Researchers from NYU and Meta AI Studies Improving Social Conversational Agents by Learning from Natural Dialogue between Users and a Deployed Model, without Extra Annotations
Human input is a key tactic for improving social dialogue models. In reinforcement learning with human feedback, when many human annotations are required to guarantee a satisfactory reward function, there has been tremendous improvement in learning from feedback. The sources of feedback include numerical scores, rankings, or comments in natural language from users about a dialogue turn or dialogue episode, as well as binary assessments of a bot turn. Most works deliberately gather these signals utilizing crowdworkers since natural users might want to avoid being bothered with doing so or could offer inaccurate information if they do.
In this study, researchers from New York University and Meta AI consider the situation where they have a lot of deployment-time dialogue episodes that feature real discussions between the model and organic users. They are trying to determine whether they can glean any implicit indications from these natural user discussions and utilize those signals to enhance the dialogue model. There are two reasons for this. First, although they might not contribute explicit annotations, organic users most nearly approximate the data distribution for future deployment. Second, using implicit signals from previous episodes of dialogue saves money that would have been spent on crowdsourcing.
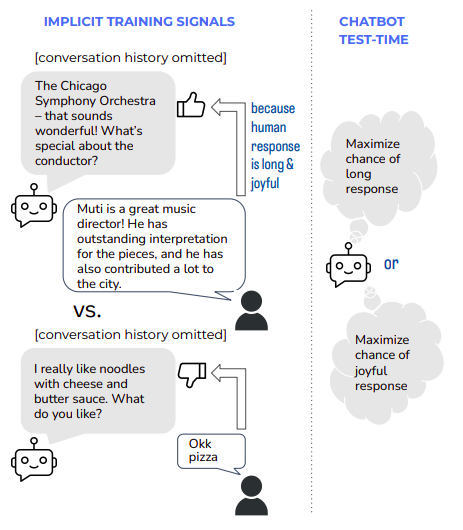
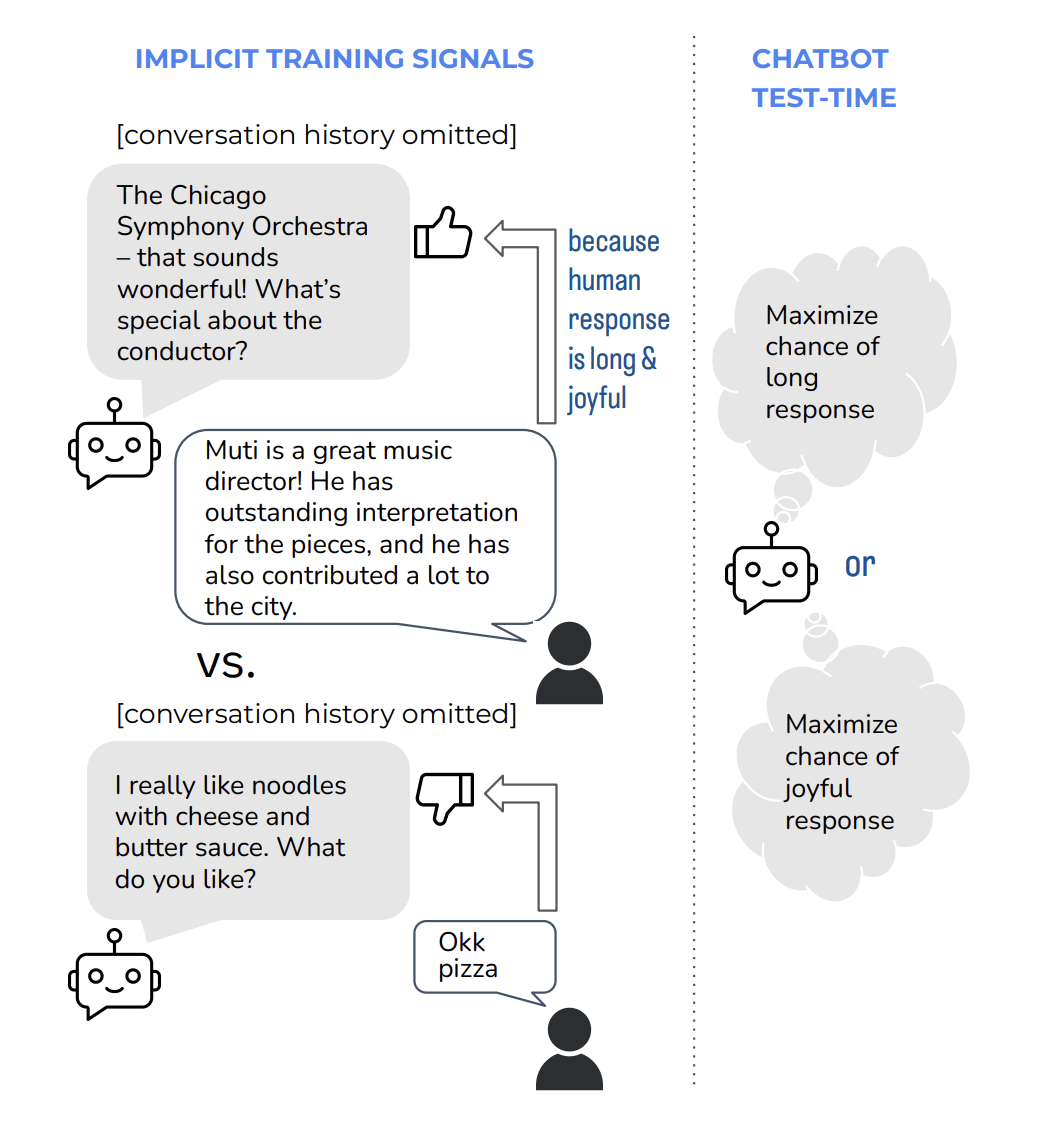
More precisely, they examine whether they can adjust the chatbot to use the best implicit feedback signals like the quantity, length, sentiment, or responsiveness of upcoming human answers. They use publicly available, de-identified data from the BlenderBot online deployment to investigate this problem. Using this data, they train sample and rerank models, comparing various implicit feedback signals. Their novel models are discovered to be superior to the baseline replies through both automated and human judgments. Furthermore, they inquire whether supporting these measures will result in unwanted behaviors, given that their implicit feedback signals are rough proxy indicators of the caliber of both generations.
Yes, depending on the signal used. In particular, optimizing for longer discussion lengths might cause the model to offer contentious opinions or reply in a hostile or combative manner. On the other hand, optimizing for a favorable response or mood reduces these behaviors relative to the baseline. They conclude that implicit feedback from humans is a helpful training signal that can enhance overall performance, but the specific movement employed has significant behavioral repercussions.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.