Researchers From POSTECH And NVIDIA Created Two Large-Scale Implicit Datasets, Namely PeRFception-CO3D and PeRFception-ScanNet, That Cover Object-Centric And Scene-Centric Environments
In recent years, advances in implicit representations have shown tremendous accuracy, variety, and resilience in expressing 3D scenes by mapping low dimensional coordinates to local scene attributes such as occupancy, signed distance fields, or radiance fields. They have various advantages that explicit representations (such as voxels, meshes, and point clouds) cannot: smoother geometry, less memory space for storage, and unique view synthesis with high visual accuracy, to mention a few. Implicit representations have therefore been employed for 3D reconstruction, unique view synthesis, position estimation, picture production, and many more applications.
Neural Radiance Fields (NeRF) and several follow-up studies have demonstrated that implicit networks can create photorealistic pictures and capture precise geometry by converting a static scene into an implicit 5D function that produces view-dependent radiance fields. They employ view-dependent radiance that may be encoded into an implicit network using picture supervisions, differentiable volumetric rendering, and scene geometry. In contrast to traditional explicit 3D representations, these components enable the networks to record high-fidelity photometric properties such as reflection and refraction.
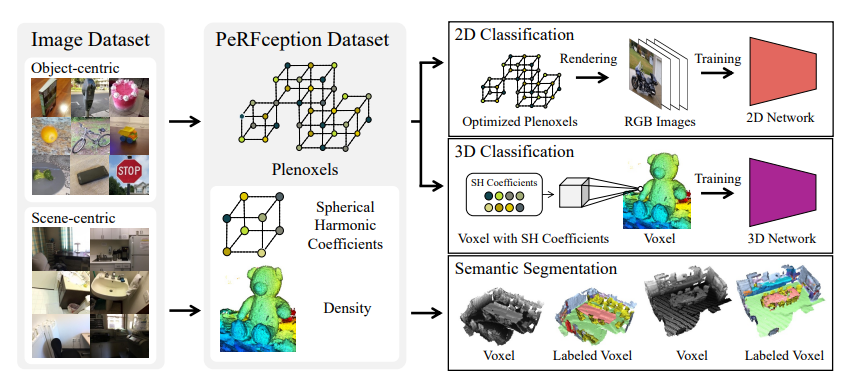
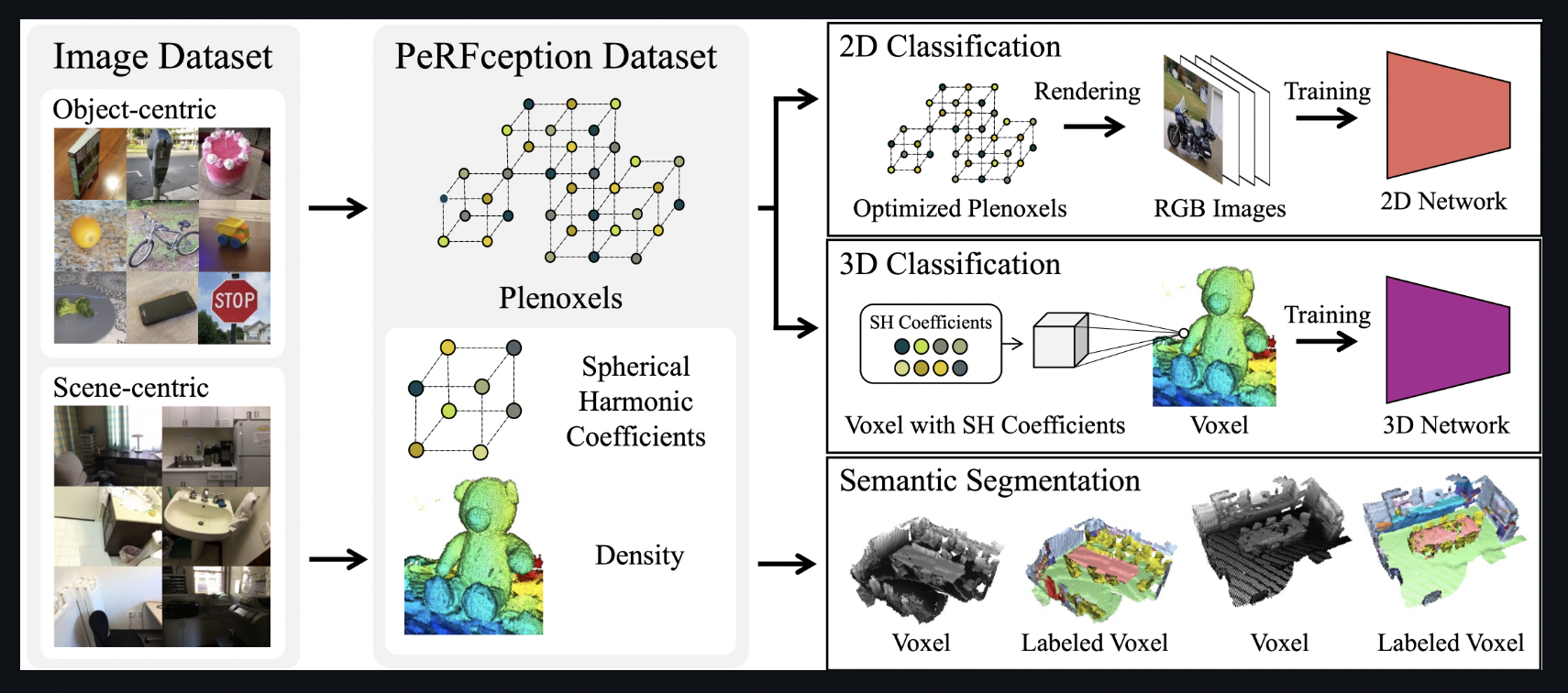
The PeRFception dataset conveys both visual (spherical harmonic coefficient) and geometric (density, sparse voxel grid) characteristics in a single compact format, allowing it to be applied to a wide range of perception challenges such as 2D classification, 3D segmentation, and 3D classification right away.
Given the effectiveness of implicit representations, it is only logical to view them as one of the standard data formats for 3D and perception. Despite their ability to record a picture with excellent fidelity, these innovative representations have yet to be applied for perception tasks such as categorization and segmentation. The lack of a substantial dataset suited for developing a perception system is one of the main contributing factors. As a result, in this paper, They publish the first large-scale implicit representation datasets to help speed up perception research.
NeRFs have flaws that impede their widespread use as the preferred data format for 3D sceneries and perception. First, it takes many days to train an implicit network. NeRFs cannot be used in real-time applications because of the delay in inference (volumetric rendering), which can last several minutes. A scene’s geometry and visual characteristics are implicitly recorded as weights in a neural network. These facts prohibit the information from being processed immediately by an already-existing perception pipeline. Third, implicit weights or features are unique to a scene and are not reusable between scenes.
