Researchers from Sony Propose BigVSAN: Revolutionizing Audio Quality with Slicing Adversarial Networks in GAN-Based Vocoders
The development of neural networks and their constantly increasing popularity have led to substantial improvements in speech synthesis technologies. The majority of speech synthesis systems use a two-stage method: first, they predict an intermediate representation from the input text, like mel-spectrograms, and then they convert this intermediate representation into audio waveforms. The final step called a vocoder, is essential for producing audio from mel-spectrograms.
A lot of effort has been put into improving the caliber of speech synthesis produced by vocoders. Deep generative models, such as autoregressive models, generative adversarial network (GAN)-based models, flow-based models, and diffusion-based models, have shown promise in producing high-quality waveforms. While these deep generative models need help to achieve good sample quality, variety, and quick sampling all at once, vocoder diversity is less significant than it is for picture generation models. Vocoders are designed to produce audio that corresponds to a particular mel-spectrogram, and since GANs can quickly generate high-quality samples, they are a strong and useful tool.
The potential of generative adversarial networks (GANs) to effectively produce high-quality audio waveforms quicker than real-time has attracted much interest in the vocoders field. However, one issue with GAN-based vocoders is that they frequently have trouble determining the best feature space projection for differentiating between real and fake data, with which the overall quality of the audio that is created can be impacted.
To address these issues, a team of researchers from Sony AI, Tokyo, Japan, and Sony Group Corporation, Tokyo, Japan, has looked into an improved GAN training framework termed the Slicing Adversarial Network (SAN) in the context of picture generation tasks. Finding the optimum feature space projection for better discriminating between authentic and fraudulent data has been demonstrated to be successful with SAN. The team has examined if SAN can similarly improve the efficiency of GAN-based vocoders. To do this, they have suggested a modification approach for least-squares GAN, a popular GAN variant in vocoders. For the sake of SAN, this technique modifies the loss functions of least-squares GAN.
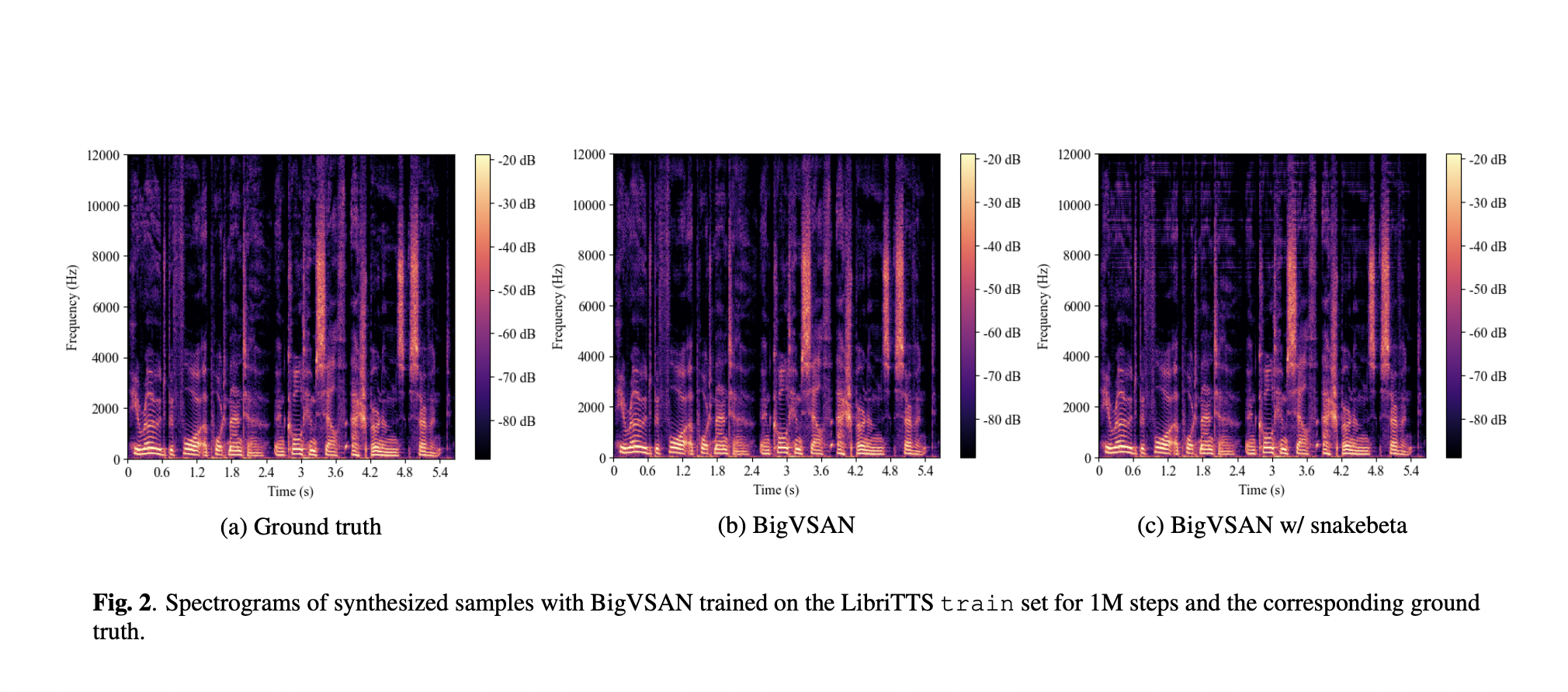
The team has shown through a series of tests that implementing the SAN framework with small tweaks can enhance the performance of GAN-based vocoders, including the well-known model known as BigVGAN. Their approach adds to the increasing corpus of research on improving audio waveform synthesis with GANs. The team has named the vocoder BigVSAN, which has been powered by SAN, i.e., the improved GAN training framework, and which has the ability to outperform the SOTA BigVGAN vocoder.
The team has summarized their key contributions as follows –
- Soft Monotonization Scheme: A method called “soft monotonization” has been introduced that adjusts least-squares GANs to become least-squares SANs, improving their feature space projections.
- Performance Enhancement: By implementing SAN and other modifications, the team has demonstrated that GAN-based vocoders, including the advanced BigVGAN, can produce better audio results.
- The team has made the code publicly available to support reproducibility. This enables other researchers to replicate the experiments and build upon existing work, thus fostering collaboration and advancement in audio synthesis technology.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.