Researchers from Sea AI Lab and National University of Singapore Introduce ‘PoolFormer’: A Derived Model from MetaFormer for Computer Vision Tasks

The main hype of the last few years in the world of Deep Learning is definitely Transformers. Since their advent in 2017 with the super-cited paper Attention Is All You Need, many researchers have struggled to improve and apply them in every possible domain. While originally born for NLP, the interest in Transformers applied to vision is growing exponentially, and, since the introduction of ViT, many research groups have proposed different variants of its architecture.
The ViT encoder has two main components: the first is the famous attention-based one which deals with mixing the information of the input tokens; the second contains the MLP with a typical expansion-compression structure. Historically, the attention module has always been considered the core of the Transformer’s ability. For this reason, most researchers have focused on how to improve the attention module. Nevertheless, recent works have demonstrated the capability of MLP as well to achieve comparable results. This aspect has raised the doubt that the self-attention module is not all we need.
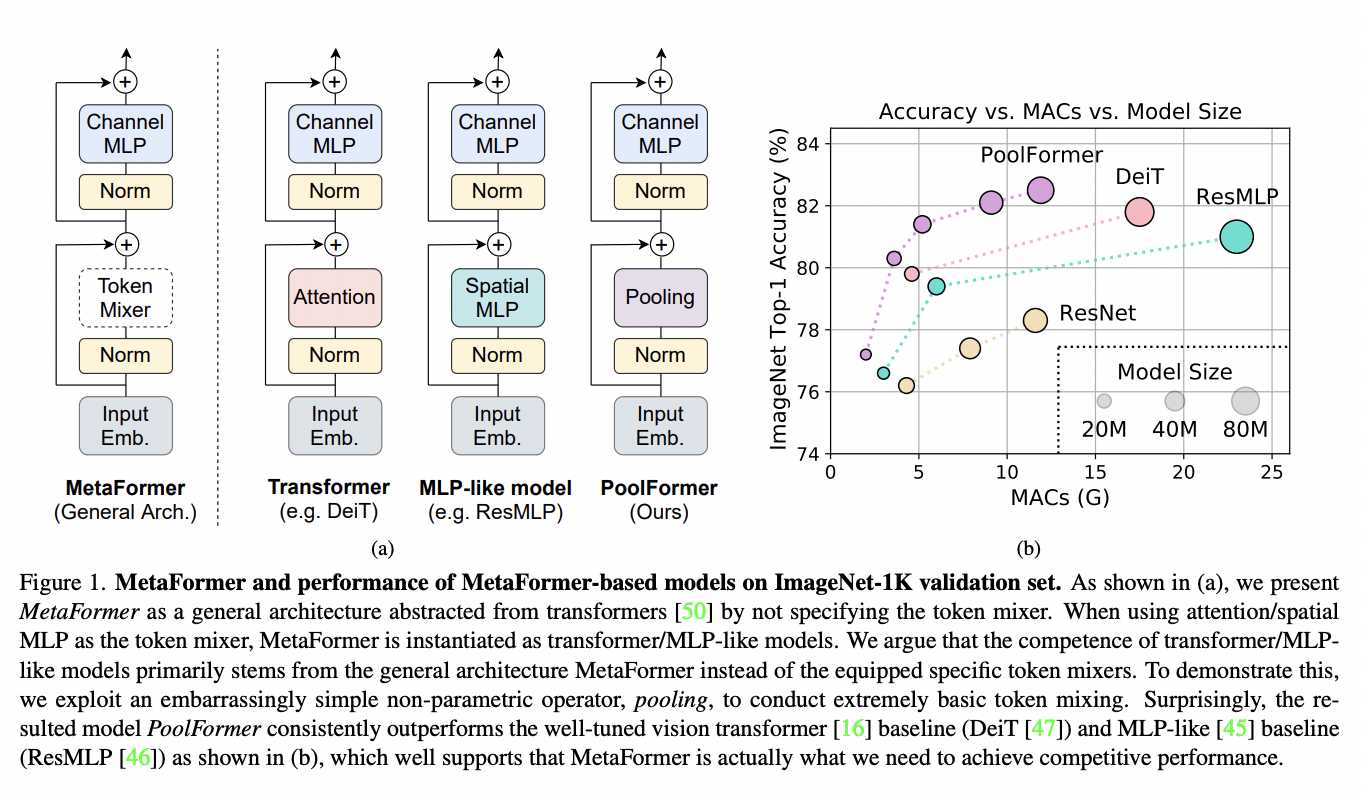
The Sea AI Lab together with the National University of Singapore followed this intuition to define MetaFormer. They hypothesized that the general Transformer architecture is more fundamental compared to the specific attention module. To demonstrate this, they replaced the attention module with an “embarrassingly simple” and non-parametric spatial average pooling layer and yet achieved competitive results on different computer vision tasks, such as image classification, object detection, instance segmentation, and semantic segmentation. This model was named PoolFormer and was compared with classic Transformer (e.g. DeiT) and MLP-like (e.g. ResMLP) models, in terms of performance, the number of parameters, and MACs (Multiply And Accumulate).

In this architecture, the input is first processed by a patch embedding, similar to the original ViT implementation, enforced by n=C1 convolution filters with a 7×7 window and a stride value of 4, which produce a tensor of dimension C1 x H/4 x W/4. Then the output is passed to a series of PoolFormer blocks. In the PoolFormer, the attention module is substituted with a pooling block with stride=1 which performs average pooling (simply makes each token averagely aggregate to its nearby token features). After the skip connection, the second block consists of a two-layered MLP as in the original Transformer encoder.
The whole procedure is repeated to build a hierarchical structure with 4 stages, compressing the original height and width of the image to H/32 and W/32 through pooling. Two different types of configurations were defined, depending on the embedding size (small-sized or medium-size), i.e., on the four embedding dimensions (C1, C2, C3, C4). To better understand the above image, assuming there are L=12 PoolFormer blocks in total, stages 1, 2, and 4 will contain L/6=2 PoolFormer block, while stage 3 will contain L/2=6 of them. After an ablation study, the authors decided to utilize Group Normalization as normalization technique and GeLu as activation function.
The results with this very simple implementation are surprising. For the image classification task, tested on the ImageNet-1K dataset, PoolFormer achieved 82.1% top-1 accuracy, surpassing classic Transformer implementations, in particular, DeiT by 0.3% with 35% fewer parameters and fewer 48% MACs, and MLP-like implementations, such as ResMLP, by 1.1% with 52% fewer parameters and 60% fewer MACs. Similar performance was shown in object detection, instance segmentation, and semantic segmentation task.
In summary, the authors abstracted the overall Transformer architecture as a general MetaFormer where the token mixer is not specified. The core of this theory is that the token mixer is not essential to obtain acceptable performance, while the main power is in the general structure. To demonstrate this, they implemented a very simple token mixer based on non-parametric average pooling, which obtained comparable results with Transformer-based SOTA architectures.
The main purpose of this paper is to redirect the computer vision community to pay attention not solely to the token mixer but rather to the general MetaFormer architecture, to achieve higher and higher performance in different domains.
Paper: https://arxiv.org/abs/2111.11418v1
GitHub: https://github.com/sail-sg/poolformer
Suggested
Credit: Source link
Comments are closed.