However, channels or characteristics, such as RGB channels for visuals, must have a consistent structure for perception. For example, if the order of channels varies from picture to image, the image classification pipeline will not function effectively. Recent research has overcome these constraints by employing precise sparse voxel grid geometry and feature-based functions. Numerous publications recommend using explicit sparse voxel geometry to address the sluggish speed, which minimizes the number of samples along a ray by avoiding unoccupied space.
Second, explicitly optimizing features given to specific geometry speeds up the process of extracting features from networks rather than utilizing implicit representations of weights. Last but not least, Yu et al. demonstrate that spherical harmonic coefficients may describe a scene as precisely as NeRFs while keeping consistent and organized characteristics, which is essential for perception or generating a scene with varied items in NeRF format. Their study uses Plenoxels as the primary format for perception challenges and designs both scene- and object-centric settings. Plenoxels, in particular, meet all requirements for data representation, supporting quick learning and rendering while keeping a consistent feature representation for perception and scene composition.
They primarily transform two picture datasets, the Common Object 3D dataset (CO3D) and ScanNet, into Plenoxels and label the converted datasets PeRFception-CO3D and PeRFception-ScanNet, respectively. They train networks for 2D image classification, 3D object classification, and 3D semantic segmentation using the PeRFception datasets. Because Plenoxels can be exceedingly significant, They offer a few strategies for compressing data and hyperparameters for each configuration to improve accuracy while lowering data size.
Their ability to successfully train networks for each perceptual challenge shows that their datasets can properly combine 2D and 3D information into a single format. They also demonstrate how their representation enables complex camera-level manipulation and more practical backdrop augmentation. They offer the following summary of their contributions:
• They present the first large-scale implicit datasets suitable for downstream perception tasks like 2D image classification, 3D object classification, and 3D scene semantic segmentation.
• They carry out the first in-depth investigation of visual perception tests that consciously use implicit representation. Their datasets successfully transmit the information for 2D and 3D perception tasks, according to the thorough trials.
• They provide a ready-to-use pipeline that uses entirely automated procedures to produce implicit datasets. In the future, They anticipate that this automated procedure will enable the creation of a very sizable 3D dataset.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'PeRFception: Perception using Radiance Fields'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, project page and code. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.