Researchers From Oxford Open-Source WhisperX: A Time-Accurate Speech Recognition System With Word-Level Timestamps
Weakly supervised and unsupervised training approaches have shown outstanding performance on various audio processing tasks, including voice recognition, speaker recognition, speech separation, and keyword spotting, thanks to the availability of large-scale online datasets. Researchers at Oxford developed a speech recognition system called Whisper that makes use of this extensive database on a larger scale. Utilizing 125,000 hours of English translation data and 680,000 hours of noisy speech training data in 96 additional languages, they demonstrate how weakly supervised pretraining of a straightforward encoder-decoder transformer can successfully achieve zero-shot multilingual speech transcription on established benchmarks.
Most academic benchmarks are made up of brief utterances, but in real-world applications, such as meetings, podcasts, and videos, transcription of long-form audio that might last for hours or minutes is usually required. Due to memory limitations, the transformer designs used for automatic speech recognition (ASR) models prevent transcription of arbitrarily lengthy input audio (up to 30 seconds in the case of Whisper). Recent research uses heuristic sliding-window style approaches, which are prone to errors because of I overlapping audio, which can cause inconsistent transcriptions when the model processes the same speech twice; and (ii) incomplete audio, where some words may be missed or incorrectly transcribed if they are at the beginning or end of the input segment.
Whisper suggests a buffered transcription method that depends on precise timestamp prediction to establish how much the input window should be shifted. As timestamp errors in one window might add to errors in successive windows, such a solution is vulnerable to significant drifting. They try to eliminate these mistakes using a variety of hand-made heuristics, but their efforts often fail to be successful. Whisper’s linked decoding, which utilizes a single encoder-decoder to decode transcriptions and timestamps, is susceptible to the standard issues with auto-regressive language production, specifically hallucination, and repetition. This disastrously affects buffered transcription of long-form and other timestamp-sensitive activities like speaker diarization, lip-reading, and audiovisual learning.
According to the Whisper paper, a significant chunk of the training corpus comprises incomplete data (audio-transcription pairings without timestamp information), represented by the token |nottimestamps|>. When scaling on incomplete and noisy transcription data, speech transcription performance is inadvertently traded for less precise timestamp prediction. As a result, employing extra modules, the transcript, and speech must be precisely aligned. There is a tonne of effort on “forced alignment,” which aligns speech transcription with audio waveforms at the word- or phoneme-level. The acoustic phone models are often trained to utilize the Hidden Markov Model (HMM) framework and the by-product of potential state alignments.
The timestamps for these words or phone numbers are often corrected using external boundary correction models. A few recent studies use deep learning tactics for forced alignment, such as employing a bi-directional attention matrix or CTC segmentation with the end-to-end trained model due to the rapid growth of deep learning-based approaches. Combining a cutting-edge ASR model with a simple phoneme recognition model, both of which were prepared using significant large-scale datasets, might result in further improvement.
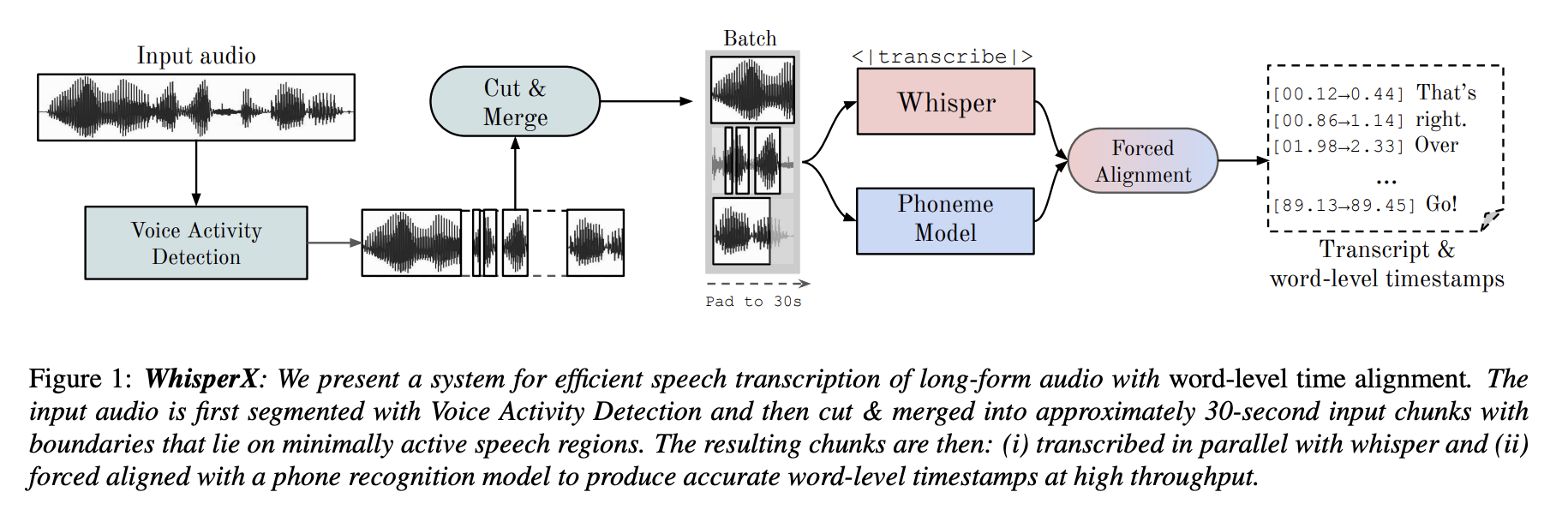
To overcome these difficulties, they suggest WhisperX, a method for effective voice transcription of long-form audio with precise word-level timestamps. It includes three additional steps in addition to whispering transcription:
- Pre-segmenting the input audio with an external Voice Activity Detection (VAD) model.
- Cutting and merging the resulting VAD segments into roughly 30-second input chunks with boundaries on minimally active speech regions.
- They force alignment with an external phoneme model to provide precise word-level timestamps.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.