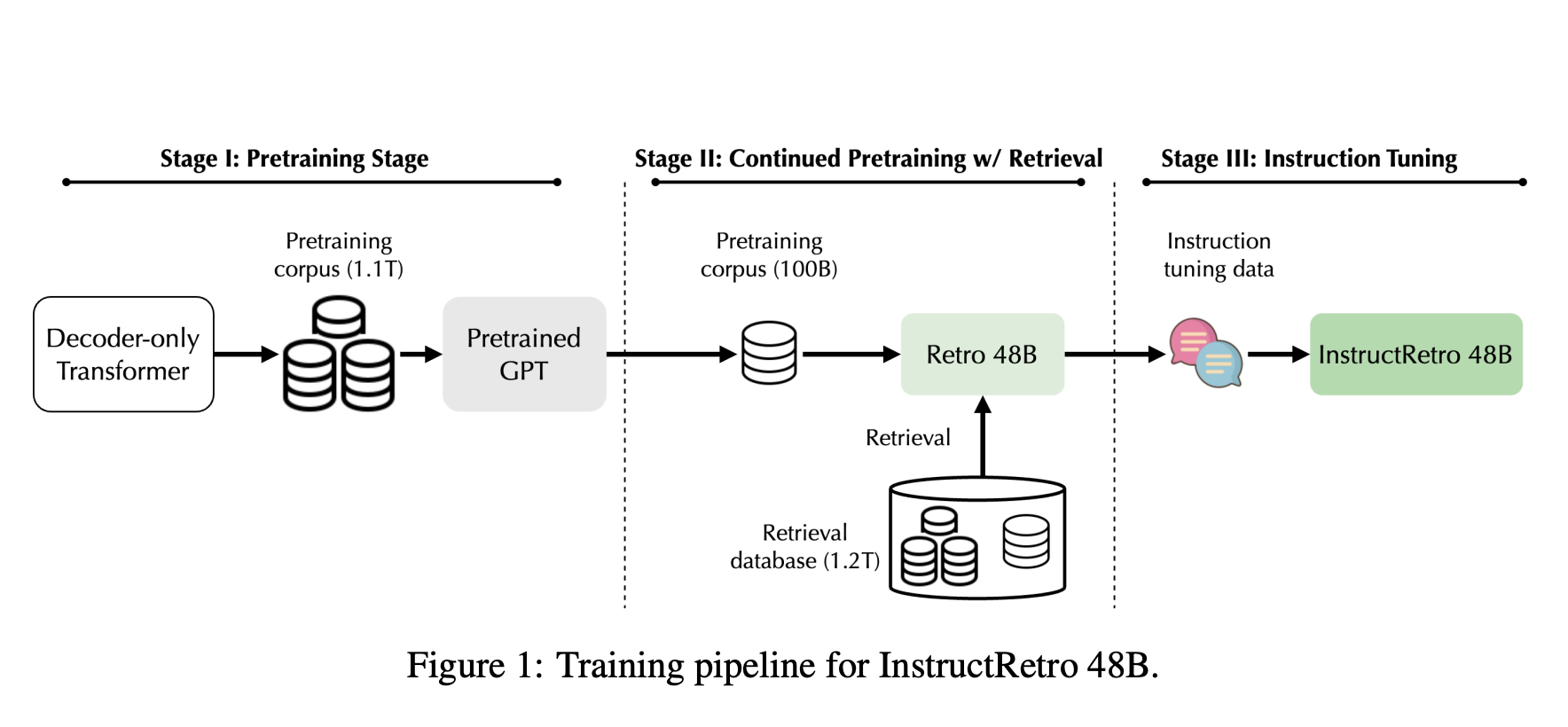
Researchers from Nvidia and the University of Illinois at Urbana Champaign introduce Retro 48B, a significantly larger language model than previous retrieval-augmented models like Retro (7.5B parameters). Retro 48B is pre-trained with retrieval on an extensive corpus, leading to improved perplexity. The encoder in InstructRetro can be ablated, suggesting that continued retrieval-augmented pre-training enhances the decoder’s performance in question answering.
Retrieval-augmented language models are well-established for open-domain question answering, benefiting both during pre-training and inference. Their approach reduces model perplexity, improves factuality, and enhances task performance post-fine-tuning. Existing retrieval-augmented models are constrained in size compared to decoder-only models, limiting their zero-shot generalization potential after instruction tuning. Instruction tuning, vital for natural language understanding, has gained support from high-quality datasets like FLAN, OpenAssistant, and Dolly, enabling superior performance in chat and question-answering tasks.
Pretraining language models with retrieval, such as Retro, has shown promise in reducing perplexity and enhancing factual accuracy. However, existing retrieval-augmented models need more parameters and training data, impacting their performance in instruction tuning and other tasks typical of large language models. Their study introduces Retro 48B, the largest retrieval-augmented model, continuing to pretrain a 43B GPT model with additional tokens. InstructRetro, obtained from this process, significantly improves zero-shot question answering compared to traditional GPT models. InstructRetro’s decoder achieves similar results when the encoder is ablated, demonstrating the retrieval-augmented pre-training’s effectiveness in context incorporation for question answering.
Their study explores an extensive process involving pretraining a GPT model to create Retro 48B, instructing it to enhance its zero-shot question-answering abilities, and evaluating its performance in various tasks. It introduces a novel 48B-sized retrieval-augmented language model, InstructRetro, which significantly outperforms the standard GPT model in zero-shot question-answering tasks after instruction tuning. This scaling-up approach demonstrates the potential of larger retrieval-augmented models in natural language understanding.
Retro 48B, a language model pre-trained with retrieval, surpasses the original GPT model in perplexity. After instruction tuning, referred to as InstructRetro, it significantly enhances zero-shot question answering, with an average improvement of 7% on short-form and 10% on long-form QA tasks compared to its GPT counterpart. Surprisingly, InstructRetro’s decoder backbone alone delivers comparable results, indicating the effectiveness of retrieval-based pretraining in context incorporation for QA.
Introducing InstructRetro 48B, the largest retrieval-augmented language model, significantly enhances zero-shot accuracy in a wide range of open-ended QA tasks compared to its GPT counterpart. Pretraining with retrieval using the Retro augmentation method improved perplexity. Their study’s results suggest that continued pre-training with recovery before instruction tuning offers a promising direction for enhancing GPT decoders in QA. Surprisingly, the decoder achieves comparable accuracy, showcasing the effectiveness of pretraining for context incorporation. InstructRetro excels in long-form QA tasks, highlighting retrieval-augmented pretraining’s potential for challenging tasks.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.